动机
- embrace shorter connections
- the feature-maps of all preceding layers are used as inputs
- advantages
- alleviate vanishing-gradient
- encourage feature reuse
- reduce the number of parameters
论点
- Dense
- each layer obtains additional inputs from all preceding lay- ers and passes on its own feature-maps to all subsequent layers
- feature reuse
- combine features by concatenating:the summation in ResNet may impede the information flow in the network
- information preservation
- id shortcut/additive identity transformations
fewer params
- DenseNet layers are very narrow
- add only a small set of feature-maps to the “collective knowledge”
gradients flow
- each layer has direct access to the gradients from the loss function
- have regularizing effect
- Dense
方法
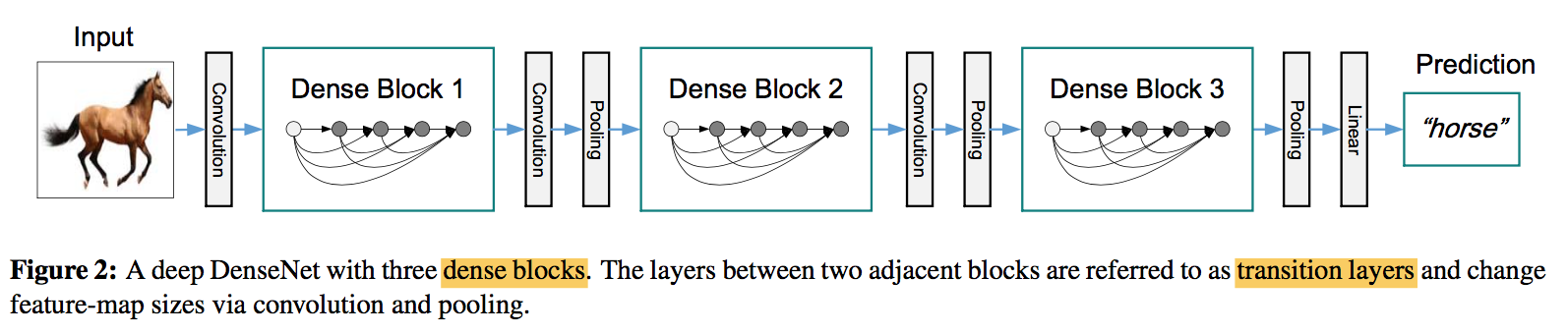
architecture
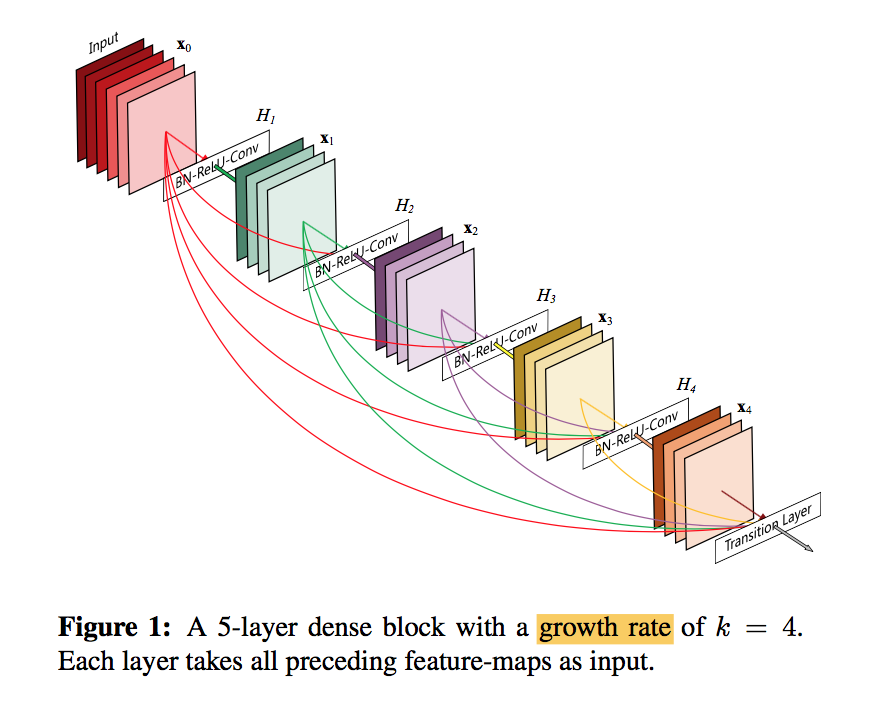
- dense blocks
- concat
- BN-ReLU-3x3 conv
- $x_l = H_l([x_0, x_1, …, x_{l-1}])$
- transition layers
- change the size of feature-maps
- BN-1x1 conv-2x2 avg pooling
growth rate k
- $H_l$ produces feature- maps
- narrow:e.g., k = 12
- One can view the feature-maps as the global state of the network
- The growth rate regulates how much new information each layer contributes to the global state
bottleneck —- DenseNet-B
- in dense block stage
- 1x1 conv reduce dimension first
- number of channels:4k
compression —- DenseNet-C
- in transition stage
- reduce the number of feature-maps
- number of channels:$\theta k$
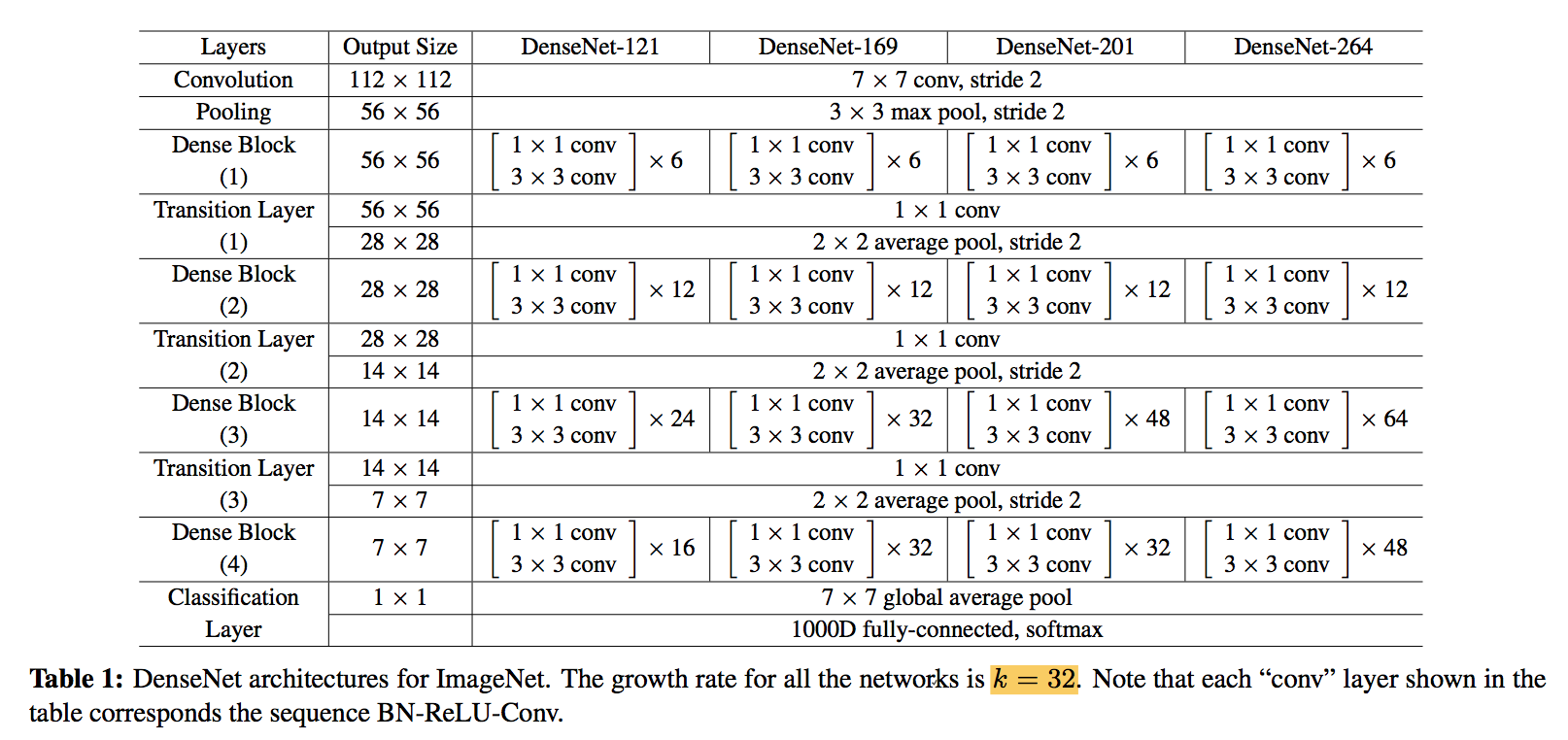
structure configurations
- 1st conv channels:第一层卷积通道数
- number of dense blocks
- L:dense block里面的layer数
- k:growth rate
- B:bottleneck 4k
- C:compression 0.5k
- dense blocks
讨论
concat replace sum:
- seemingly small modification lead to substantially different behaviors of the two network architectures
- feature reuse:feature can be accessed anywhere
- parameter efficient:同样参数量,test acc更高,同样acc,参数量更少
deep supervision:classifiers attached to every hidden layer
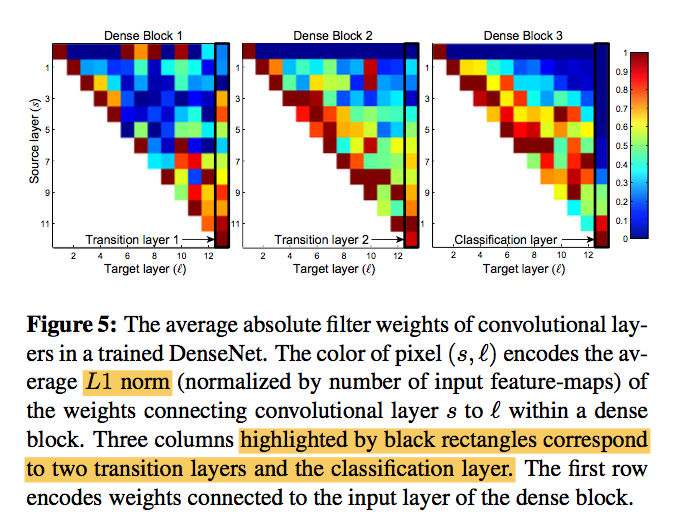
weight assign
- All layers spread their weights over multi inputs (include transition layers)
- least weight are assigned to the transition layer, indicating that transition layers contain many redundant features, thus can be compressed
- overall there seems to be concentration towards final feature-maps, suggesting that more high-level features are produced late in the network