- [YOLACT] Real-time Instance Segmentation:33 FPS/30 mAP
- [YOLACT++] Better Real-time Instance Segmentation:33.5 FPS/34.1 mAP
YOLACT: Real-time Instance Segmentation
动机
create a real-time instance segmentation base on fast, one-stage detection model
forgoes an explicit localization step (e.g., feature repooling)
- doesn’t depend on repooling (RoI Pooling)
- produces very high-quality masks
set two parallel subtasks
- prototypes——conv
- mask coefficients——fc
- 之后将模板mask和实例mask系数进行线性组合来获得实例的mask
‘prototypes’: vocabulary
fully-convolutional
- localization is still translation variant
Fast NMS
论点
State-of-the-art approaches to instance segmentation like Mask R- CNN and FCIS directly build off of advances in object detection like Faster R-CNNand R-FCN
- focus primarily on performance over speed
- these methods “re-pool” features in some bounding box region
- inherently sequential therefore difficult to accelerate
One-stage instance segmentation methods generate position sensitive maps
- still require repooling or other non-trivial computations
prototypes
- related works use prototypes to represent features (Bag of Feature)
- we use them to assemble masks for instance segmentation
- we learn prototypes that are specific to each image, rather than global prototypes shared across the entire dataset
Bag of Feature
BOF假设图像相当于一个文本,图像中的不同局部区域或特征可以看作是构成图像的词汇(codebook)

所有的样本共享一份词汇本,针对每个图像,统计每个单词的频次,即可得到图片的特征向量
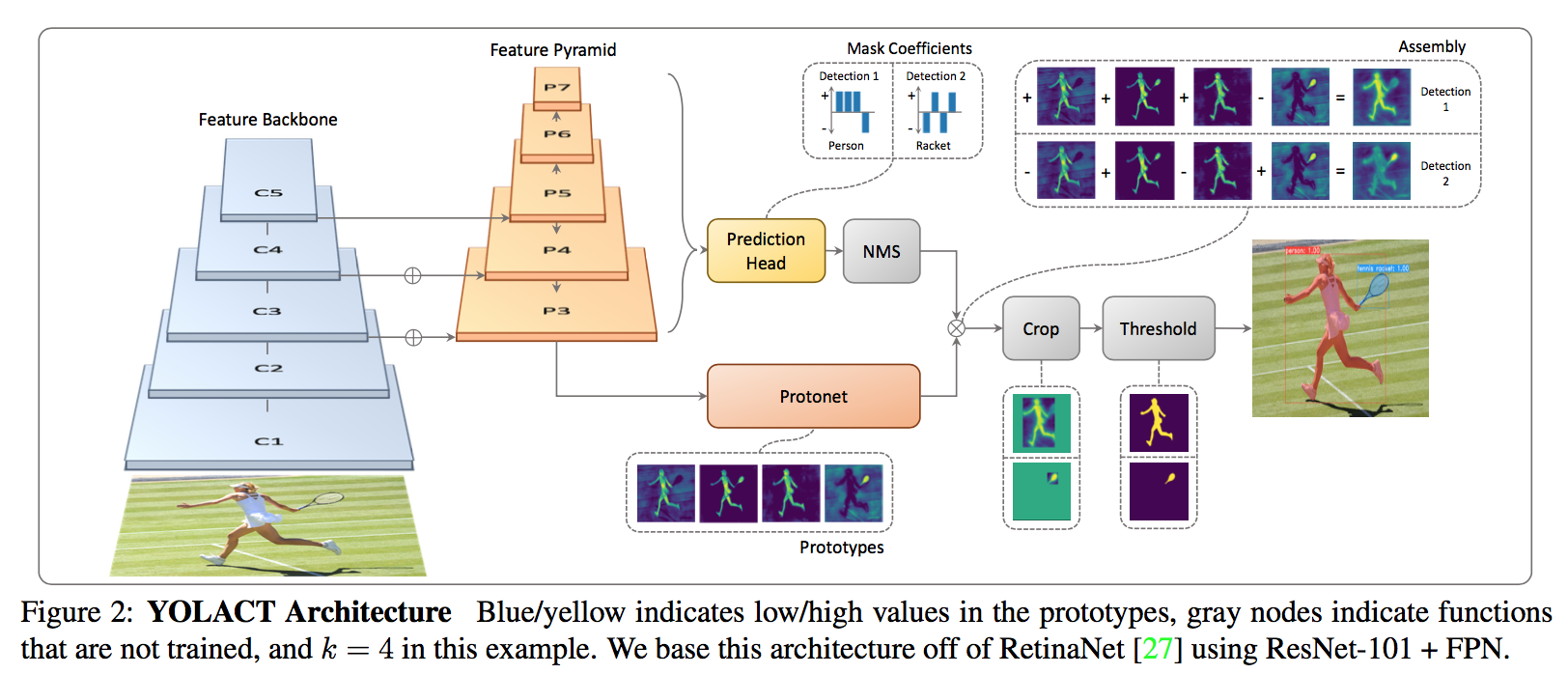
方法
parallel tasks
- The first branch uses an FCN to produce a set of image-sized “prototype masks” that do not depend on any one instance.
- The second adds an extra head to the object detection branch to predict a vector of “mask coefficients” for each anchor that encode an instance’s rep- resentation in the prototype space.
- linearly combining
Rationale
- masks are spatially coherent:mash是空间相关的,相邻像素很可能是一类
- 卷积层能够利用到这种空间相关性,但是fc层不能
- 而one-stage检测器的检测头通常是fc层??
- making use of fc layers, which are good at producing semantic vectors
- and conv layers, which are good at producing spatially coherent masks
Prototype
- 在backbone feature layer P3上接一个FCN
- taking protonet from deeper backbone features produces more robust masks
- higher resolution prototypes result in both higher quality masks and better performance on smaller objects
- upsample到x4的尺度to increase performance on small objects
head包含k个channels
- 梯度回传来源于最终的final assembled mask,不是当前这个头
- unbounded:ReLU or no nonlinearity
- We choose ReLU for more interpretable prototypes
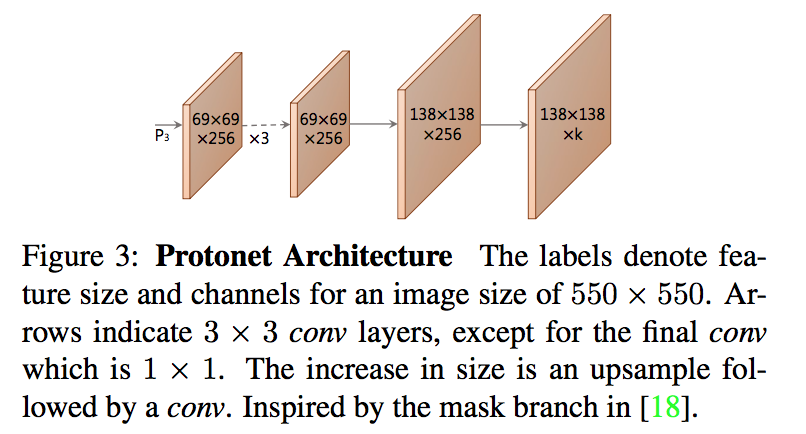
- 在backbone feature layer P3上接一个FCN
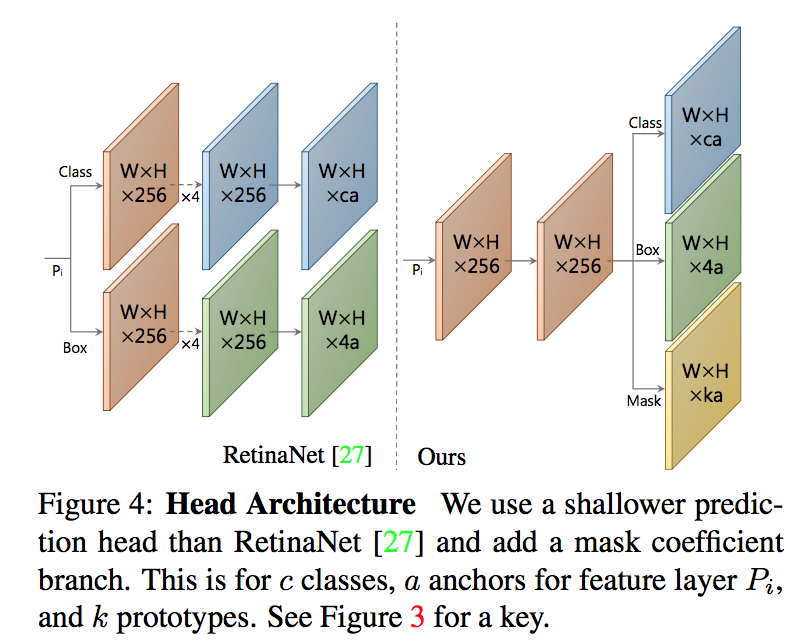
Mask Coefficients
- a third branch in parallel with detection heads
nonlinearity:要有正负,所以tanh
Mask Assembly
- linear combination + sigmoid: $M=\sigma(PC^T)$
- loss
- cls loss:w=1, 和ssd一样,c+1 softmax
- box reg loss:w=1.5, 和ssd一样,smooth-L1
- mask loss:w=6.125, BCE
- crop mask
- eval:用predict box去crop
- train:用gt box去crop,同时还要给mask loss除以gt box的面积,to preserve small objects
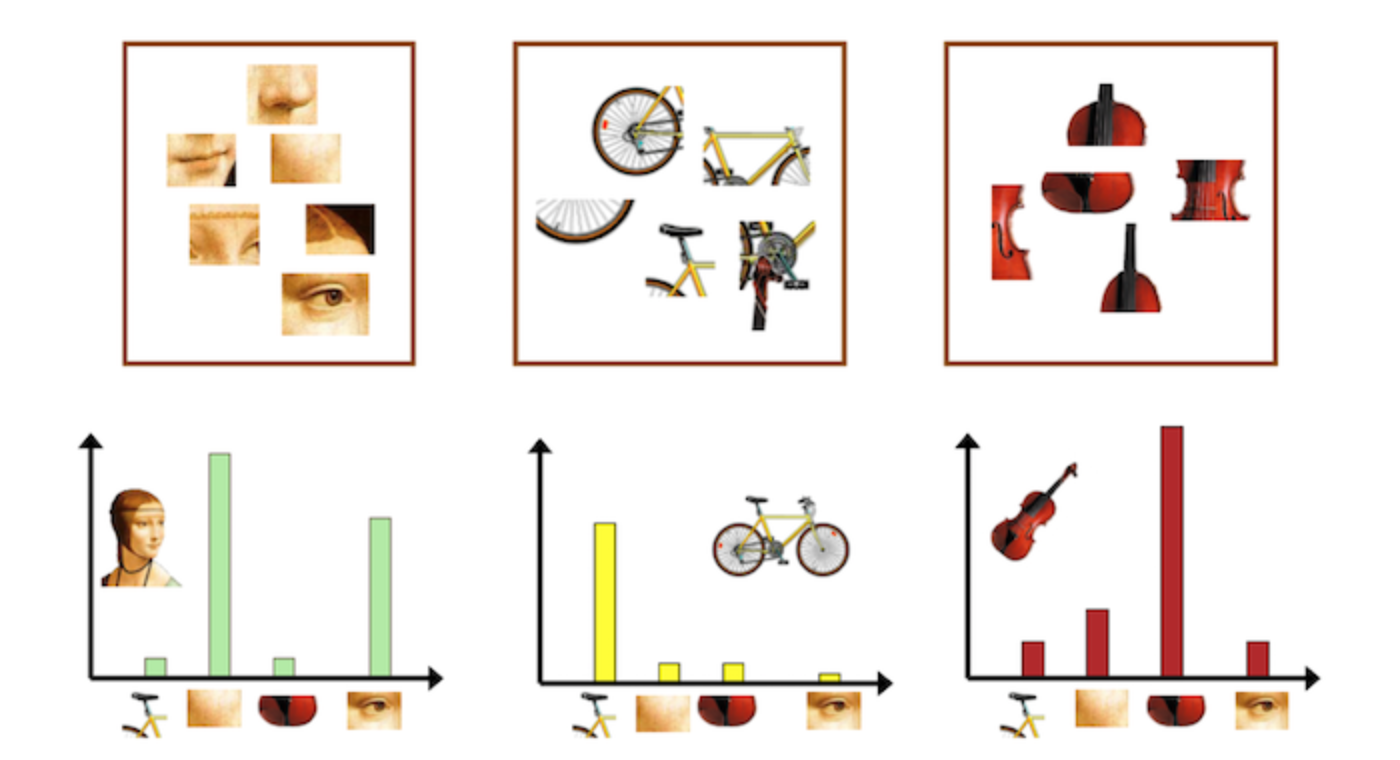
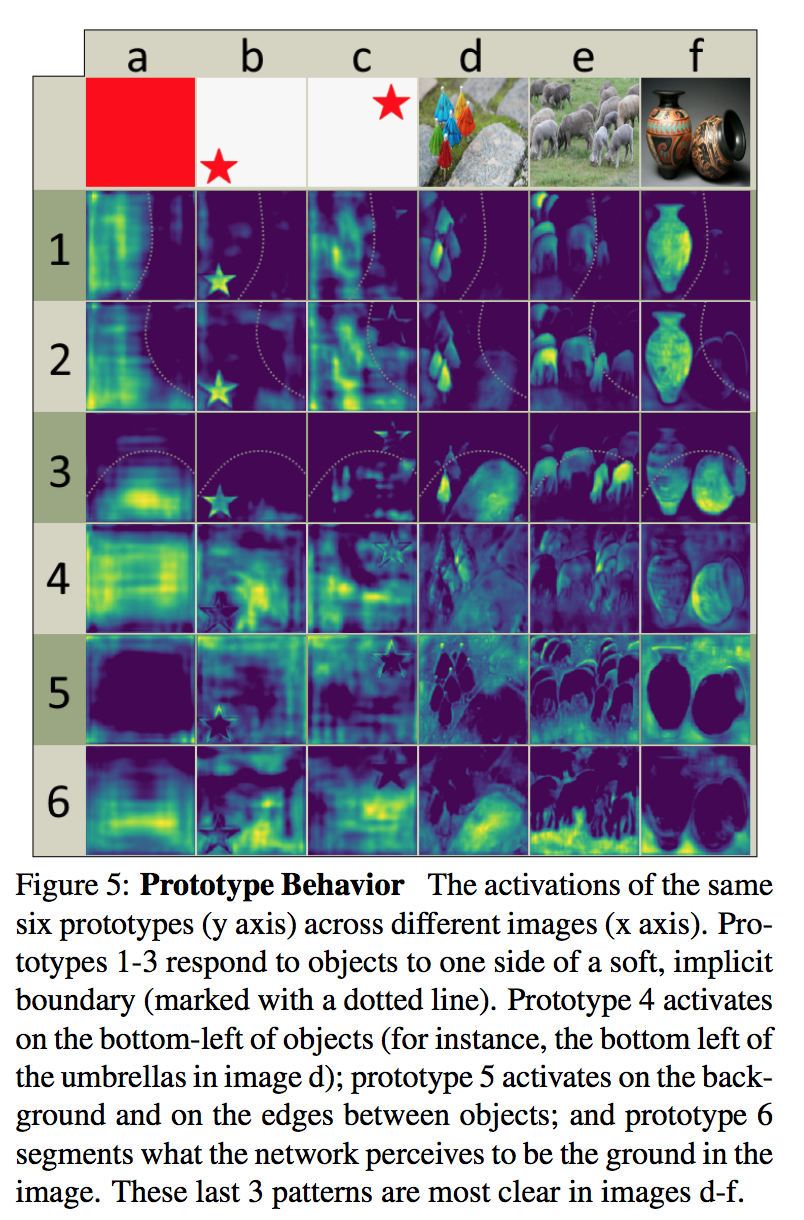
Emergent Behavior
不crop也能分割中大目标:
- YOLACT learns how to localize instances on its own via different activations in its prototypes
- 而不是靠定位结果
translation variant
- the consistent rim of padding in modern FCNs like ResNet gives the network the ability to tell how far away from the image’s edge a pixel is,所以用一张纯色的图能够看出kernel实际highlight的是哪部分特征
- 同一种kernel,同一种五角星,在画面不同位置,对应的响应值是不同的,说明fcn是能够提取物体位置这样的语义信息的
prototypes are compressible:
- 增加模版数目反而不太有效,because predicting coefficients is difficult,
- the network has to play a balancing act to produce the right coef- ficients, and adding more prototypes makes this harder,
- We choose 32 for its mix of performance and speed
Network
- speed as well as feature richness
- backbone参考RetinaNet,ResNet-101 + FPN
- 550x550 input,resize
- 去掉P2,add P6&P7
- 3 anchors per level,[1, 1/2, 2]
- P3的anchor尺寸是24x24,接下来每层double the scale
- 检测头:shared conv+parallel conv
- OHEM
single GPU:batch size 8 using ImageNet weights,no extra bn layers
Fast NMS
- 构造cxnxn的矩阵,c代表每个class
- 然后搞成上三角,求column-wise max
- 再IoU threshold
- 15.0 ms faster with a performance loss of 0.3 mAP
- Semantic Segmentation Loss
- using modules not executed at test time
- P3上1x1 conv,sigmoid and c channels
- w=1
- +0.4 mAP boost