- [det] RetinaNet: Focal Loss for Dense Object Detection
- [det+instance seg] RetinaMask: Learning to predict masks improves state-of-the-art single-shot detection for free
- [det+semantic seg] Retina U-Net: Embarrassingly Simple Exploitation of Segmentation Supervision for Medical Object Detection
Focal Loss for Dense Object Detection
动机
- dense prediction(one-stage detector)
- focal loss:address the class imbalance problem
- RetinaNet:design and train a simple dense detector
论点
- accuracy trailed
- two-stage:classifier is applied to a sparse set of candidate
- one-stage:dense sampling of possible object locations
- the extreme foreground-background class imbalance encountered during training of dense detectors is the central cause
- loss
- standard cross entropy loss:down-weights the loss assigned to well-classified examples
- proposed focal loss:focuses training on a sparse set of hard examples
- R-CNN系列two-stage framework
- proposal-driven
- the first stage generates a sparse set of candidate object locations
- the second stage classifies each candidate location as one of the foreground classes or as background
- class imbalance:在stage1大部分背景被filter out了,stage2训练的时候强制固定前背景样本比例,再加上困难样本挖掘OHEM
- faster:reducing input image resolution and the number of proposals
- ever faster:one-stage
- one-stage detectors
- One stage detectors are applied over a regular, dense sampling of object locations, scales, and aspect ratios
- dense:regularly sampling(contrast to selection),基于grid以及anchor以及多尺度
- the training procedure is still dominated by easily classified background examples
- class imbalance:通常引入bootstrapping和hard example mining来优化
- Object Detectors
- Classic:sliding-window+classifier based on HOG,dense predict
- Two-stage:selective Search+classifier based on CNN,shared network RPN
- One-stage:‘anchors’ introduced by RPN,FPN
- loss
- Huber loss:down-weighting the loss of outliers (hard examples)
- focal loss:down-weighting inliers (easy examples)
- accuracy trailed
方法
focal loss
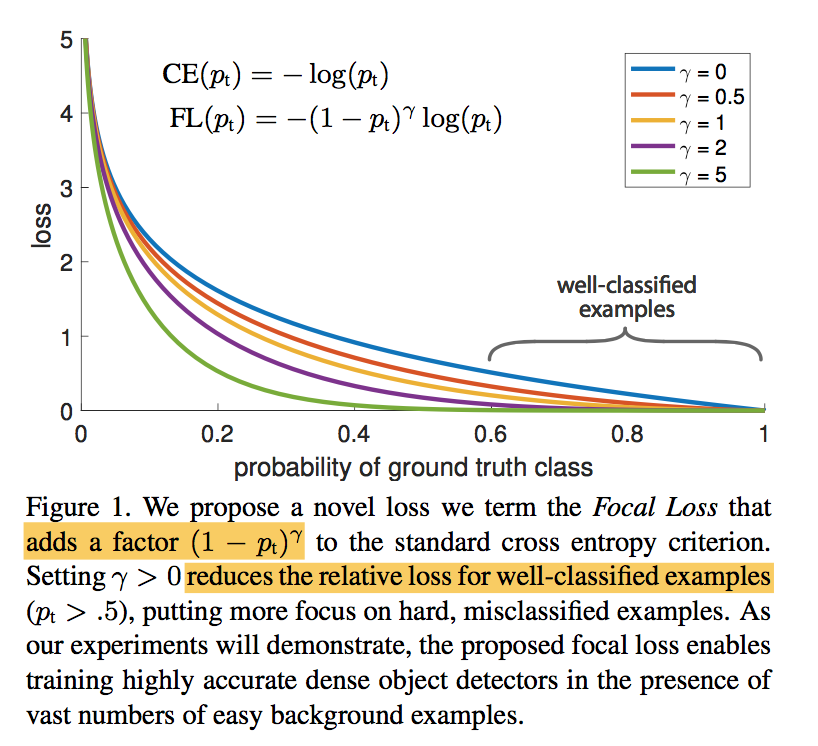
- CE:$CE(p_t)=-log(p_t)$
- even examples that are easily classified ($p_t>0.5$) incur a loss with non-trivial magnitude
- summed CE loss over a large number of easy examples can overwhelm the rare class
- WCE:$WCE(p_t)=-\alpha_t log(p_t)$
- balances the importance of positive/negative examples
- does not differentiate between easy/hard examples
FL:$FL(p_t)=-\alpha_t(1-p_t)^\gamma log(p_t)$
- as $\gamma$ increases the modulating factor is likewise increased
- $\gamma=2$ works best in our experiments
two-stage detectors通常不会使用WCE或FL
- cascade stage会过滤掉大部分easy negatives
- 第二阶段训练会做biased minibatch sampling
- Online Hard Example Mining (OHEM)
- construct minibatches using high-loss examples
- scored by loss + nms
- completely discards easy examples
- CE:$CE(p_t)=-log(p_t)$
RetinaNet
- compose:backbone network + two task-specific subnetworks
- backbone:convolutional feature map over the entire input image
- subnet1:object classification
subnet2:bounding box regression
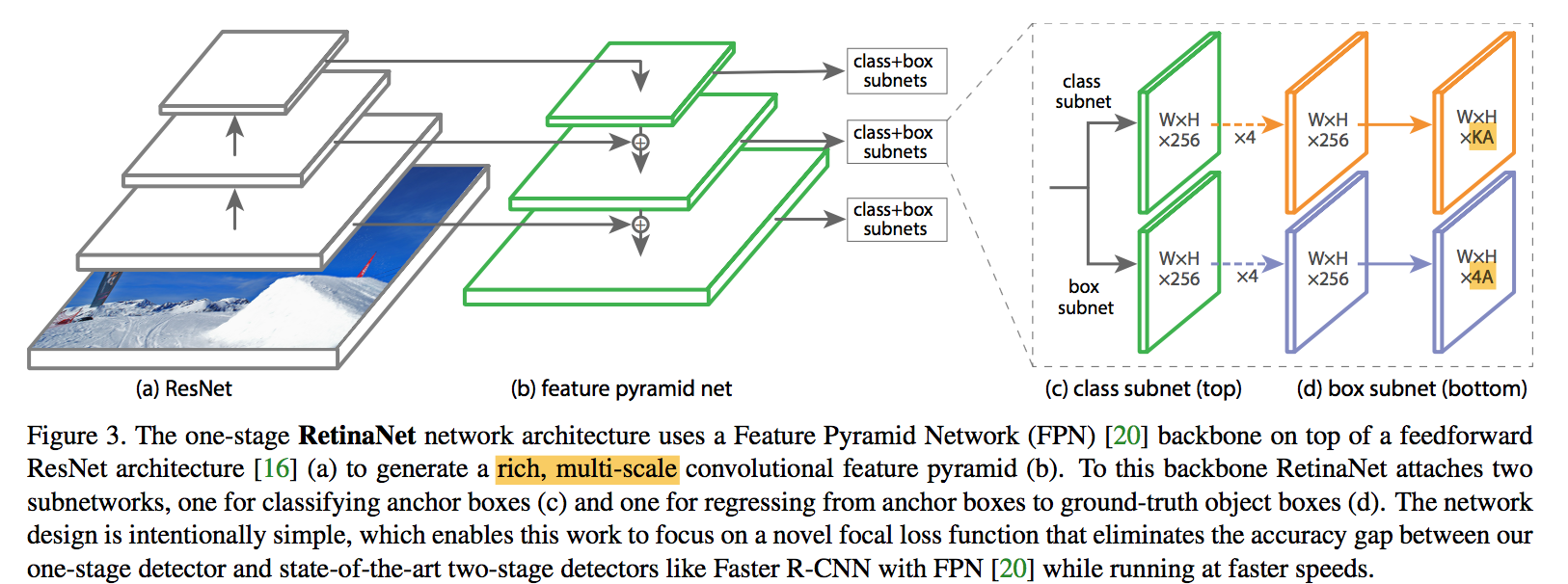
ResNet-FPN backbone
- rich, multi-scale feature pyramid,二阶段的RPN也用了FPN
- each level can be used for detecting objects at a different scale
- P3 - P7:8x - 128x downsamp
- FPN channels:256
anchors
- anchor ratios:{1:2, 1:1, 2:1},长宽比
- anchor scales:{$2^0$, $2^\frac{1}{3}$, $2^\frac{2}{3}$},大小,同一个scale的anchor,面积相同,都是size*size,长宽通过ratio求得
- anchor size per level:[32, 64, 128, 256, 512],基本的正方形anchor的边长
- total anchors per level:A=9
- KA:each anchor is assigned a length K one-hot vector of classification targets
- 4A:and a 4-vector of box regression targets
- anchors are assigned to ground-truth object boxes using an intersection-over-union (IoU) threshold of 0.5
- anchors are assigned background if their IoU is in [0, 0.4)
- anchor is unassigned between [0.4, 0.5), which is ignored during training
- each anchor is assigned to at most one object box
for each anchor
classification targets:one-hot vector
box regression targets:each anchor和其对应的gt box的offset
rpn offset:中心点、宽、高
$$t_x = (x - x_a) / w_a\\
t_y = (y - y_a) / h_a\\t_w = log(w/ w_a)\\
t_h = log(h/ h_a)$$
or omitted if there is no assignment
【QUESTION】所谓的anchor state {-1:ignore, 0:negative, 1:positive} 是针对cls loss来说的,相当于人为丢弃了一部分偏向中立的样本,这对分类效果有提升吗??
classification subnet
for each spatial position,for each anchor,predict one among K classes,one-hot
input:C channels feature map from FPN
structure:four 3x3 conv + ReLU,each with C filters
head:3x3 conv + sigmoid,with KA filters
share across levels
not share with box regression subnet
focal loss:
- sum over all ~100k anchors
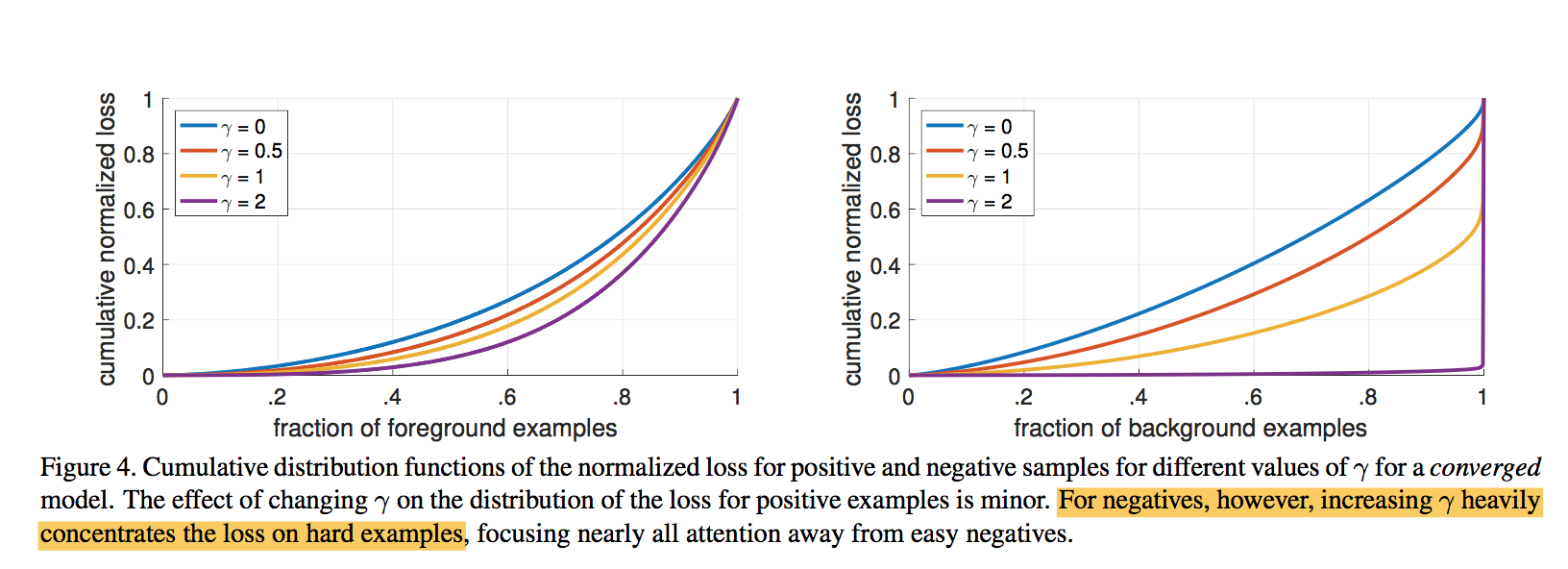
* and normalized by the number of anchors assigned to a ground-truth box * 因为是sum,所以要normailize,norm项用的是number of assigned anchors(这是包括了前背景?) * vast majority of anchors are **easy negatives** and receive negligible loss values under the focal loss(确实包含背景框) * $\alpha$:In general $alpha$ should be decreased slightly as $\gamma$ is increased strong effect on negatives:FL can effectively discount the effect of easy negatives, focusing all attention on the hard negative examples
box regression subnet
- class-agnostic bounding box regressor
- sum over all ~100k anchors
- same structure:four 3x3 conv + ReLU,each with C filters
* head:4A linear outputs * L1 loss
inference
keep top 1k predictions per FPN level
* all levels are merged and non-maximum suppression with a threshold of 0.5train
- initialization:
- cls head bias initialization,encourage more foreground prediction at the start of training
- prevents the large number of background anchors from generating a large, destabilizing loss
- initialization:
network design
anchors
* one-stage detecors use fixed sampling grid to generate position * use multiple ‘anchors’ at each spatial position to cover boxes of various scales and aspect ratios * beyond 6-9 anchors did not shown further gains in AP * speed/accuracy trade-off * outperforms all previous methods * bigger resolution bigger AP * Retina-101-600与ResNet101-FRCNN的AP持平,但是比他快gradient:
- 梯度有界
the derivative is small as soon as $x_t > 0$
<img src="RetinaNet/gradient.png" width="70%;" />
RetinaMask: Learning to predict masks improves state-of-the-art single-shot detection for free
动机
- improve single-shot detectors to the same level as current two-stage techniques
- improve on RetinaNet
- integrating instance mask prediction
- adaptive loss
- additional hard examples
- Group Normalization
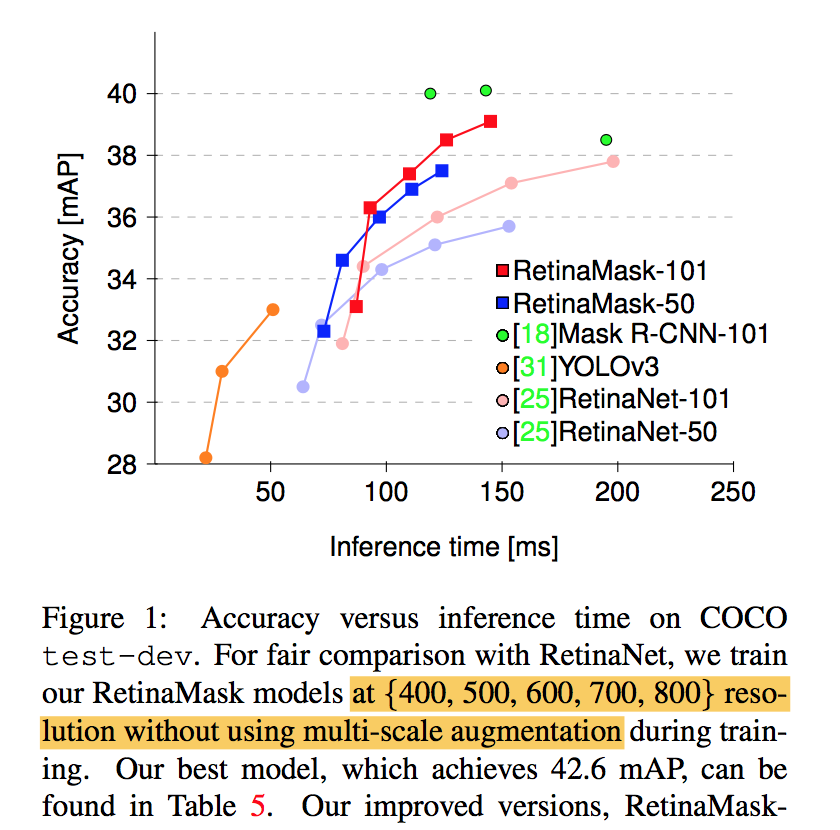
same computational cost as the original RetinaNet but more accurate:同样的参数量级比orgin RetinaNet准,整体的参数量级大于yolov3,acc快要接近二阶段的mask RCNN了
论点
- part of improvements of two-stage detectors is due to architectures like Mask R-CNN that involves multiple prediction heads
- additional segmentation task had only been added to two-stage detectors in the past
- two-stage detectors have the cost of resampling(ROI-Align) issue:RPN之后要特征对齐
- add addtional heads in training keeps the structure of the detector at test time unchanged
- potential improvement directions
- data:OHEM
- context:FPN
- additional task:segmentation branch
- this paper’s contribution
- add a mask prediction branch
- propose a new self-adjusting loss function
- include more of positive samples—>those with low overlap
方法
best matching policy
- speical case:outlier gt box,跟所有的anchor iou都不大于0.5,永远不会被当作正样本
- use best matching anchor with any nonzero overlap to replace the threshold
self-adjusting Smooth L1 loss
bbox regression
smooth L1:
- L1 loss is used beyond $\beta$ to avoid over-penalizing outliers
the choice of control point is heuristic and is usually done by hyper parameter search
self-adjusting control point
running mean & variance
minibatch update:m=0.9
control point:$[0, \hat \beta]$ clip to avoid unstable
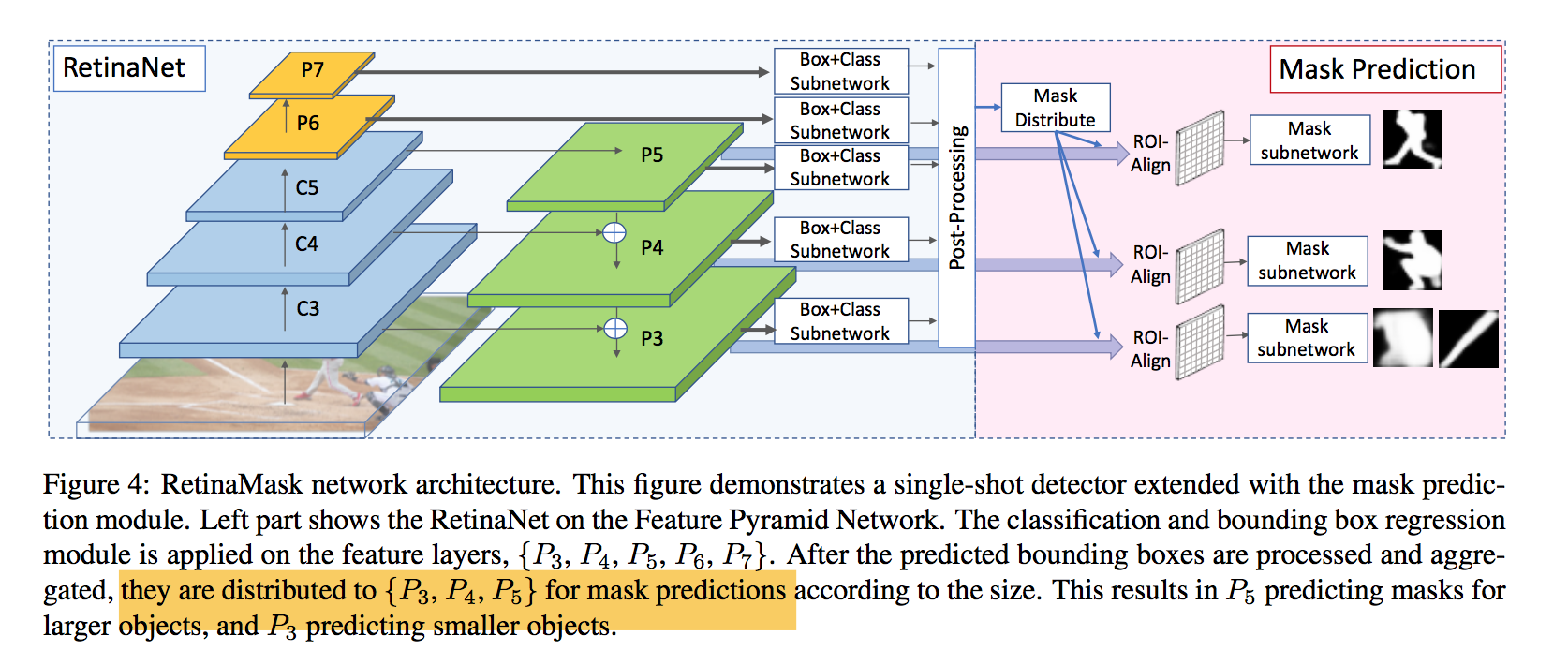
mask module
detection predictions are treated as mask proposals
extract the top N scored predictions
distribute the mask proposals to sample features from the appropriate layers
- $k_0=4$,如果size小于224*224,proposal会被分配给P3,如果大于448*448,proposal会被分配给P5
- using more feature layers shows no performance boost
architecture
- r50&r101 back:freezing all of the Batch Nor- malization layers
- fpn feature channel:256
- classification branch
- 4 conv layers:conv3x3+relu,channel256
- head:conv3x3+sigmoid,channel n_anchors*n_classes
- regression branch
- 4 conv layers:conv3x3+relu,channel256
- head:conv3x3,channel n_anchors*4
- aggregate the boxes to the FPN layers
- ROI-Align yielding 14x14 resolution features
mask head
- 4 conv layers:conv3x3
- a single transposed convolutional layer:convtranspose2d 2x2,to 28*28 resolution
- prediction head:conv1x1
training
- min side & max side:800&1333
- limited GPU:reduce the batch size,increasing the number of training iterations and reducing the learning rate accordingly
- positive/ignore/negative:0.5,0.4
focal loss for classification
gaussian initialization
$\alpha=0.25, \lambda=2.0$
$FL=-\alpha_t(1-p_t)^\lambda log(p_t)$
gamma项控制的是简单样本的衰减速度,alpha项控制的是正负样本比例,可以默认值下正样本的权重是0.25,负样本的权重是0.75,和想象中的给正样本更多权重不一样,因为alpha和gamma是耦合起来作用的,(可能检测场景下困难的负样本相比于正样本更少?背景就是比前景好学?不确定不确定。。。)
- self-adjusting L1 loss for box regression
- limit running params:[0, 0.11]
- mask loss
- top-100 predicted boxes + ground truth boxes
inference
- box confidence threshold 0.05
- nms threshold 0.4
- use top-50 boxes for mask prediction
Retina U-Net: Embarrassingly Simple Exploitation of Segmentation Supervision for Medical Object Detection
动机
- localization
- pixel-level predict
- ad-hoc heuristics when mapping back to object-level scores
- semantic segmentation
- auxiliary task
- overall one-stage
- leveraging available supervision signals
- localization
论点
- monitoring pixel-wise predictions are clinically required
- medical annotations is commonly performed in pixel- wise
- full semantic supervision
- fully exploiting the available semantic segmentation signal results in significant performance gains
- one-stage
- explicit scale variance enforced by the resampling operation in two-stage detectors is not helpful in the medical domain
- two-stage methods
- predict proposal-based segmentations
- mask loss is only evaluated on cropped proposal:no context gradients
- ROI-Align:not suggested in medical image
- depends on the results of region proposal:serial vs parallel
- gradients of the mask loss do not flow through the entire model
方法
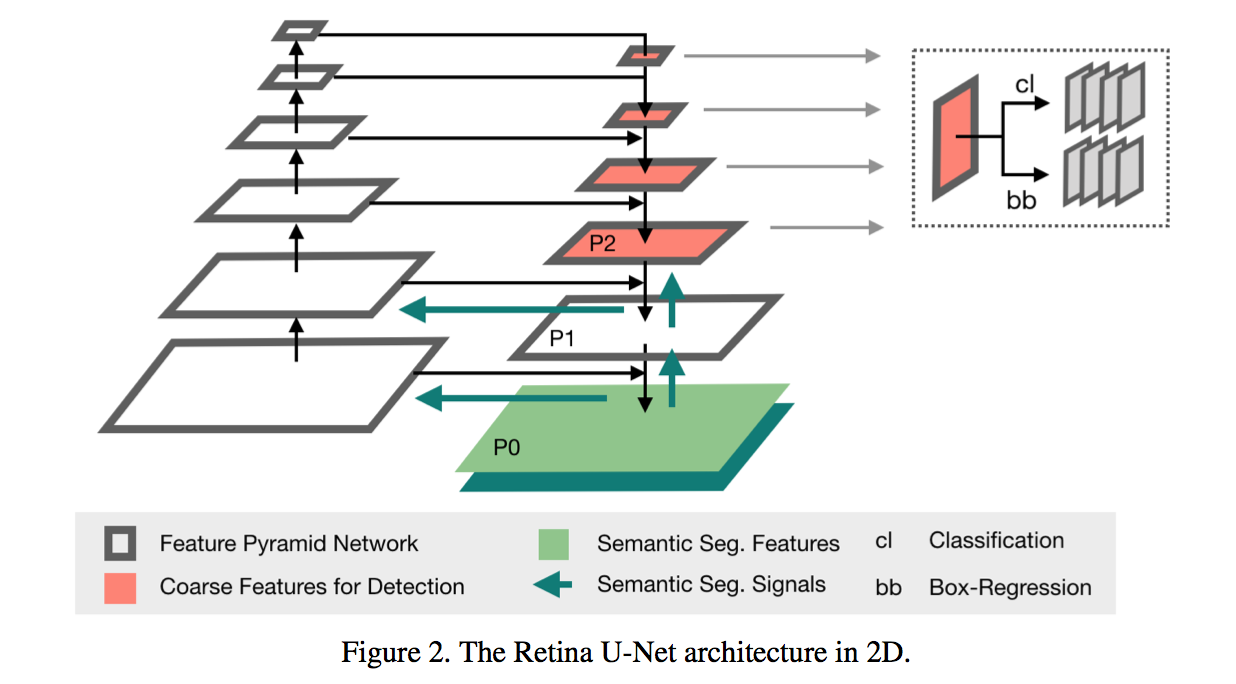
model
- back:
- ResNet50
- fpn:
- shift p3-p6 to p2-p5
- change sigmoid to softmax
- 3d head channels:64
- anchor size:$\{P_2: 4^2, P_3: 8^2,, P_4: 16^2,, P_5: 32^2\}$
- 3d z-scale:{1,2,4,8},考虑到z方向的low resolution
- segmentation supervision
- p0 & p1
- with skip connections
- without detection heads
- segmentation loss calculates on p0 logits
- dice + ce
h
- back:
weighted box clustering
patch crop
tiling strategies & model ensembling causes multi predictions per location
nms选了一类中score最大的box,然后抑制所有与它同类的IoU大于一定阈值的box
weighted box作用于这一类所有的box,计算一个融合的结果
- coordinates confidence:$o_c = \frac{\sum c_i s_i w_i}{\sum s_i w_i}$
score confidence:$o_s = \frac{\sum s_i w_i}{\sum w_i + n_{missing * \overline w}}$
$w_i$:$w=f a p$
- overlap factor f:与highest scoring box的overlap
- area factor a:higher weights to larger boxes,经验
- patch center factor p:相对于patch center的正态分布
- score confidence的分母上有一个down-weight项$n_{missing}$:基于prior knowledge预期prediction的总数得到
论文给的例子让我感觉好比nms的点
- 一个cluster里面一类最终就留下一个框:解决nms一类大框包小框的情况
- 这个location上prediction明显少于prior knowledge的类别confidence会被显著拉低:解决一个位置出现大概率假阳框的情况