损失函数用来评价模型预测值和真实值的不一样程度
两系损失函数:
绝对值loss
- $L(Y,f(x))=|Y-f(x)|$
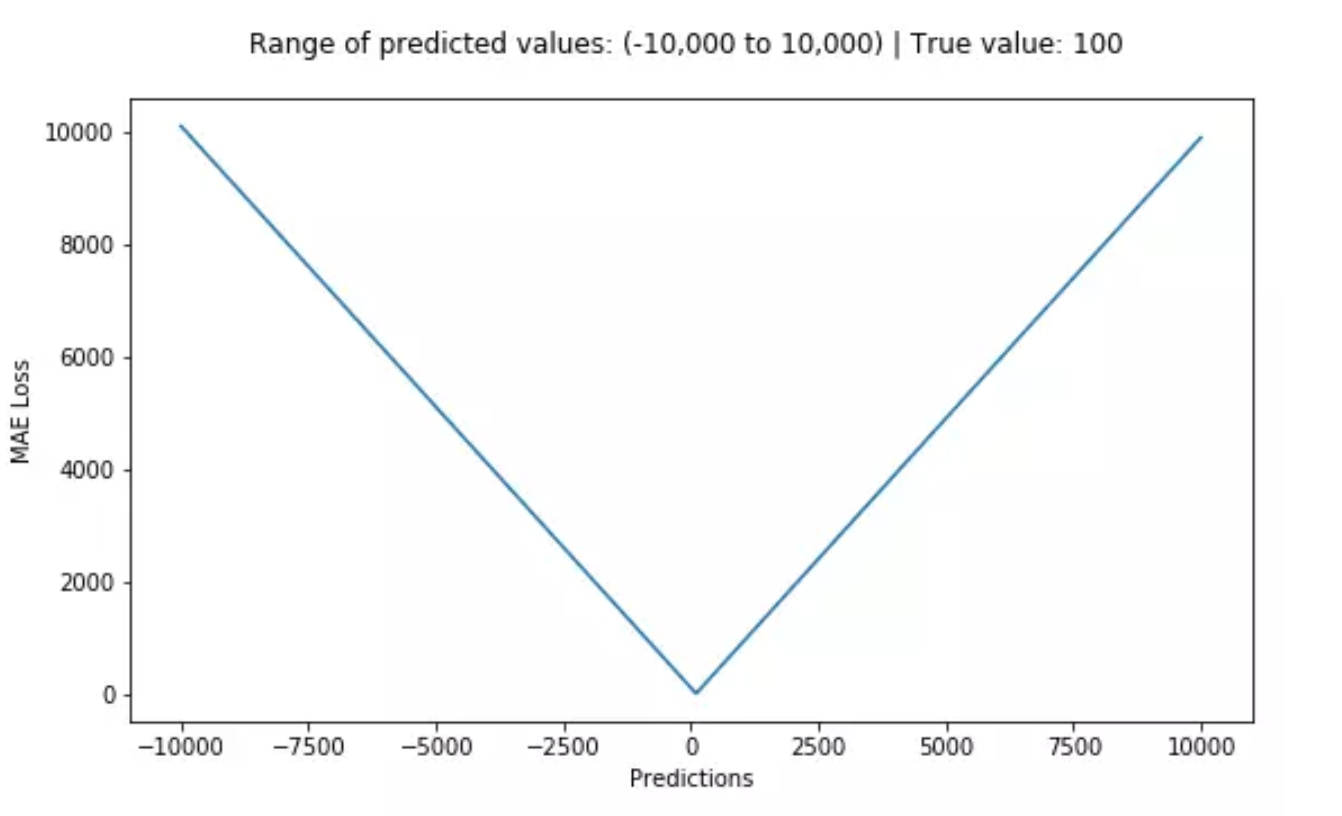
- 平均绝对值损失,MAE,L1
- 对异常点有更好的鲁棒性
- 更新的梯度始终相同,对于很小的损失值,梯度也很大,不利于模型学习——手动衰减学习率
平方差loss
- $L(Y, f(x)) = (Y-f(x))^2$
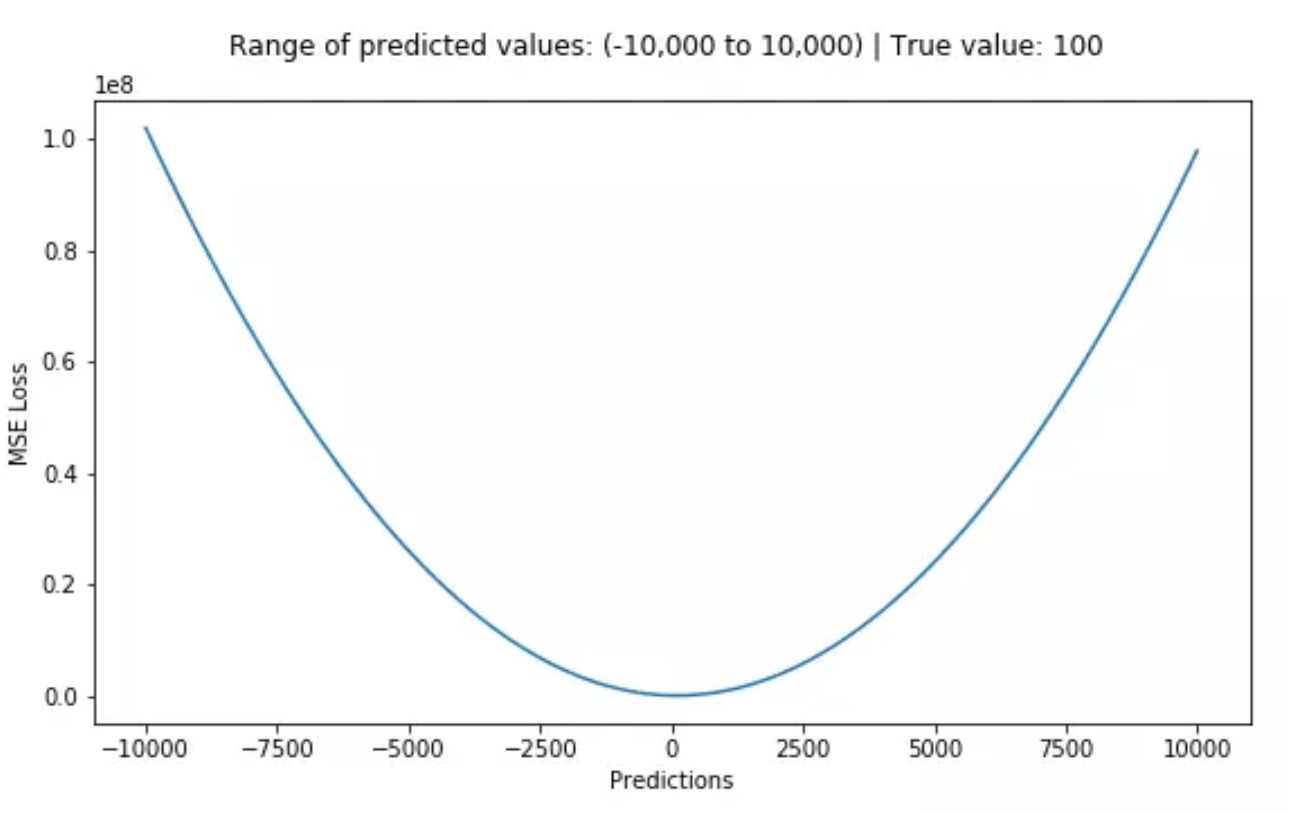
- 均方误差损失,MSE,L2
- 因为取了平方,会赋予异常点更大的权重,会以牺牲其他样本的误差为代价,朝着减小异常点误差的方向更新,降低模型的整体性能
Huber loss
- $L = \begin{cases} \frac{1}{2}(y-f(x))^2,\text{ for }|y-f(x)|<\delta,\\ \delta |y-f(x)|-\frac{1}{2}\delta^2, \text{ otherwise} \end{cases} $
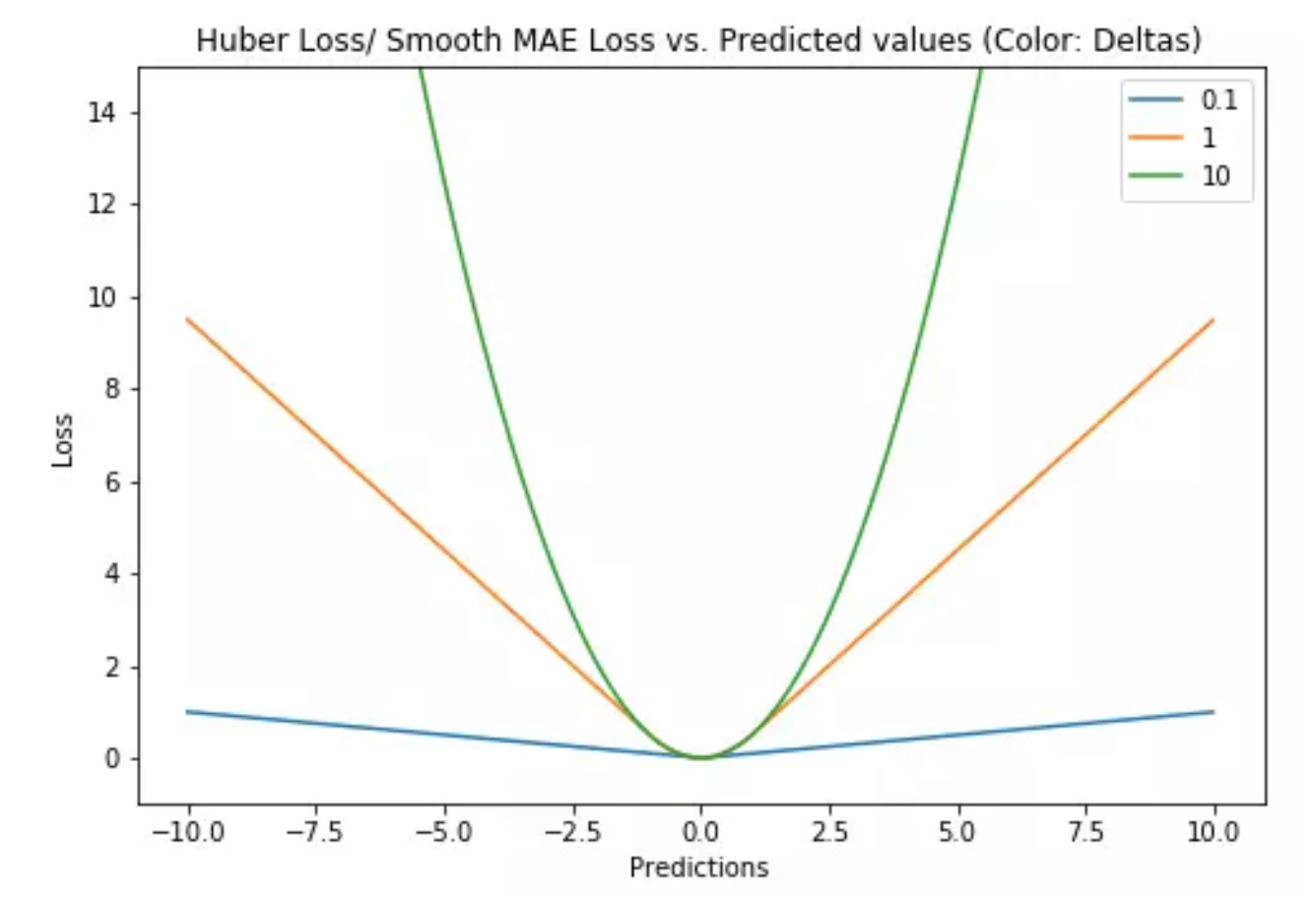
- 超参决定了对与异常点的定义,只对较小的异常值敏感
对数loss
cross-entropy loss
二分类双边计算:
多分类单边计算:
指数loss
Hinge loss
perceptron loss
cross-entropy loss
二分类双边计算:
多分类单边计算: