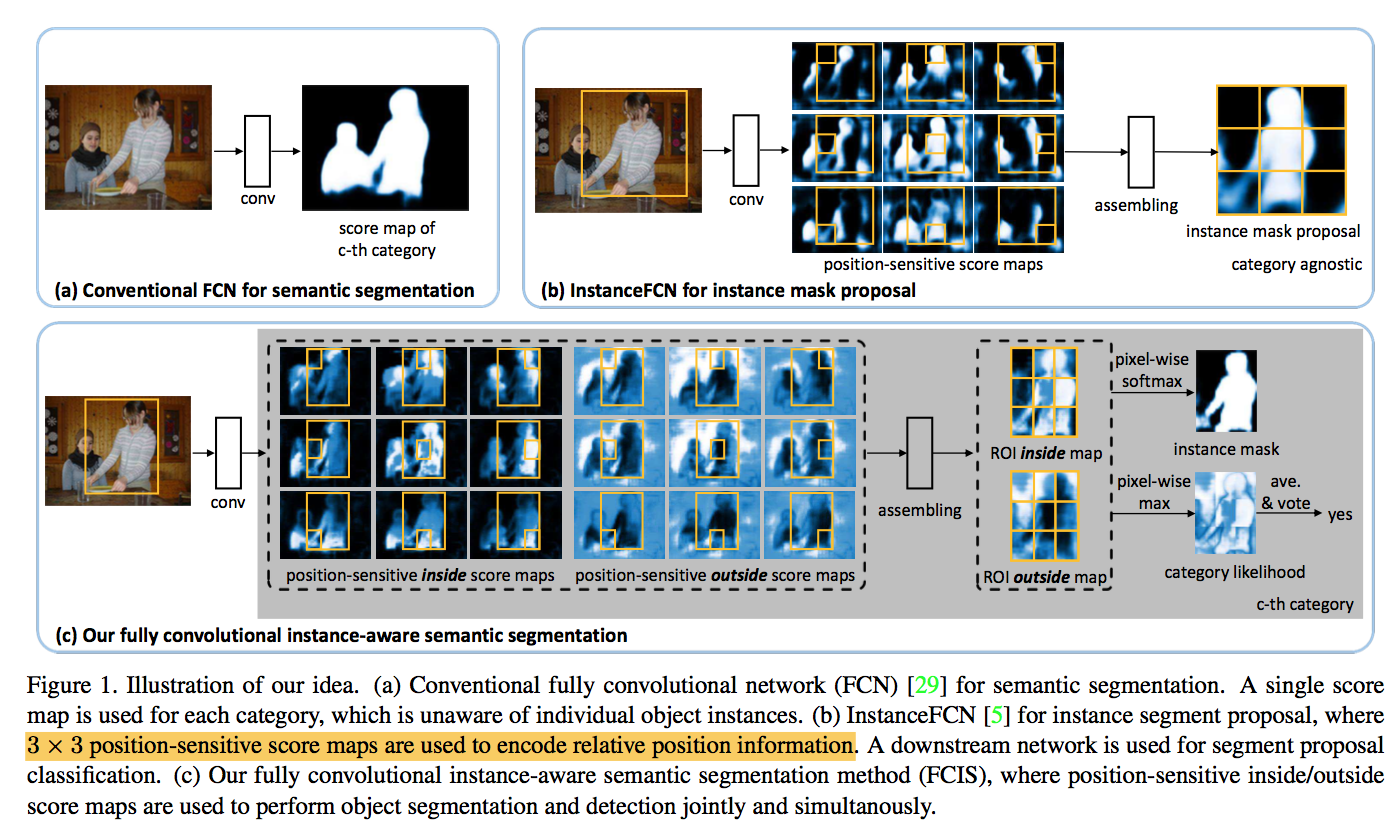
Fully Convolutional Instance-aware Semantic Segmentation
动机
- instance segmentation:
- 实例分割比起检测,需要得到目标更精确的边界信息
- 比起语义分割,需要区分不同的物体
- detects and segments simultanously
- FCN + instance mask proposal
- instance segmentation:
论点
- FCNs do not work for the instance-aware semantic segmentation task
- convolution is translation invariant:权值共享,一个像素值对应一个响应值,与位置无关
- instance segmentation operates on region level
- the same pixel can have different semantics in different regions
- Certain translation-variant property is required
- prevalent method
- step1: an FCN is applied on the whole image to generate shared feature maps
- step2: a pooling layer warps each region of interest into fixed-size per-ROI feature maps
- step3: use fc layers to convert the per-ROI feature maps to per-ROI masks
- the translation-variant property is introduced in the fc layer(s) in the last step
- drawbacks
- the ROI pooling step losses spatial details
- the fc layers over-parametrize the task
- InstanceFCN
- position-sensitive score maps
- sliding windows
- sub-tasks are separated and the solution is not end-to-end
- blind to the object categories:前背景分割
In this work
- extends InstanceFCN
- end-to-end
- fully convolutional
- operates on box proposals instead of sliding windows
- per-ROI computation does not involve any warping or resizing operations
- FCNs do not work for the instance-aware semantic segmentation task
方法
position-sensitive score map
- FCN
- predict a single score map
- predict each pixel’s likelihood score of belonging to each category
- at instance level
- the same pixel can be foreground on one object but background on another
- a single score map per-category is insufficient to distinguish these two cases
- a fully convolutional solution for instance mask proposal
- k x k evenly partitioned cells of object
- thus obtain k x k position-sensitive score maps
- Each score represents 当前像素在当前位置(score map在cells中的位置)上属于某个物体实例的似然得分
- assembling (copy-paste)
- FCN
jointly and simultaneously
- The same set of score maps are shared for the two sub-tasks
- For each pixel in a ROI, there are two tasks:
- detection:whether it belongs to an object bounding box
- segmentation:whether it is inside an object instance’s boundary
- separate:two 1x1 conv heads
- fuse:inside and outside
- high inside score and low outside score:detection+, segmentation+
- low inside score and high outside score:detection+, segmentation-
- low inside score and low outside score:detection-, segmentation-
- detection score
- average pooling over all pixels‘ likelihoods for each class
- max(detection score) represent the object
- segmentation
- softmax(inside, outside) for each pixel to distinguish fg/bg
All the per-ROI components are implemented through convs
- local weight sharing property:a regularization mechanism
- without involving any feature warping, resizing or fc layers
- the per-ROI computation cost is negligible

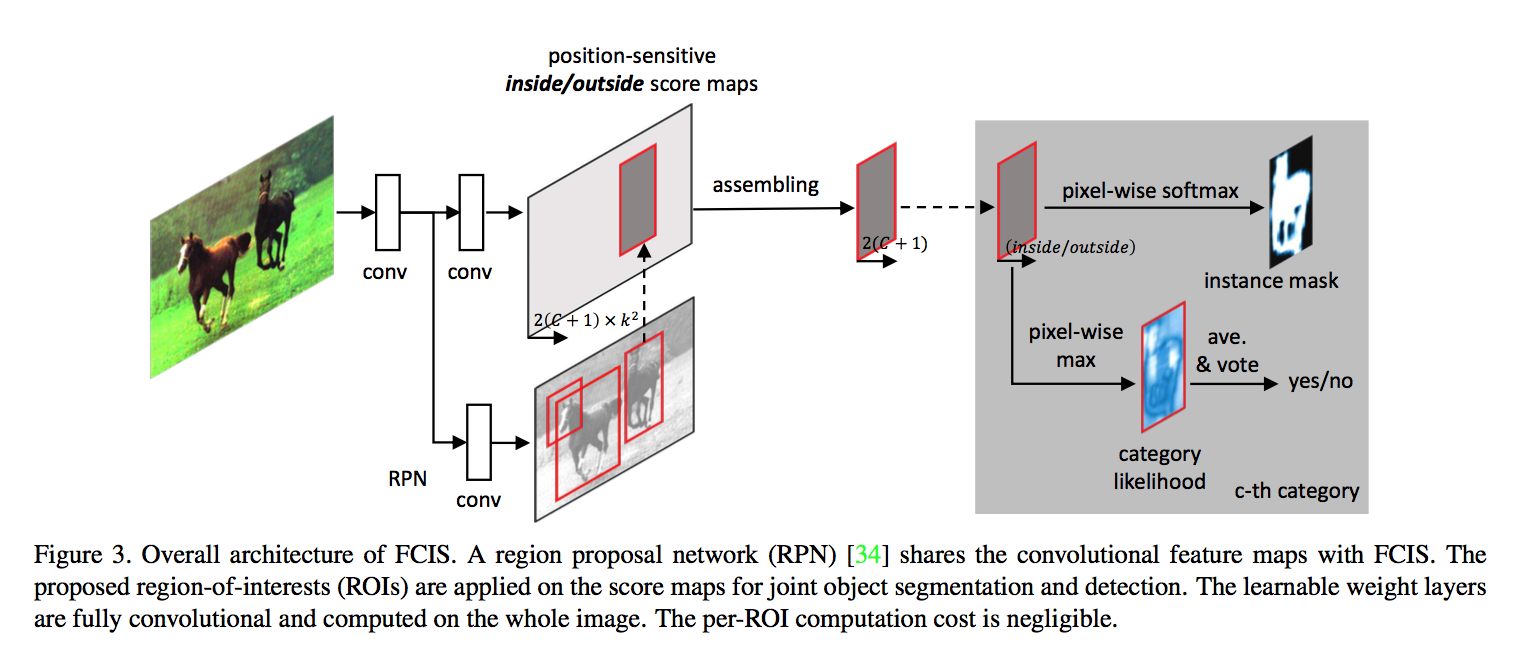
architecture
- ResNet back produce features with 2048 channels
- a 1x1 conv reduces the dimension to 1024
- x16 output stride:conv5 stride is decreased from 2 to 1, the dilation is increased from 1 to 2
- head1:joint det conf & segmentation
- 1x1 conv,generates $2k^2(C+1)$ score maps
- 2 for inside/outside
- $k^2$ for $k^2$个position
- $(C+1)$ for fg/bg
- head2:bbox regression
- 1x1 conv,$4k^2$ channels
- RPN to generate ROIs
- inference
- 300 ROIs
- pass through the bbox regression obtaining another 300 ROIs
- pass through joint head to obtain detection score&fg mask for all categories
- mask voting:每个ROI (with max det score) 只包含当前类别的前景,还要补上框内其他类别背景
- for current ROI, find all the ROIs (from the 600) with IoU scores higher than 0.5
- their fg masks are averaged per-pixel and weighted by the classification score
training
- ROI positive/negative:IoU>0.5
- loss
- softmax detection loss over C+1 categories
- softmax segmentation loss over the gt fg mask, on positive ROIs
- bbox regression loss, , on positive ROIs
- OHEM:among the 300 proposed ROIs on one image, 128 ROIs with the highest losses are selected to back-propagate their error gradients
- RPN:
- 9 anchors
- sharing feature between FCIS and RPN
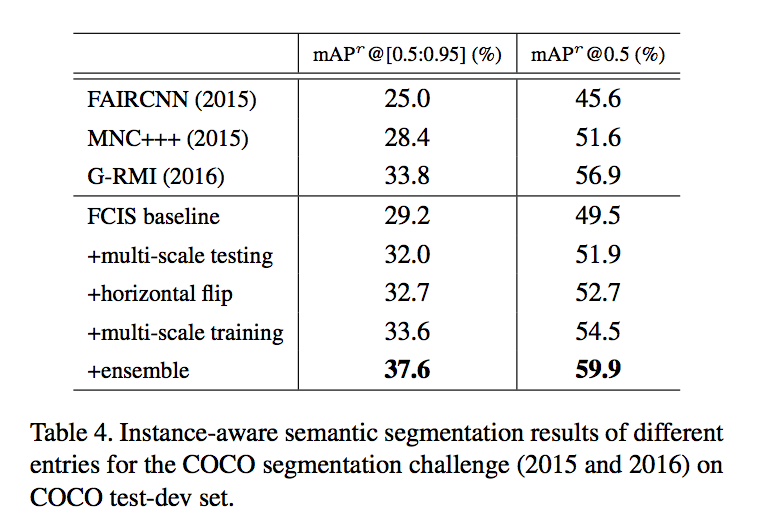
实验
metric:mAP
FCIS (translation invariant):
- set k=1,achieve the worst mAP
- indicating the position sensitive score map is vital for this method
back
- 50-101:increase
- 101-152:saturate
tricks
* r