[SOLO] SOLO: Segmenting Objects by Locations:字节,目前绝大多数方法实例分割的结构都是间接得到——检测框内语义分割/全图语义分割聚类,主要原因是formulation issue,很难把实例分割定义成一个结构化的问题
[SOLOv2] SOLOv2: Dynamic, Faster and Stronger:best 41.7% AP
SOLO: Segmenting Objects by Locations
动机
- challenging:arbitrary number of instances
- form the task into a classification-solvable problem
- direct & end-to-end & one-stage & using mask annotations solely
- on par accuracy with Mask R-CNN
- outperforming recent single-shot instance segmenters
论点
- formulating
- Objects in an image belong to a fixed set of semantic categories——semantic segmentation can be easily formulated as a dense per-pixel classification problem
- the number of instances varies
- existing methods
- 检测/聚类:step-wise and indirect
- 累积误差
- core idea
- in most cases two instances in an image either have different center locations or have different object sizes
- location:
- think image as a divided grid of cells
- an object instance is assigned to one of the grid cells as its center location category
- encode center location categories as the channel axis
- size
- FPN
- assign objects of different sizes to different levels of feature maps
- SOLO converts coordinate regression into classification by discrete quantization
- One feat of doing so is the avoidance of heuristic coordination normalization and log-transformation typically used in detectors【???不懂这句话想表达啥】
- formulating
方法
problem formulation
- divided grids
simultaneous task
- category-aware prediction
- instance-aware mask generation
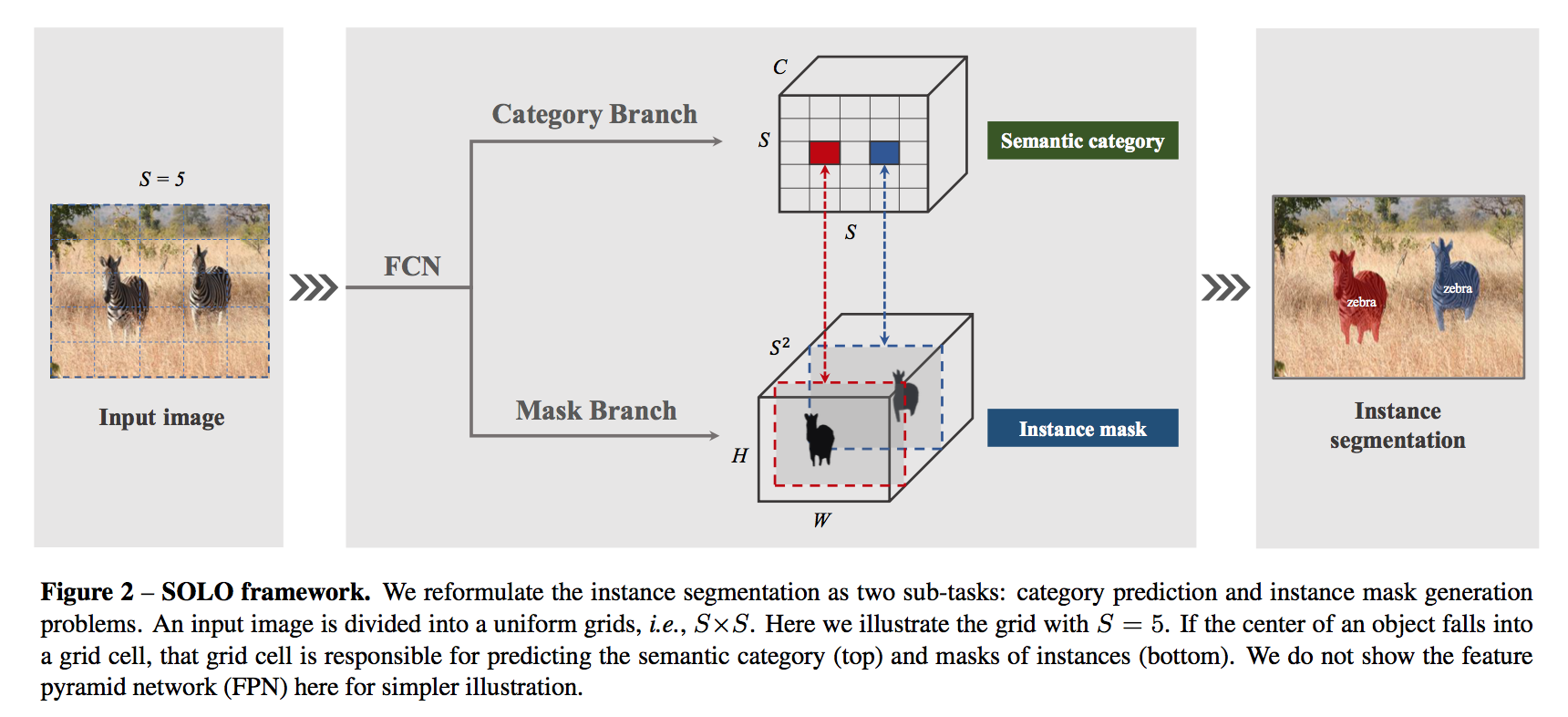
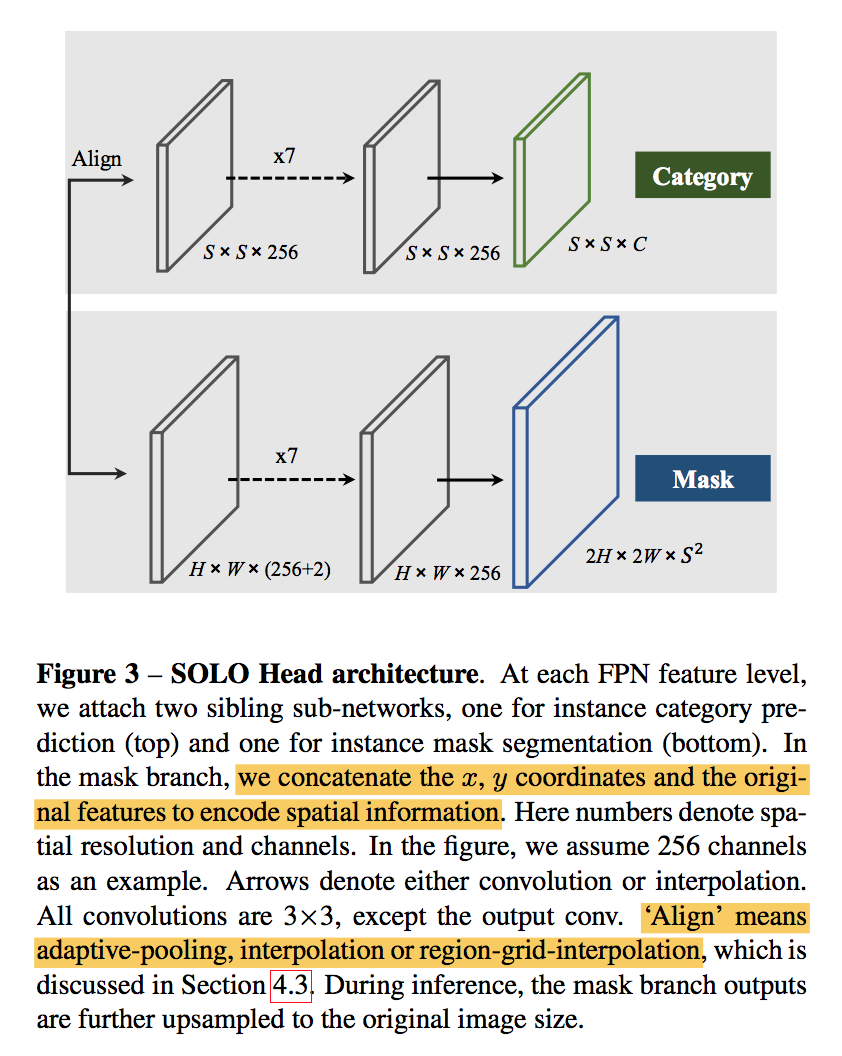
category prediction
- predict instance for each grid:$SSC$
- grid size:$S*S$
- number of classes:$C$
- based on the assumption that each cell must belong to one individual instance
- C-dim vec indicates the class probability for each object instance in each grid
- mask prediction
- predict instance mask for each positive cell:$HWS^2$
- the channel corresponding to the location
- position sensitive:因为每个grid中分割的mask是要映射到对应的channel的,因此我们希望特征图是spatially variant
- 让特征图spatially variant的最直接办法就是加一维spatially variant的信息
- inspired by CoordConv:添加两个通道,normed_x和normed_y,[-1,1]
- original feature tensor $HWD$ becomes $HW(D+2)$
- final results
- gather category prediction & mask prediction
- NMS
network
- backbone:resnet
- FCN:256-d
heads:weights are shared across different levels except for the last 1x1 conv
learning
- positive grid:falls into a center region
- mask:mask center $(c_x, c_y)$,mask size $(h,w)$
- center region:$(c_x,c_y,\epsilon w, \epsilon h)$,set $\epsilon = 0.2$
- loss:$L = L_{cate} + \lambda L_{seg}$
- cate loss:focal loss
- seg loss:dice,$L_{mask} = \frac{1}{N_{pos}}\sum_k 1_{p^_{i,j}>0} dice(m_k, m^_k) $,带星号的是groud truth
- positive grid:falls into a center region
inference
use a confidence threshold of 0.1 to filter out low spacial predictions
use a threshold of 0.5 to binary the soft masks
select the top 500 scoring masks
NMS
- Only one instance will be activated at each grid
and one in- stance may be predicted by multiple adjacent mask channels

keep top 100
实验
grid number
- 适当增加有提升,主要提升还是在FPN
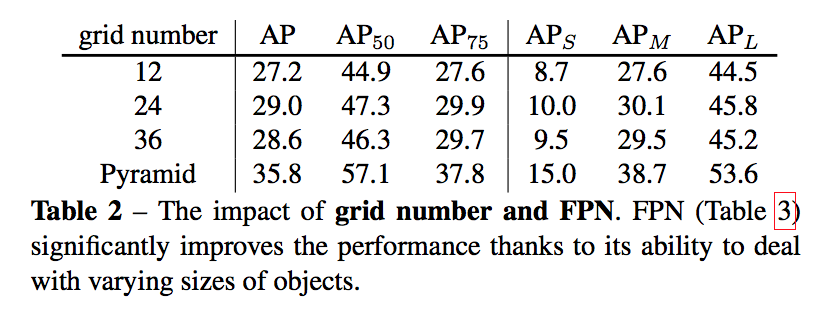
fpn
- 五个FPN pyramids
大特征图,小感受野,用来分配小目标,grid数量要增大

feature alignment
- 在分类branch,$HW$特征图要转换成$SS$的特征图
- interpolation:bilinear interpolating
- adaptive-pool:apply a 2D adaptive max-pool
- region-grid- interpolation:对每个cell,采样多个点做双线性插值,然后取平均
- is no noticeable performance gap between these variants
- (可能因为最终是分类任务
- 在分类branch,$HW$特征图要转换成$SS$的特征图
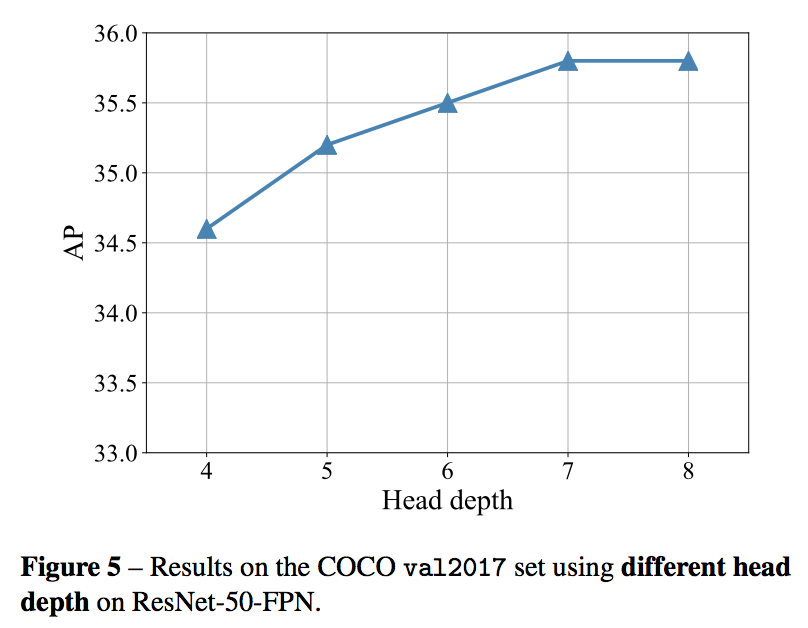
head depth
- 4-7有涨点
- 所以本文选了7
decoupled SOLO
mask branch预测的channel数是$S^2$,其中大部分channel其实是没有贡献的,空占内存
prediction is somewhat redundant as in most cases the objects are located sparsely in the image
element-wise multiplication
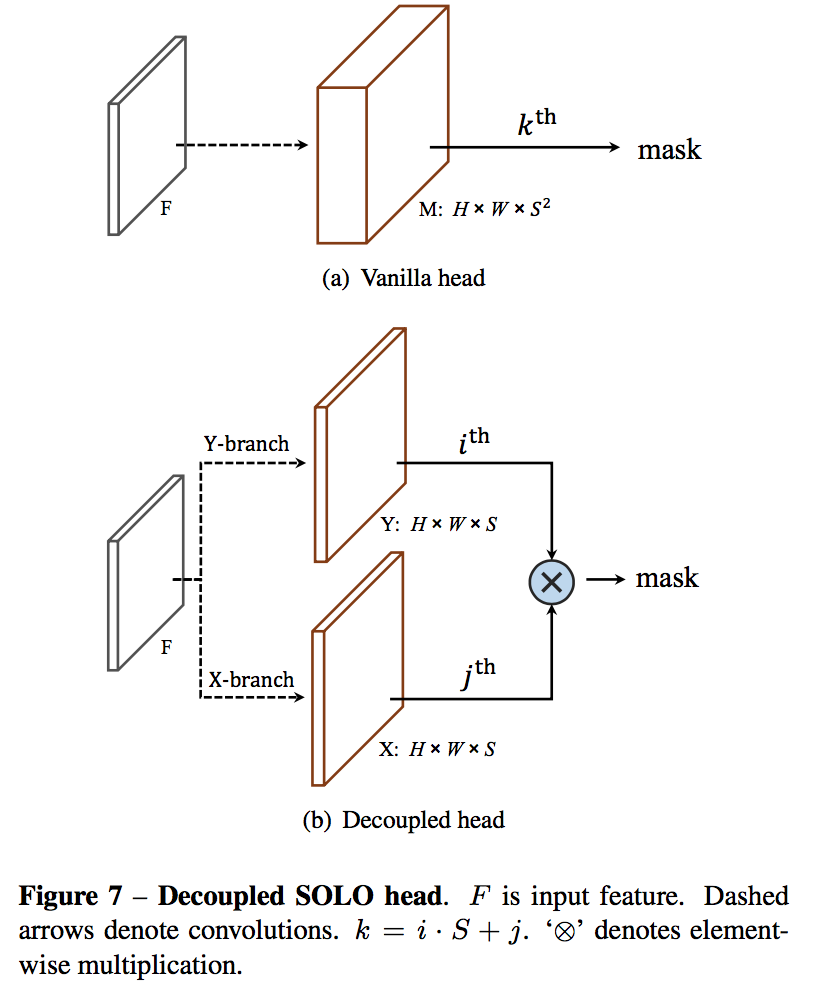
实验下来
- achieves the same performance
- efficient and equivalent variant
SOLOv2: Dynamic, Faster and Stronger
动机
- take one step further on the mask head
- dynamically learning the mask head
- decoupled into mask kernel branch and mask feature branch
- propose Matrix NMS
- faster & better results
- try object detection and panoptic segmentation
- take one step further on the mask head
论点
- SOLO develop pure instance segmentation
- instance segmentation
- requires instance-level and pixel-level predictions simultaneously
- most existing instance segmentation methods build on the top of bounding boxes
- SOLO develop pure instance segmentation
- SOLOv2 improve SOLO
- mask learning:dynamic scheme
- mask NMS:parallel matrix operations,outperforms Fast NMS
- Dynamic Convolutions
- STN:adaptively transform feature maps conditioned on the input
- Deformable Convolutional Networks:learn location
方法
revisit SOLOv1
- redundant mask prediction
- decouple
dynamic:dynamically pick the valid ones from predicted $s^2$ classifiers and perform the convolution
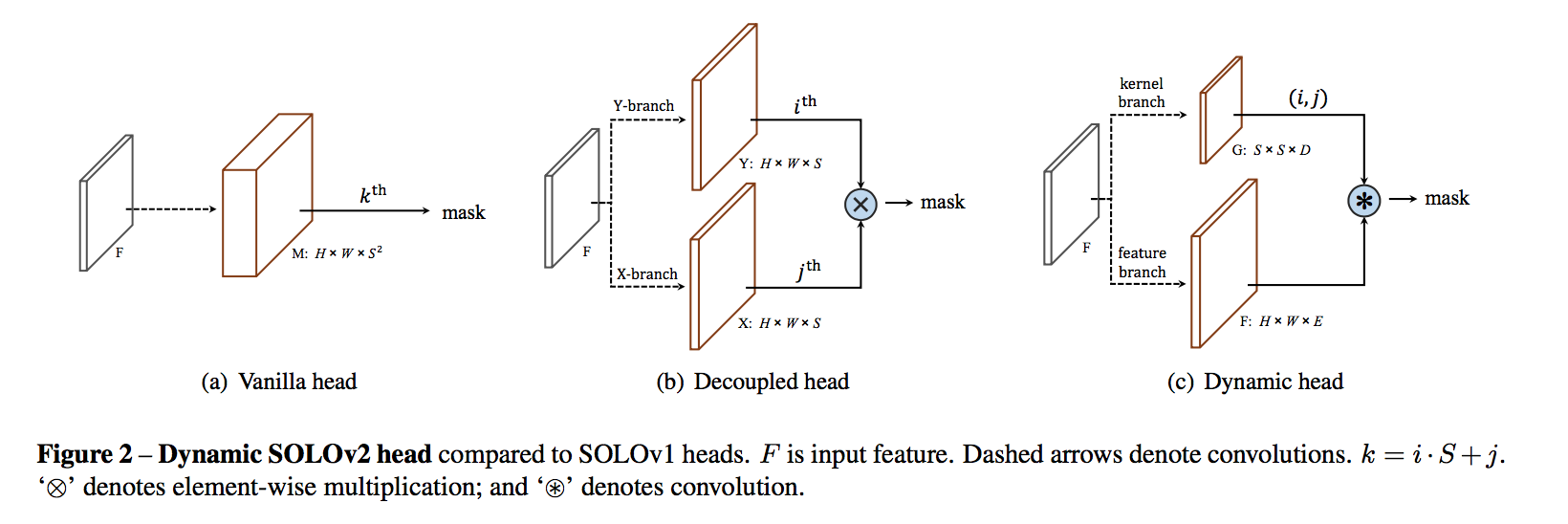
SOLOv2
dynamic mask segmentation head
- mask kernel branch
- mask feature branch
mask kernel branch
- prediction heads:4 convs + 1 final conv,shared across scale
- no activation on the output
- concat normalized coordinates in two additional input channels at start
- ouputs D-dims kernel weights for each grid:e.g. for 3x3 conv with E input channels, outputs $SS9E$
mask feature branch
predict instance-aware feature:$F \in R^{HWE}$
unified and high-resolution mask feature:只输出一个尺度的特征图,encoded x32 feature with coordinates info
- we feed normalized pixel coordinates to the deepest FPN level (at 1/32 scale)
- repeated 【3x3 conv, group norm, ReLU, 2x bilinear upsampling】
- element-wise sum
last layer:1x1 conv, group norm, ReLU
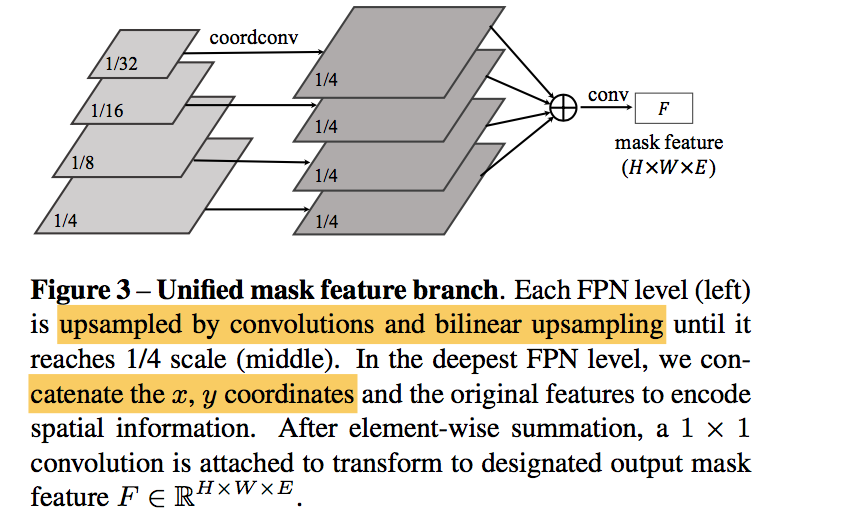
instance mask
- mask feature branch conved by the mask kernel branch:final conv $HWS^2$
- mask NMS
train
- loss:$L = L_{cate} + \lambda L_{seg}$
- cate loss:focal loss
- seg loss:dice,$L_{mask} = \frac{1}{N_{pos}}\sum_k 1_{p^_{i,j}>0} dice(m_k, m^_k) $,带星号的是groud truth
- loss:$L = L_{cate} + \lambda L_{seg}$
inference
- category score:first use a confidence threshold of 0.1 to filter out predictions with low confidence
- mask branch:run convolution based on the filtered category map
- sigmoid
- use a threshold of 0.5 to convert predicted soft masks to binary masks
- Matrix NMS
Matrix NMS
- decremented functions
- linear:$f(iou_{i,j}=1-iou_{i,j})$
- gaussian:$f(iou_{i,j}=exp(-\frac{iou_{i,j}^2}{\sigma})$
- the most overlapped prediction for $m_i$:max iou
- $f(iou_{*,i}) = min_{s_k}f(iou_{k,i})$
- decay factor
- $decay_i = min \frac{f(iou_{i,j})}{f(iou_{*,i})}$

- decremented functions