[3d resnet] Learning Spatio-Temporal Features with 3D Residual Networks for Action Recognition:真3d,for comparison,分类
[C3d] Learning Spatiotemporal Features with 3D Convolutional Networks:真3d,for comparison,分类
[Pseudo-3D resnet] Learning Spatio-Temporal Representation with Pseudo-3D Residual Networks:伪3d,resblock,S和T花式连接,分类
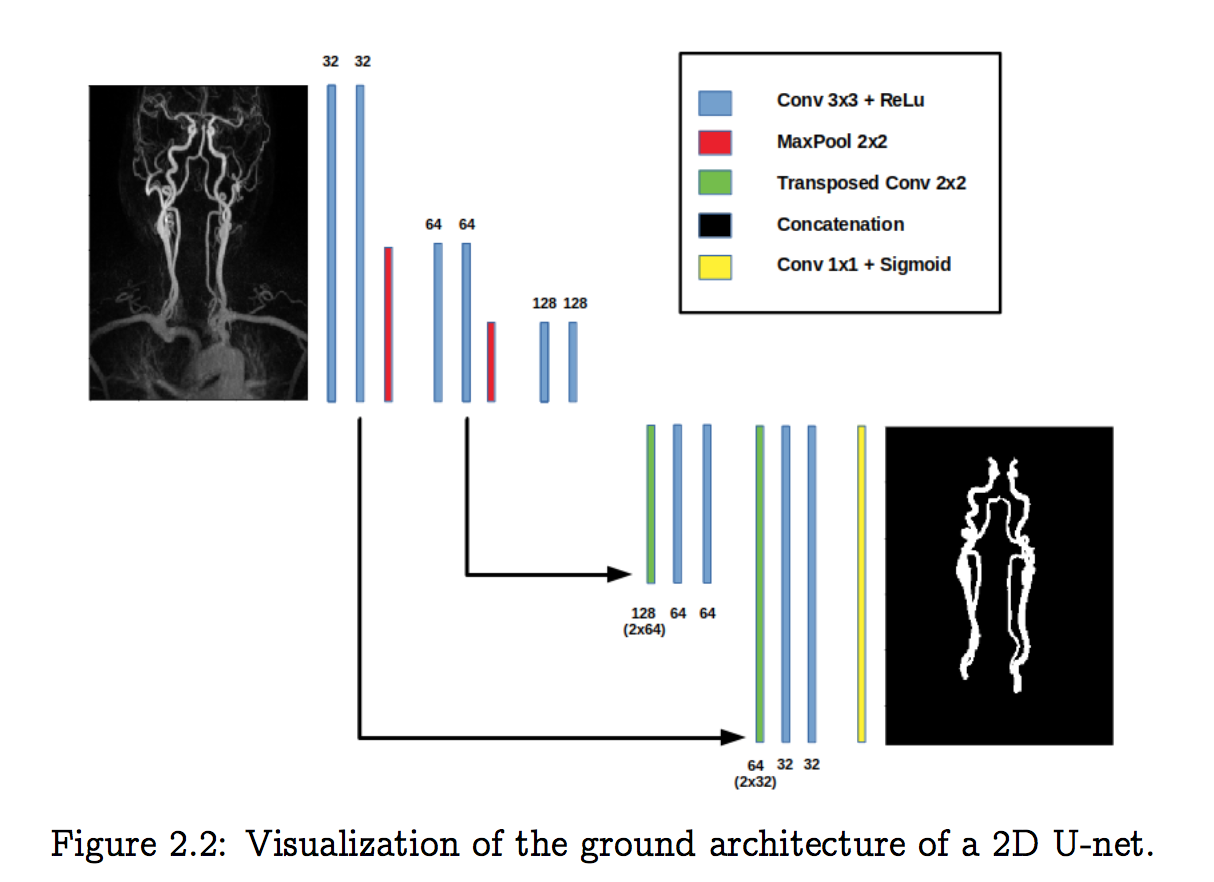
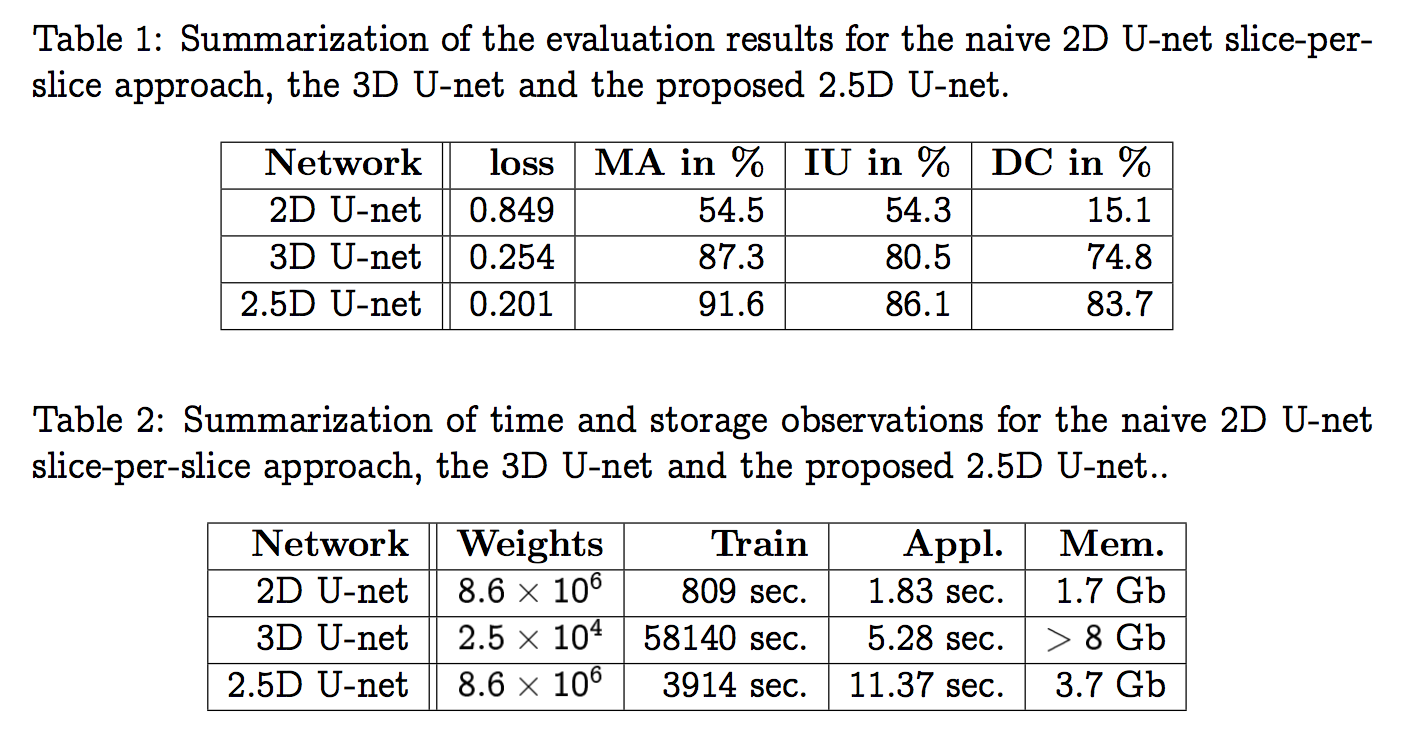
[2.5d Unet] Automatic Segmentation of Vestibular Schwannoma from T2-Weighted MRI by Deep Spatial Attention with Hardness-Weighted Loss:patch输入,先2d后3d,针对各向异性,分割
[two-pathway U-Net] Combining analysis of multi-parametric MR images into a convolutional neural network: Precise target delineation for vestibular schwannoma treatment planning:patch输入,3d网络,xy和z平面分别conv & concat,分割
[Projection-Based 2.5D U-net] Projection-Based 2.5D U-net Architecture for Fast Volumetric Segmentation:mip,2d网络,分割,重建
[New 2.5D Representation] A New 2.5D Representation for Lymph Node Detection using Random Sets of Deep Convolutional Neural Network Observations:横冠矢三个平面作为三个channel输入,2d网络,检测
Learning Spatio-Temporal Representation with Pseudo-3D Residual Networks
动机
- spatio-temporal video
- the development of a very deep 3D CNN from scratch results in expensive computational cost and memory demand
- new framework
- 1x3x3 & 3x1x1
- Pseudo-3D Residual Net which exploits all the variants of blocks
- outperforms 3D CNN and frame-based 2D CNN
论点
- 3d CNN的model size:making it extremely difficult to train a very deep model
- fine-tuning 2d 好于 train from scrach 3d
- RNN builds only the temporal connections on the high-level features,leaving the correlations in the low-level forms not fully exploited
- we propose
- 1x3x3 & 3x1x1 in parallel or cascaded
- 其中的3x3 conv可以用2d conv来初始化
- a family of bottleneck building blocks:enhance the structural diversity
方法
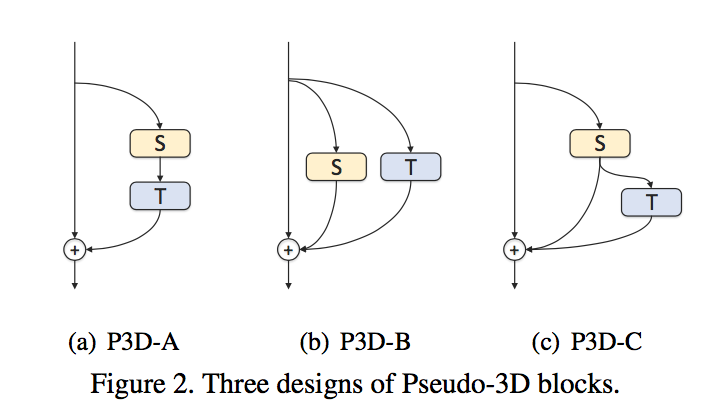
P3D Blocks
- direct/indirect influence:S和T之间是串联还是并联
direct/indirect connected to the final output:S和T的输出是否直接与identity path相加
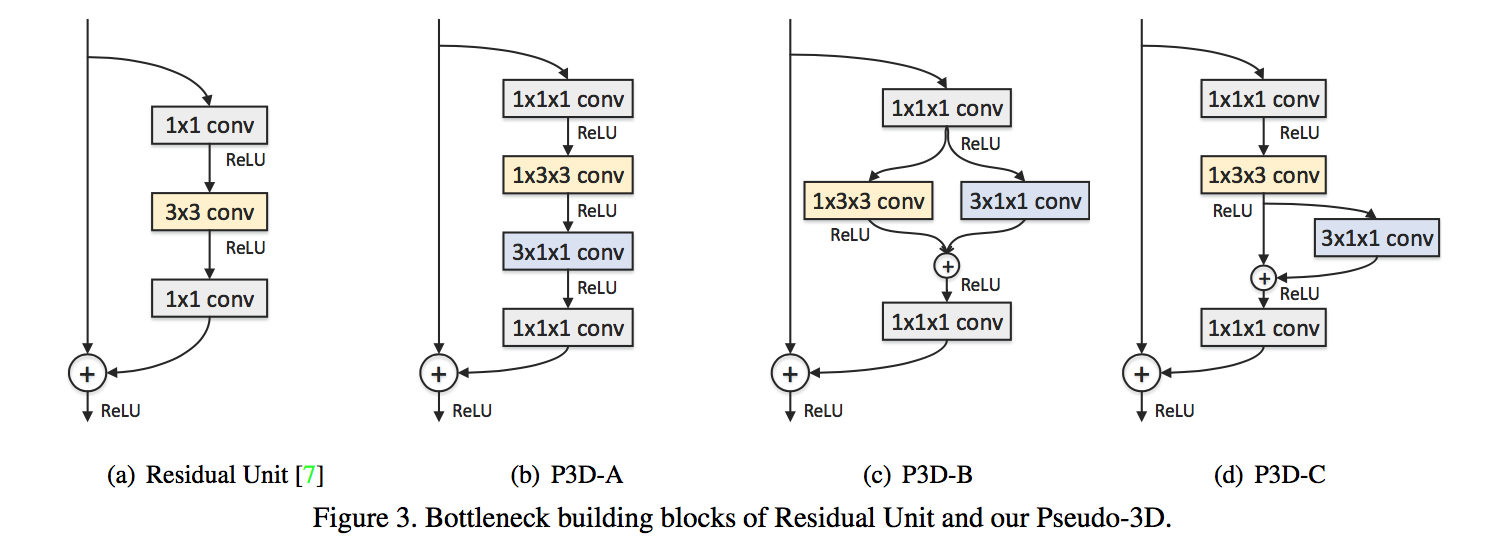
bottleneck:
- 头尾各接一个1x1x1的conv
- 头用来narrow channel,尾用来widen back
头有relu,尾没有relu
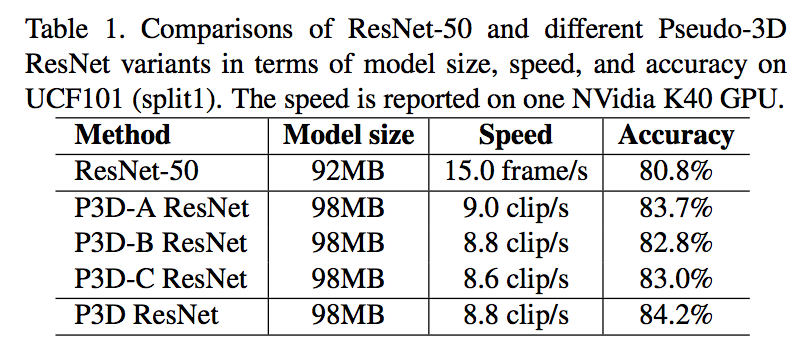
Pseudo-3D ResNet
- mixing blocks:循环ABC
better performance & small increase in model size
fine-tuning resnet50:
- randomly cropped 224x224
- freeze all BN except for the first one
- add an extra dropout layer with 0.9 dropout rate
- further fine-tuning P3D resnet:
- initialize with r50 in last step
- randomly cropped 16x160x160
- horizontally flipped
- mini-batch as 128 frames
future work
- attention mechanism will be incorporated
Projection-Based 2.5D U-net Architecture for Fast Volumetric Segmentation
动机
MIP:2D images containing information of the full 3D image
faster, less memory, accurate
方法
2d unet
- MIP:$\alpha=36$
- 3x3 conv, s2 pooling, transpose conv, concat, BN, relu,
- filters:begin with 32, end with 512
dropout:0.5 in the deepest convolutional block and 0.2 in the second deepest blocks
3d unet
- overfitting & memory space
- filters:begin with 4, end with 16
- dropout:0.5 in the deepest convolutional block and 0.4 in the second deepest blocks
Projection-Based 2.5D U-net
2d slice:loss of connection
2d mip:disappointing results
2d volume:long training time
the proposed 2.5D U-net:
$M_{i}$:MIP,p=12
$U$:2d-Unet like above
$F_p$:learnable filtration,1x3 conv,for each projection,抑制重建伪影
$R_p$:reconstruction operator
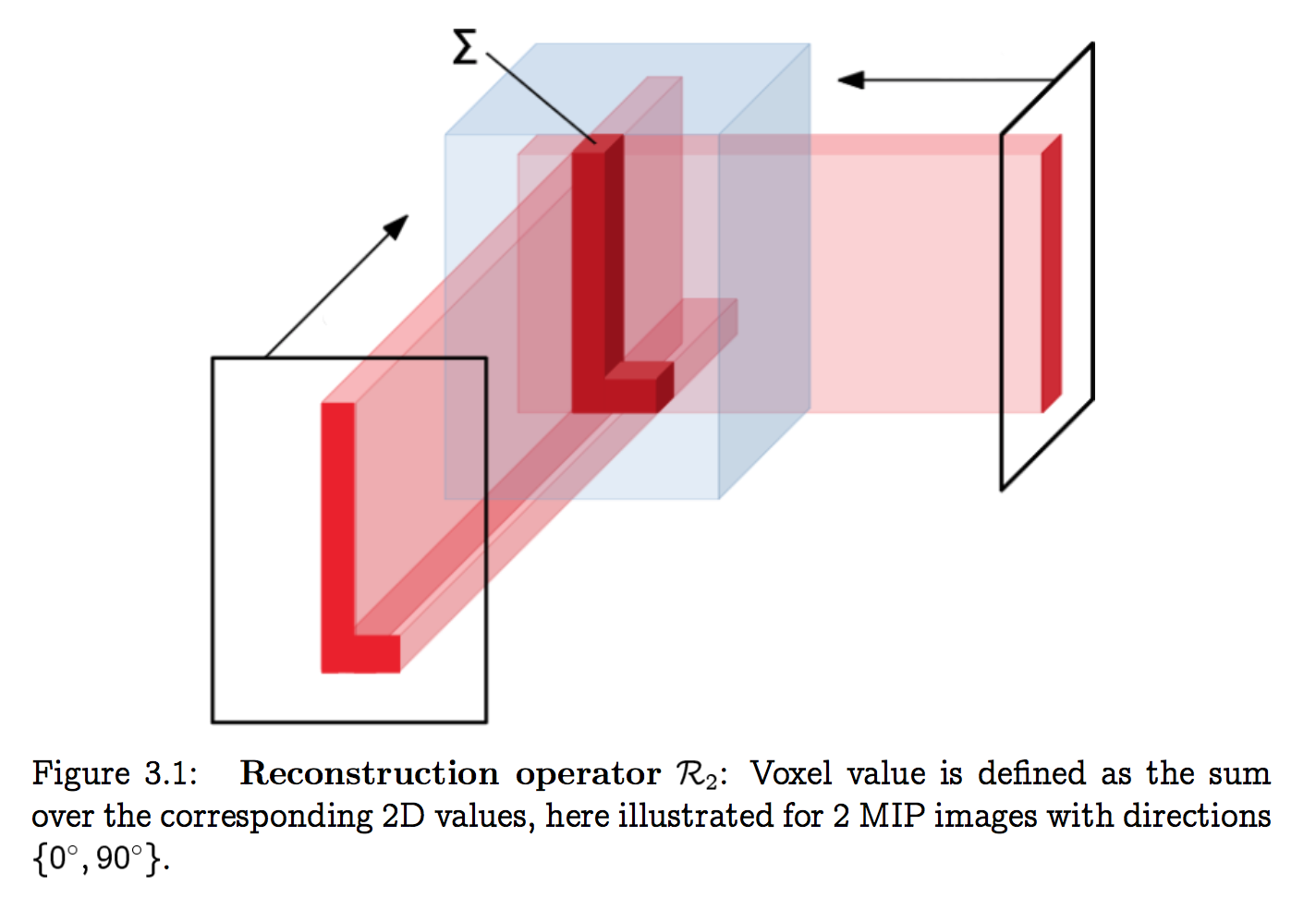
$T$:fine-tuning operator,shift & scale back to 0-1 mask
Learning Spatio-Temporal Features with 3D Residual Networks for Action Recognition
动机
- 3D kernels tend to overfit
- 3D CNNs is relatively shallow
- propose a 3D CNNs based on ResNets
- better performance
- not overfit
- deeper than C3D
论点
- two-stream architecture:consists of RGB and optical flow streams is often used to represent spatio-temporal information
- 3D CNNs:trained on relatively small video datasets performs worse than 2D CNNs pretrained on large datasets
- Very deep 3D CNNs:not explored yet due to training difficulty
方法
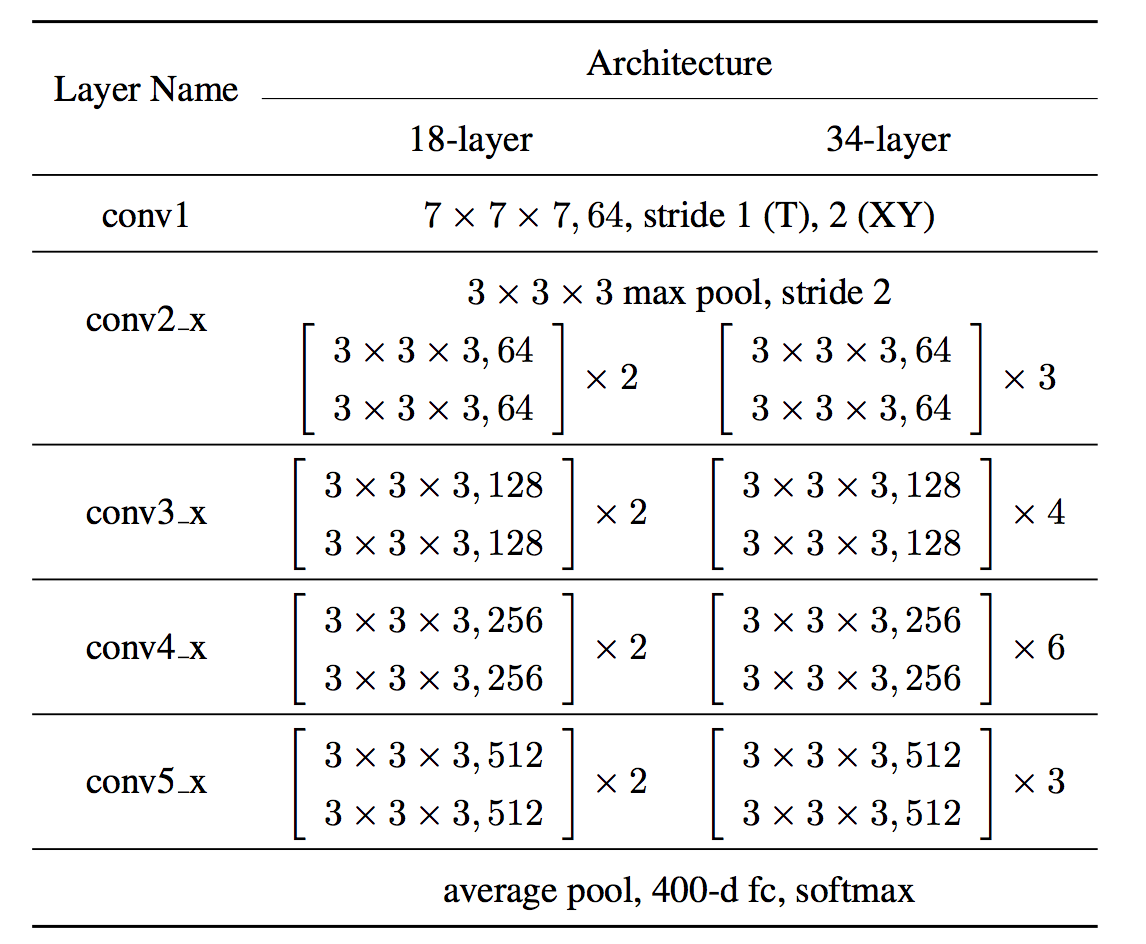
Network Architecture
- main difference:kernel dimensions
- stem:stride2 for S,stride1 for T
- resblock:conv_bn_relu&conv + id
- identity shortcuts:use zero-padding for increasing dimensions,to avoid increasing the number of parameters
- stride2 conv:conv3_1、 conv4_1、 conv5_1
- input clips:3x16x112x112
- large learning rate and batch size was important
实验
- 在小数据集上3d-r18不如C3D,overfit了:shallow architecture of the C3D and pretraining on the Sports-1M dataset prevent the C3D from overfitting
- 在大数据集上3d-r34好于C3D,同时C3D的val acc明显高于train acc——太shallow欠拟合了,r34则表现更好,而且不需要预训练
- RGB-I3D achieved the best performance
- 3d-r34是更deeper的
- RGB-I3D用了更大的batch size:Large batch size is important to train good models with batch normalization
- High resolutions:3x64x224x224
Learning Spatiotemporal Features with 3D Convolutional Networks
动机
- generic
- efficient
- simple
- 3d ConvNet with 3x3x3 conv & a simple linear classifier
论点
- 3D ConvNets are more suitable for spatiotemporal feature learning compared to 2D ConvNets
- 2D ConvNets lose temporal information of the input signal right after every convolution operation
2d conv在channel维度上权重都是一样的,相当于temporal dims上没有重要性特征提取

方法
basic network settings
- 5 conv layers + 5 pooling layers + 2 fc layers + softmax
- filters:[64,128,256,256,256]
- fc dims:[2048,2048]
- conv kernel:dx3x3
- pooling kernel:2x2x2,s2 except for the first layer
- with the intention of not to merge the temporal signal too early
- also to satisfy the clip length of 16 frames
varing settings
- temporal kernel depth
- homogeneous:depth-1/3/5/7 throughout
- varying:increasing-3-3-5-5-7 & decreasing-7- 5-5-3-3
depth-3 throughout performs the best
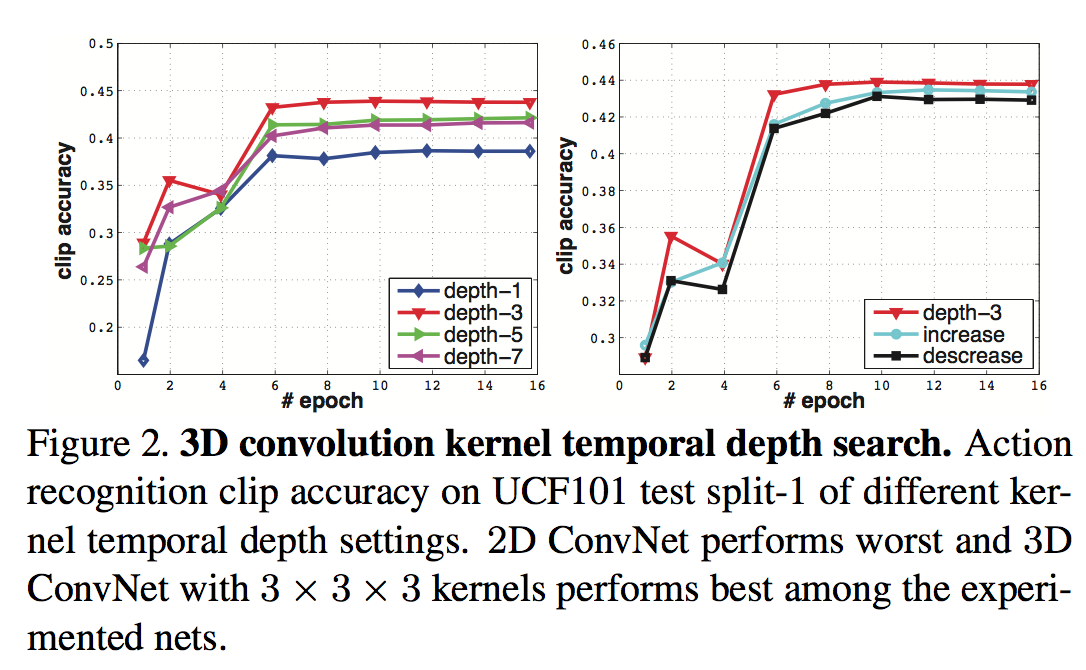
depth-1 is significantly worse
- We also verify that 3D ConvNet consistently performs better than 2D ConvNet on a large-scale internal dataset
- temporal kernel depth
C3D
- 8 conv layers + 5 pooling layers + 2 fc layers + softmax
- homogeneous:3x3x3 s1 conv thtoughout
- pool1:1x2x2 kernel size & stride,rest 2x2x2
fc dims:4096

C3D video descriptor:fc6 activations + L2-norm
deconvolution visualizing:
- conv5b feature maps
- starts by focusing on appearance in the first few frames
- tracks the salient motion in the subsequent frames
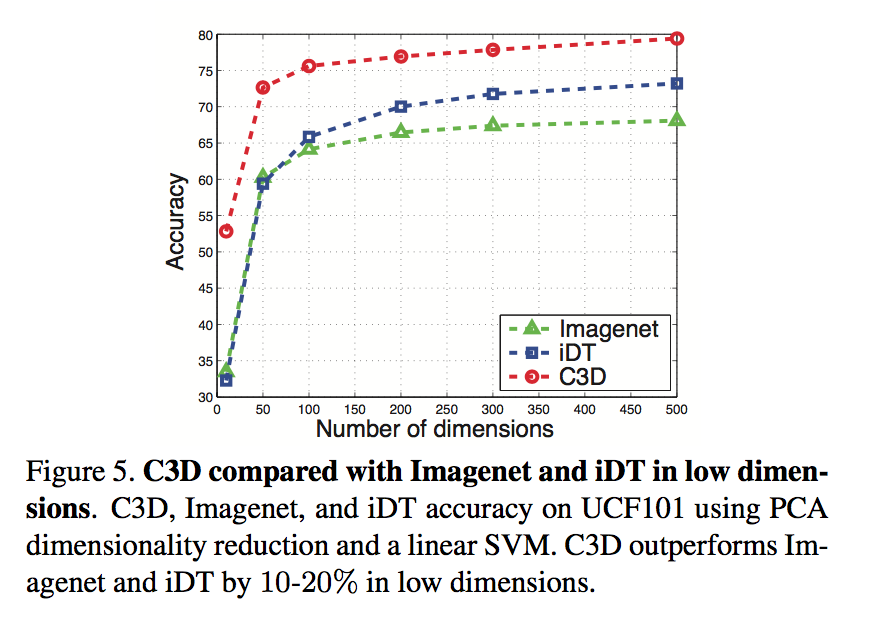
compactness
- PCA
- 压缩到50-100dim不太损失acc
压缩到10dim仍旧是最高acc
projected to 2-dimensional space using t-SNE
- C3D features are semantically separable compared to Imagenet
quantitatively observe that C3D is better than Imagenet

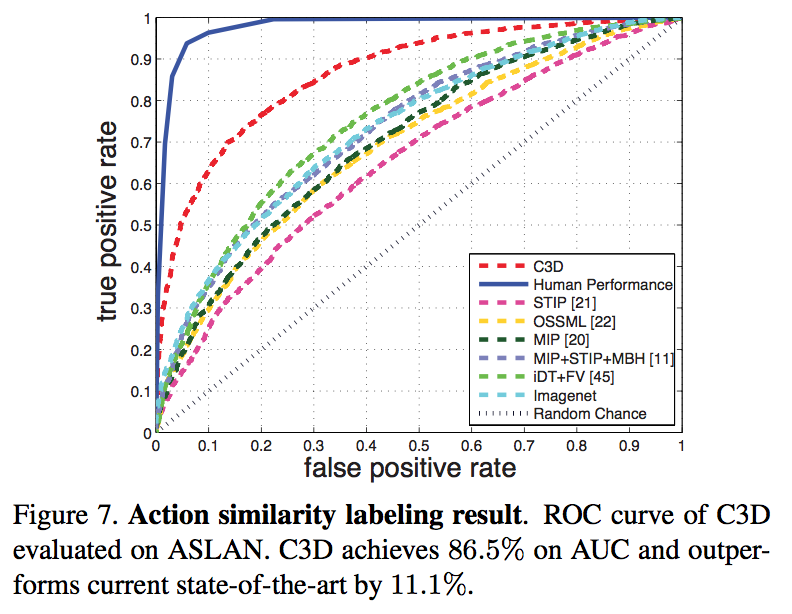
Action Similarity Labeling
- predicting action similarity
- extract C3D features: prob, fc7, fc6, pool5 for each clip
- L2 normalization
- compute the 12 different distances for each feature:48 in total
- linear SVM is trained on these 48-dim feature vectors
C3D significantly outperforms the others