CornerNet: Detecting Objects as Paired Keypoints
动机
- corner formulation
- top-left corner
- bottom-right corner
- anchor-free
- corner pooling
- no multi-scale
- corner formulation
论点
anchor box drawbacks
- huge set of anchors boxes to ensure sufficient overlap,cause huge imbalance
- hyperparameters and design choices
cornerNet
detect and group
- heatmap to predict corners
- 从数学表达上看,全图wh个tl corner,wh个bt corner,可以表达wwhh个框
- anchor-based,全图wh个中心点,9个anchor size,只能表达有限的框,且可能match不上
- embeddings to group pairs of corners
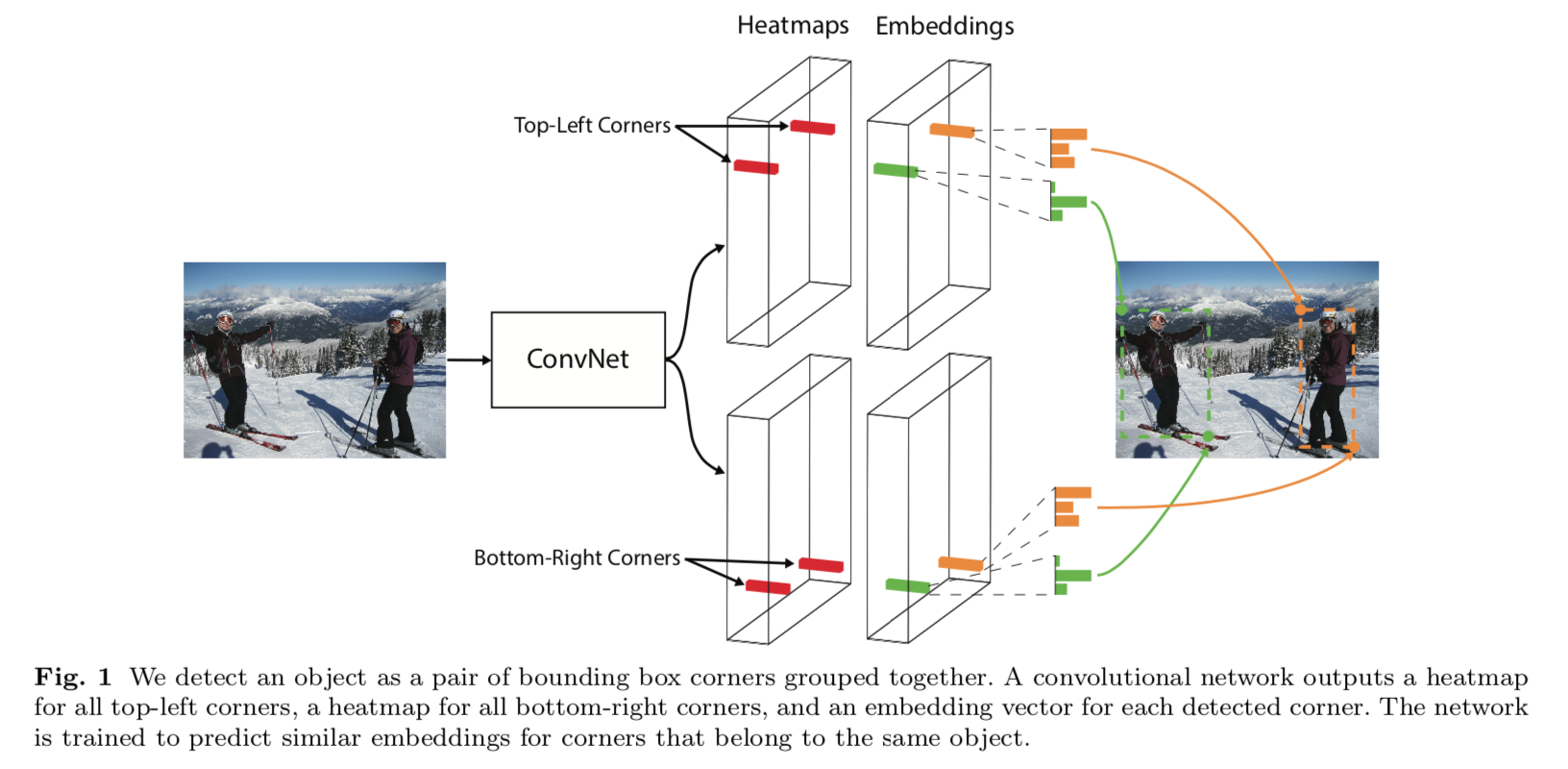
- heatmap to predict corners
corner pooling
better localize corners which are usually out of the foreground
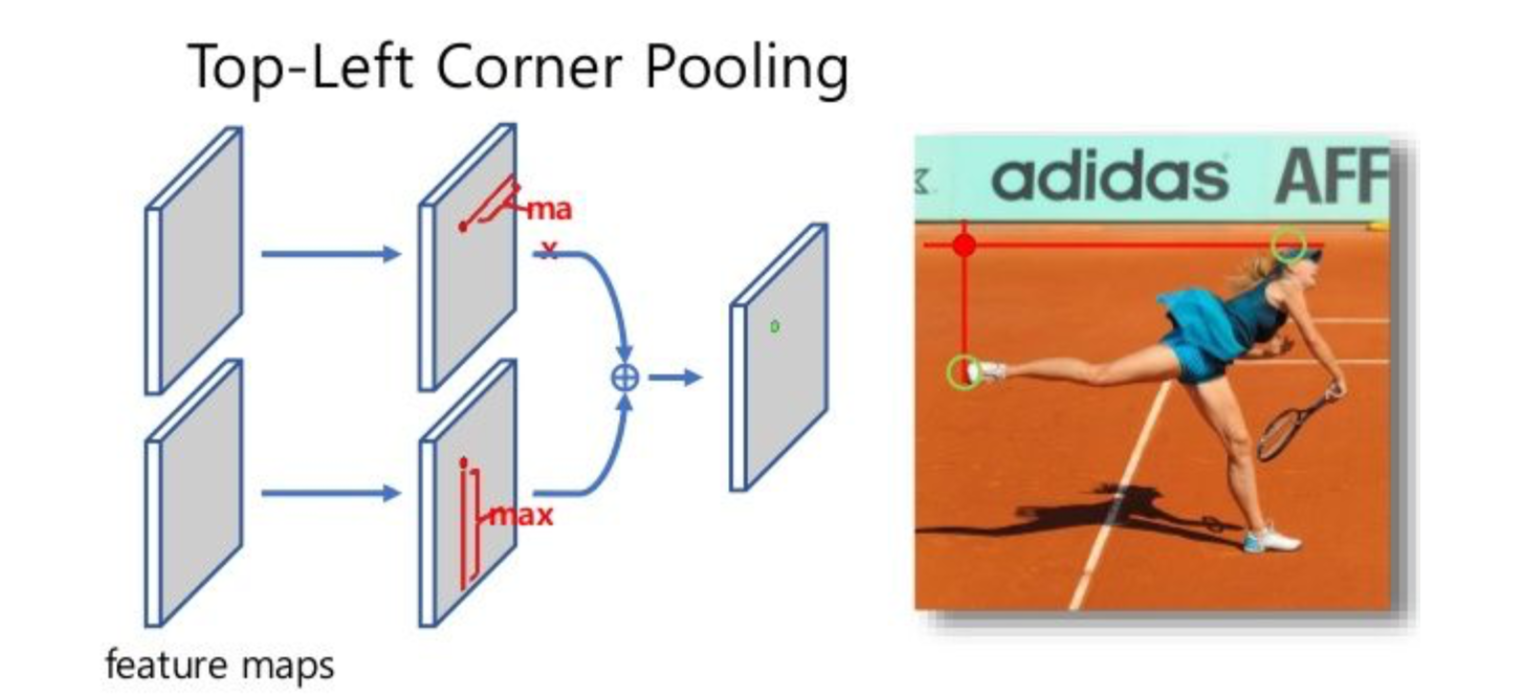
modifid hourglass architecture
add our novel variant of focal loss
方法
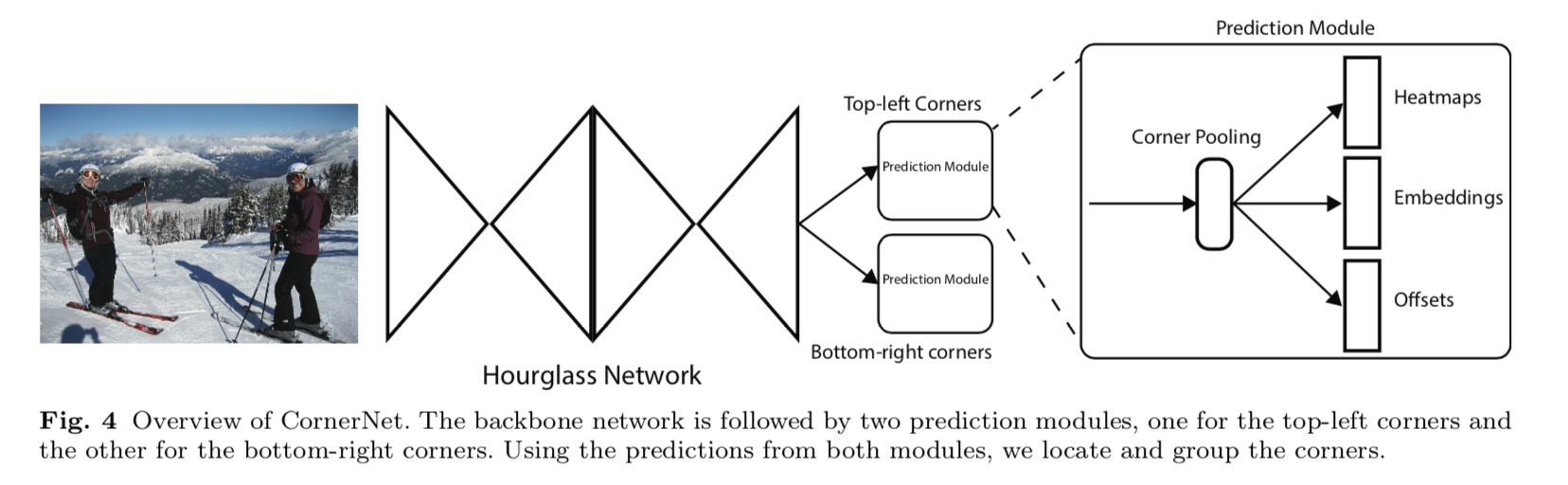
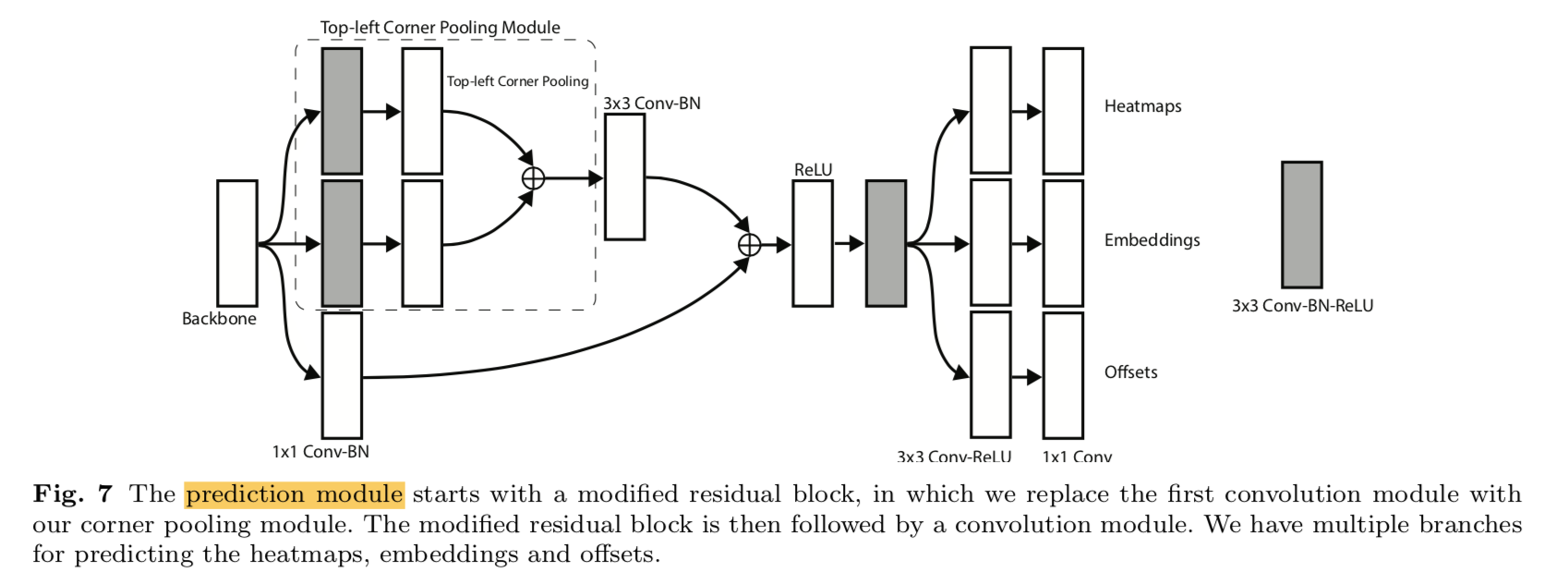
two prediction modules
heatmaps
C channels, C for number of categories
binary mask
each corner has only one ground-truth positive
penalty the neighbored negatives within a radius that still hold high iou (0.3 iou)
- determine the radius
- penalty reduction $=e^{-\frac{x^2+y^2}{2\sigma^2}}$
variant focal loss
$\alpha=2, \beta=4$
N is the number of gts
embeddings
- associative embedding
- use 1-dimension embedding
- pull and push loss on gt positives
- $L_{pull} = \frac{1}{N} \sum^N [(e_{tk}-e_k)^2 + (e_{bk}-e_k)^2]$
- $L_{push} = \frac{1}{N(N-1)} \sum_j^N\sum_{k\neq j}^N max(0, \Delta -|e_k-e_j|)$
- $e_k$ is the average of $e_{tk}$ and $e{bk}$
- $\Delta$ = 1
offsets
- 从heatmap resolution remapping到origin resolution存在精度损失
greatly affect the IoU of small bounding boxes
shared among all categories
smooth L1 loss on gt positives
$$ L_{off} = \frac{1}{N} \sum^N SmoothL1(o_k, \hat o_k)$$
corner pooling
- top-left pooling layer:
* 从当前点(i,j)开始, * 向下elementwise max所有feature vecor,得到$t_{i,j}$ * 向右elementwise max所有feature vecor,得到$l_{i,j}$ * 最后两个vector相加- bottom-right corner:向左向上
- top-left pooling layer:
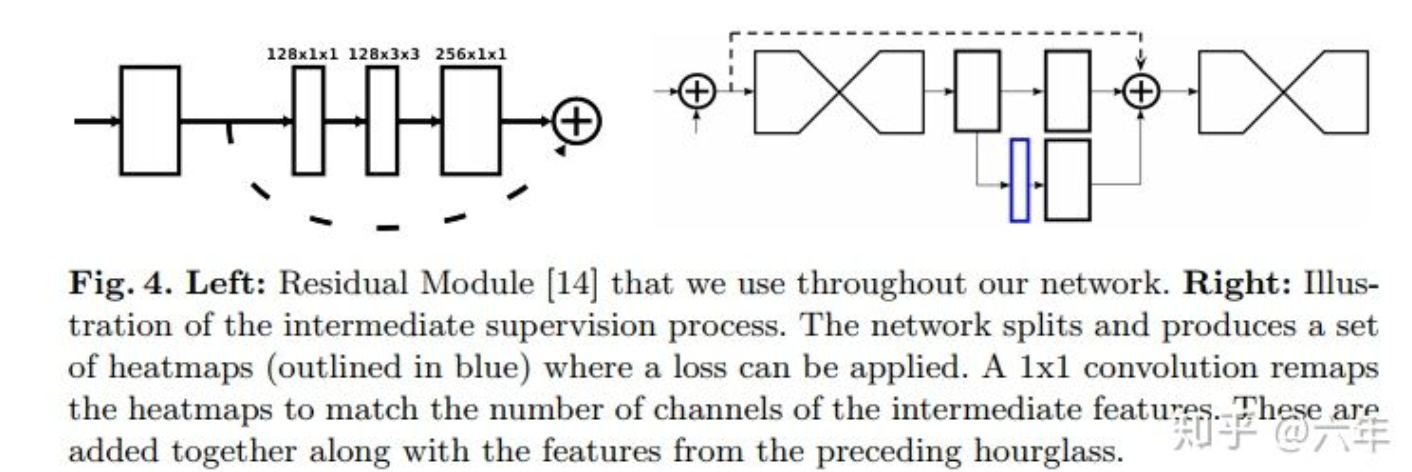
Hourglass Network
- hourglass modules
- series of convolution and max pooling layers
- series of upsampling and convolution layers
- skip layers
multiple hourglass modules stacked:reprocess the features to capture higher-level information
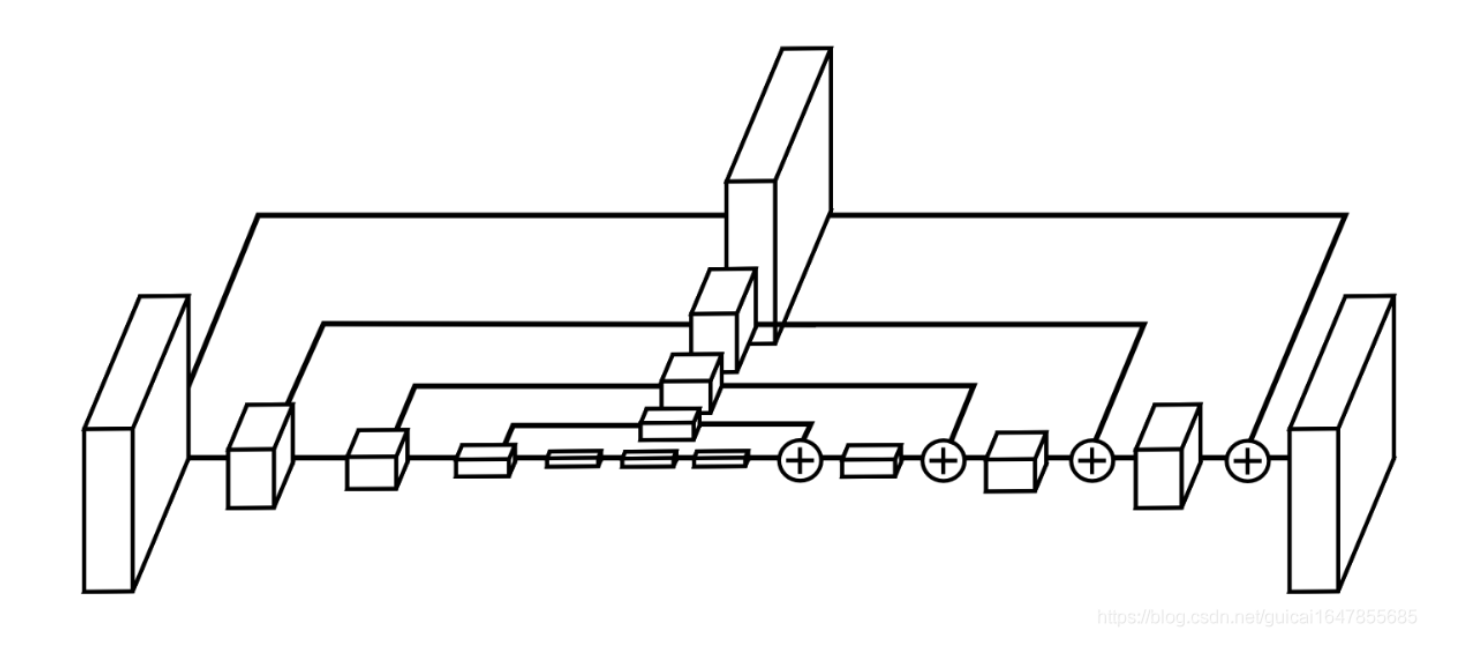
intermediate supervision
常规的中继监督:
下一级hourglass module的输入包括三个部分
- 前一级输入
- 前一级输出
- 中继监督的输出
本文使用了中继监督,但是没把这个结果加回去
- hourglass2 input:1x1 conv-BN to both input and output of hourglass1 + add + relu
- hourglass modules
Our backbone
- 2 hourglasses
- 5 times downsamp with channels [256,384,384,384,512]
- use stride2 conv instead of max-pooling
- upsamp:2 residual modules + nearest neighbor upsampling
- skip connection: 2 residual modules,add
- mid connection: 4 residual modules
- stem: 7x7 stride2, ch128 + residual stride2, ch256
- hourglass2 input:1x1 conv-BN to both input and output of hourglass1 + add + relu
实验
- training details
- randomly initialized, no pretrained
- bias:set the biases in the convolution layers that predict the corner heatmaps
- input:511x511
- output:128x128
- apply PCA to the input image
- full loss:$L = L_{det} + \alpha L_{pull} + \beta L_{push} + \gamma L_{off}$
- 配对loss:$\alpha=\beta=0.1$
- offset loss:$\gamma=1$
- batch size = 49 = 4+5x9
- test details
- NMS:3x3 max pooling on heatmaps
- pick:top100 top-left corners & top100 bottom-right corners
- filter pairs:
- L1 distance greater than 0.5
- from different categories
- fusion:combine the detections from the original and flipped images + soft nms
- Ablation Study
- corner pooling is especially helpful for medium and large objects
- penalty reduction especially benefits medium and large objects
- CornerNet achieves a much higher AP at 0.9 IoU than other detectors:更有能力生成高质量框
- error analysis:the main bottleneck is detecting corners
- training details
CornerNet-Lite: Efficient Keypoint-Based Object Detection
动机
keypoint-based methods
- detecting and grouping
- accuary but with processing cost
propose CornerNet-Lite
- CornerNet-Saccade:attention mechanism
- CornerNet-Squeeze:a new compact backbone
performance
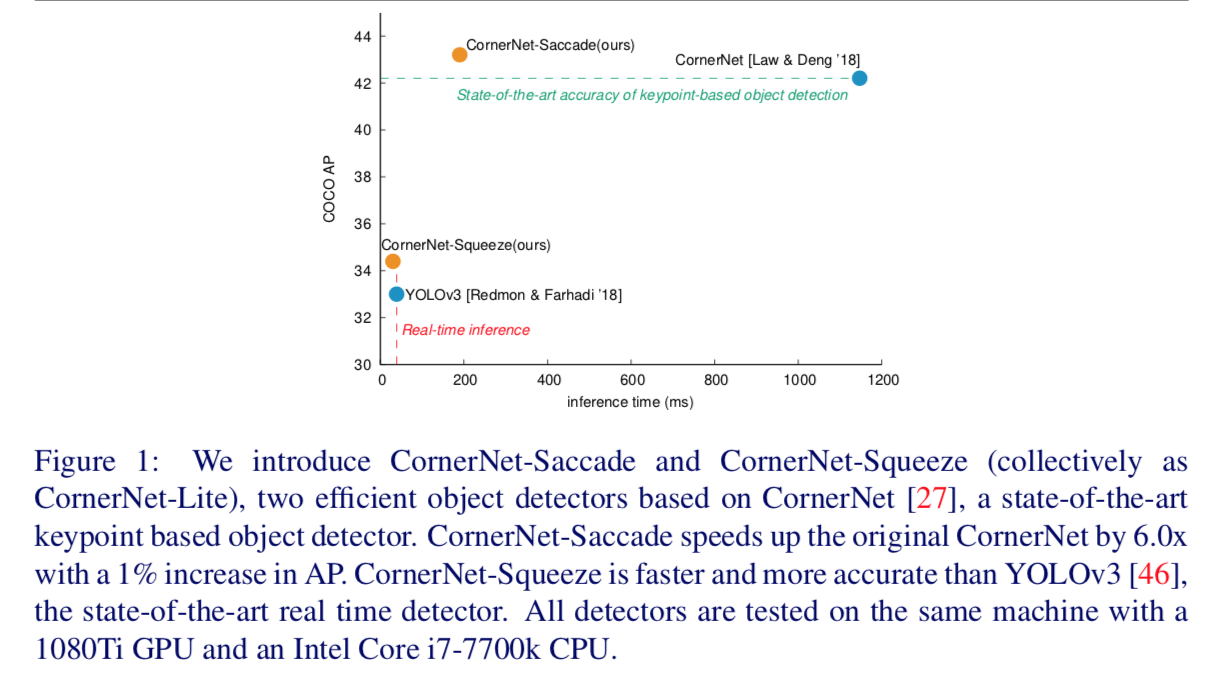
论点
- main drawback of cornerNet
- inference speed
- reducing the number of scales or the image resolution cause a large accuracy drop
- two orthogonal directions
- reduce the number of pixels to process:CornerNet-Saccade
- reduce the amount of processing per pixel:
- CornerNet-Saccade
- downsized attention map
- select a subset of crops to examine in high resolution
- for off-line:AP of 43.2% at 190ms per image
- CornerNet-Squeeze
- inspired by squeezeNet and mobileNet
- 1x1 convs
- bottleneck layers
- depth-wise separable convolution
- for real-time:AP of 34.4% at 30ms
- combined??
- CornerNet-Squeeze-Saccade turns out slower and less accurate than CornerNet- Squeeze
- Saccades:扫视
- to generate interesting crops
- RCNN系列:single-type & single object
- AutoFocus:add a branch调用faster-RCNN,thus multi-type & mixed-objects,有single branch有multi branch
- CornerNet-Saccade:
- single-type & multi object
- crops can be much smaller than number of objects
- main drawback of cornerNet
方法
CornerNet-Saccade
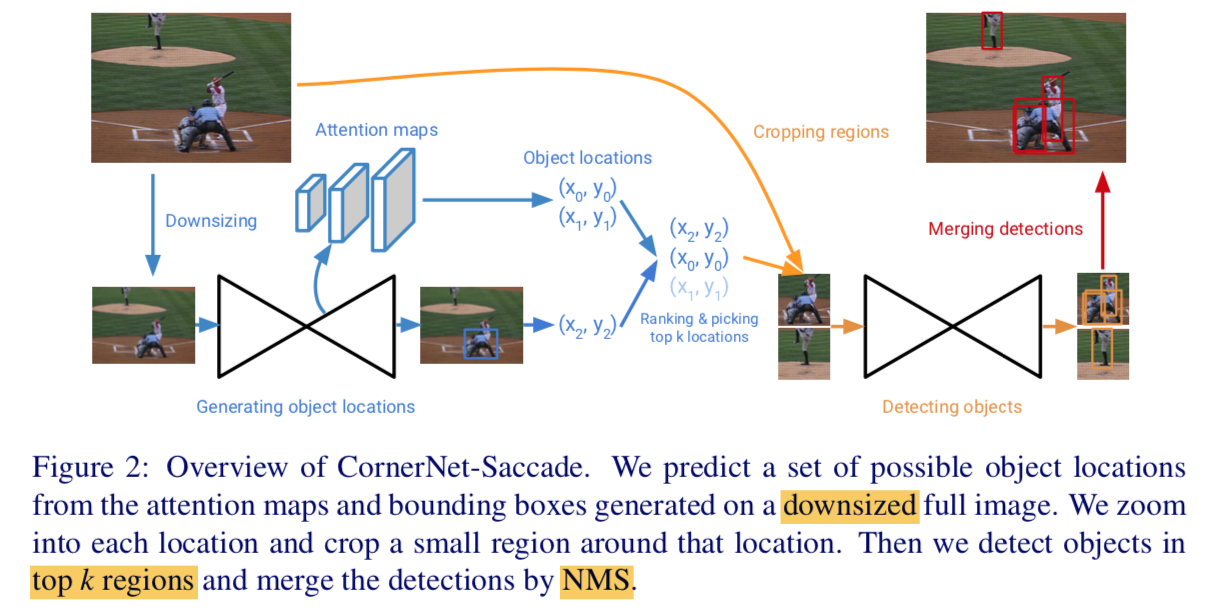
step1:obtain possible locations
- downsize:two scales,255 & 192,zero-padding
- predicts 3 attention maps
- small object:longer side<32 pixels
- medium object:32-96
- large object:>96
- so that we can control the zoom-in factor:zoom-in more for smaller objects
- feature map:different scales from the upsampling layers
- attention map:3x3 conv-relu + 1x1 conv-sigmoid
- process locations where scores > 0.3
step2:finer detection
- zoom-in scales:4,2,1 for small、medium、large objects
- apply CornerNet-Saccade on the ROI
- 255x255 window
- centered at the location
step3:NMS
- soft-nms
- remove the bounding boxes which touch the crop boundary
CornerNet-Saccade uses the same network for attention maps and bounding boxes
- 在第一步的时候,对一些大目标已经有了检测框
- 也要zoom-in,矫正一下
efficiency
- regions/croped images都是processed in batch/parallel
- resize/crop操作在GPU中实现
suppress redundant regions using a NMS-similar policy before prediction

new hourglass backbone
- 3 hourglass module,depth 54
- downsize twice before hourglass modules
- downsize 3 times in each module,with channels [384,384,512]
- one residual in both encoding path & skip connection
- mid connection:one residual,with channels 512
CornerNet-Squeeze
- to replace the heavy hourglass104
- use fire module to replace residuals
- downsizes 3 times before hourglass modules
- downsize 4 times in each module
- replace the 3x3 conv in prediction head with 1x1 conv
replace the nearest neighboor upsampling with 4x4 transpose conv
