overview
papers
[resnet] ResNet: Deep Residual Learning for Image Recognition
[resnext] ResNext: Aggregated Residual Transformations for Deep Neural Networks
[resnest] ResNeSt: Split-Attention Networks
[revisiting resnets] Revisiting ResNets: Improved Training and Scaling Strategies
ResNext: Aggregated Residual Transformations for Deep Neural Networks
动机
- new network architecture
- new building blocks with the same topology
- propose cardinality
- increasing cardinality is able to improve classification accuracy
- is more effective than going deeper or wider
- classification task
论点
VGG & ResNets:
- stacking building blocks of the same topology
- deeper
- reduces the free choices of hyper-parameters
Inception models
- split-transform-merge strategy
- split:1x1conv spliting into a few lower-dimensional embeddings
- transform:a set of specialized filters
merge:concat
approach the representational power of large and dense layers, but at a considerably lower computational complexity
- modules are customized stage-by-stage
our architecture
- adopts VGG/ResNets’ repeating layers
- adopts Inception‘s split-transform-merge strategy
- aggregated by summation
cardinality:the size of the set of transformations(split path数)
- 多了1x1 conv的计算量
- 少了3x3 conv的计算量
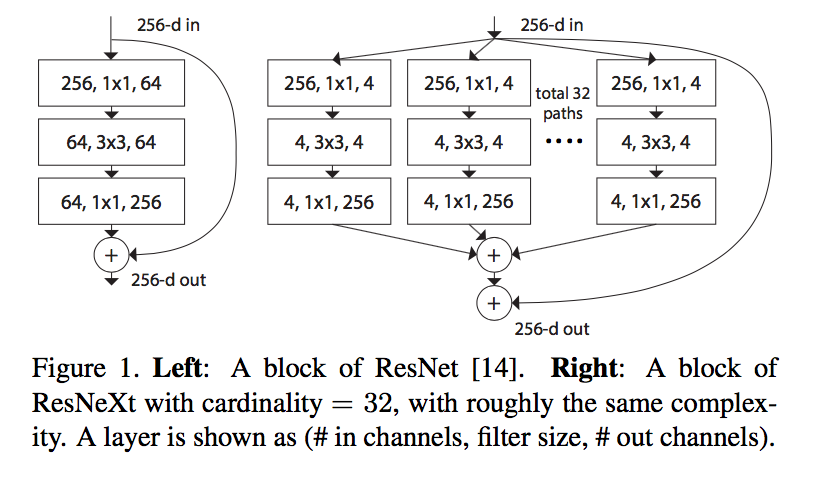
要素
- Multi-branch convolutional blocks
- Grouped convolutions:通道对齐,稀疏连接
- Compressing convolutional networks
- Ensembling
方法
architecture
- a template module
- if producing spatial maps of the same size, the blocks share the same hyper-parameters (width and filter sizes)
when the spatial map is downsampled by a factor of 2, the width of the blocks is multiplied by a factor of 2
grouped convolutions:第一个1x1和3x3conv的width要根据C进行split
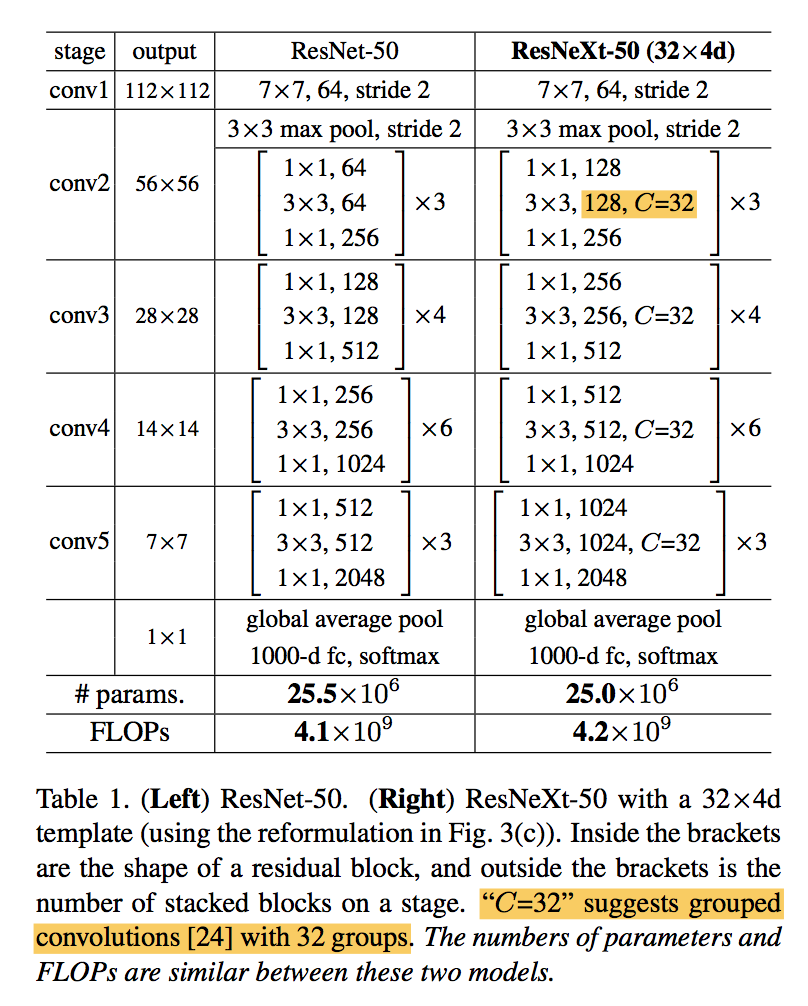
equivalent blocks
- BN after each conv
- ReLU after each BN except the last of block
- ReLU after add
r
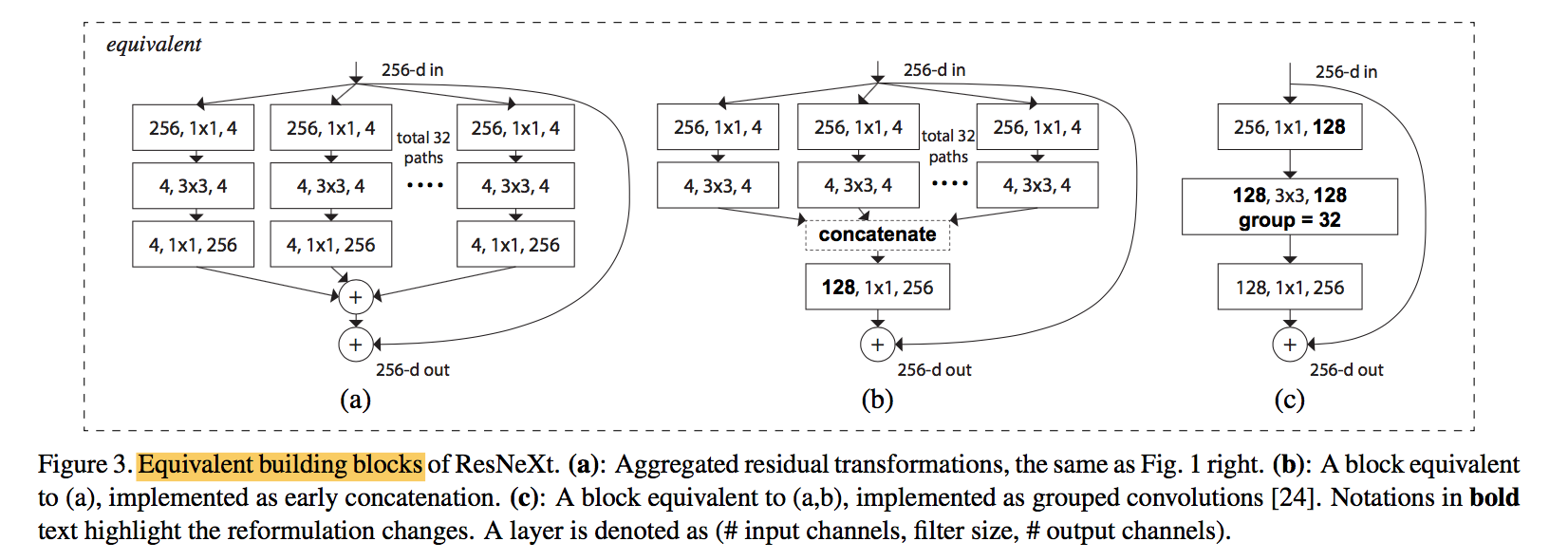
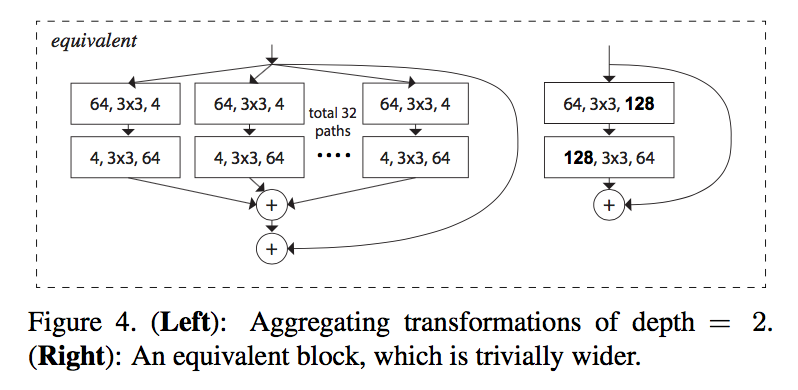
Model Capacity
improve accuracy when maintaining the model complexity and number of parameters
adjust the width of bottleneck, the according C to maintain capacity:C=1的时候退化成ResNet block

ResNeSt: Split-Attention Networks
动机
- propose a modular Split-Attention block
- enables attention across feature-map groups
- preserve the overall ResNet structure for downstream applications such as object detection and semantic segmentation
- prove improvement on detection & segmentation tasks
论点
- ResNet
- simple and modular design
- limited receptive-field size and lack of cross-channel interaction
- image classification networks have focused more on group or depth-wise convolution
- do not transfer well to other tasks
- isolated representations cannot capture cross-channel relationships
- a versatile backbone
- improving performance across multiple tasks at the same time
- a network with cross-channel representations is desirable
- a Split-Attention block
- divides the feature-map into several groups (along the channel dimension)
- finer-grained subgroups or splits
- weighted combination
- featuremap attention mechanism:NiN’s 1x1 conv
- Multi-path:GoogleNet
- channel-attention mechanism:SE-Net
结构上,全局上看,模仿ResNext,引入cardinality和group conv,局部上看,每个group内部继续分组,然后模仿SK-Net,融合多个分支的split-attention,大group之间concat,而不是ResNext的add,再经1x1 conv调整维度,add id path

- ResNet
方法
Split-Attention block
enables feature-map attention across different feature-map groups
within a block:controlled by cardinality
within a cardinal group:introduce a new radix hyperparameter R indicating the number of splits
split-attention
- 多个in-group branch的input输入进来
- fusion:先做element-wise summation
- channel-wise global contextual information:做global average pooling
- 降维:Dense-BN-ReLU
- 各分支Dense(the attention weight function):学习各自的重要性权重
- channel-wise soft attention:对全部的dense做softmax
- 加权:原始的各分支input与加权的dense做乘法
- 和:加权的各分支add
r=1:退化成SE-blockaverage pooling

shortcut connection
- for blocks with a strided convolution or combined convolution-with-pooling can be applied to the id
concat
average pooling downsampling
- for dense prediction tasks:it becomes essential to preserve spatial information
- former work tend to use strided 3x3 conv
- we use an average pooling layer with 3x3 kernel
- 2x2 average pooling applied to strided shortcut connection before 1x1 conv
Revisiting ResNets: Improved Training and Scaling Strategies
动机
disentangle the three aspects
- model architecture
- training methodology
- scaling strategies
improve ResNets to SOTA
- design a family of ResNet architectures, ResNet-RS
- use improved training and scaling strategies
- and combine minor architecture changes
- 在ImageNet上打败efficientNet
在半监督上打败efficientNet-noisystudent
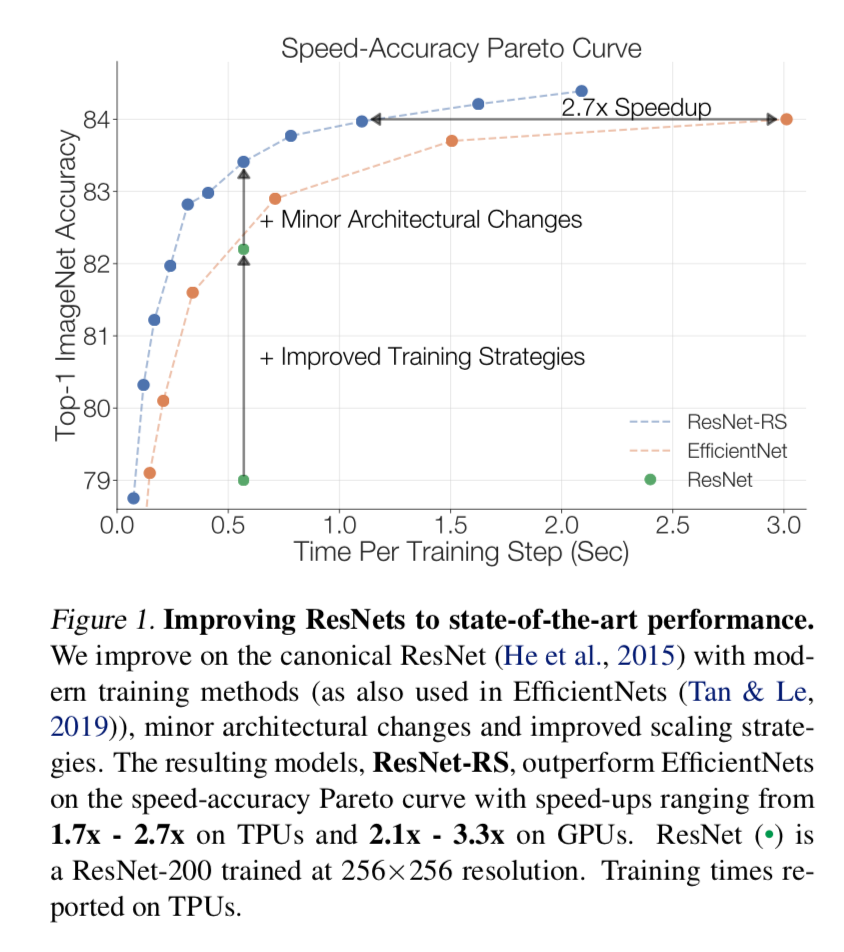
论点
- ImageNet上榜大法
- Architecture
- 人工系列:AlexNet,VGG,ResNet,Inception,ResNeXt
- NAS系列:NasNet-A,AmoebaNet-A,EfficientNet
- Training and Regularization Methods
- regularization methods
- dropout,label smoothing,stochastic depth,dropblock,data augmentation
- significantly improve generalization when training more epochs
- training
- learning rate schedules
- regularization methods
- Scaling Strategies
- model dimension:width,depth,resolution
- efficientNet提出的均衡增长,在本文中shows sub-optimal for both resnet and efficientNet
- Additional Training Data
- pretraining on larger dataset
- semi-supervised
- Architecture
- the performance of a vision model
- architecture:most research focus on
- training methods and scaling strategy:less publicized but critical
- unfair:使用modern training method的新架构与使用dated methods的老网络直接对比
- we focus on the impact of training methods and scaling strategies
- training methods:
- We survey the modern training and regularization techniques
- 发现引入其他正则方法的时候降低一点weight decay有好处
- scaling strategies:
- We offer new perspectives and practical advice on scaling
- 可能出现过拟合的时候就加depth,否则先加宽
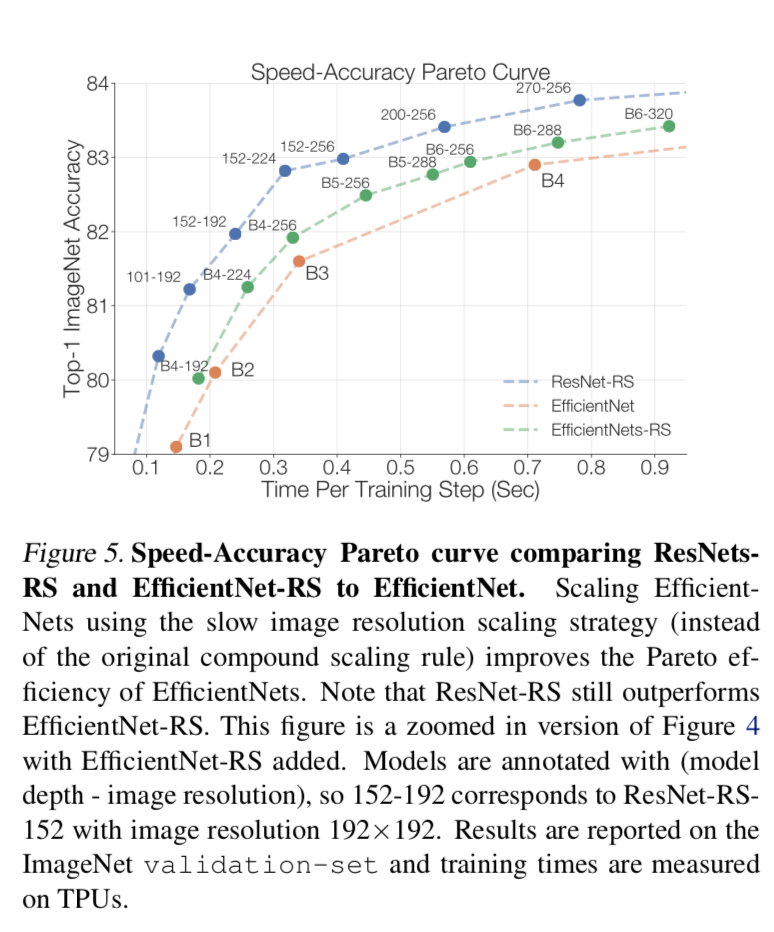
- resolution慢点增长,more slowly than prior works
- 从acc图可以看到:我们的scaling strategies与网络结构的lightweight change正交,是additive的
- training methods:
- re-scaled ResNets, ResNet-RS
- 仅improve training & scaling strategy就能大幅度涨点
- combine minor architectural changes进一步涨点
- ImageNet上榜大法
方法
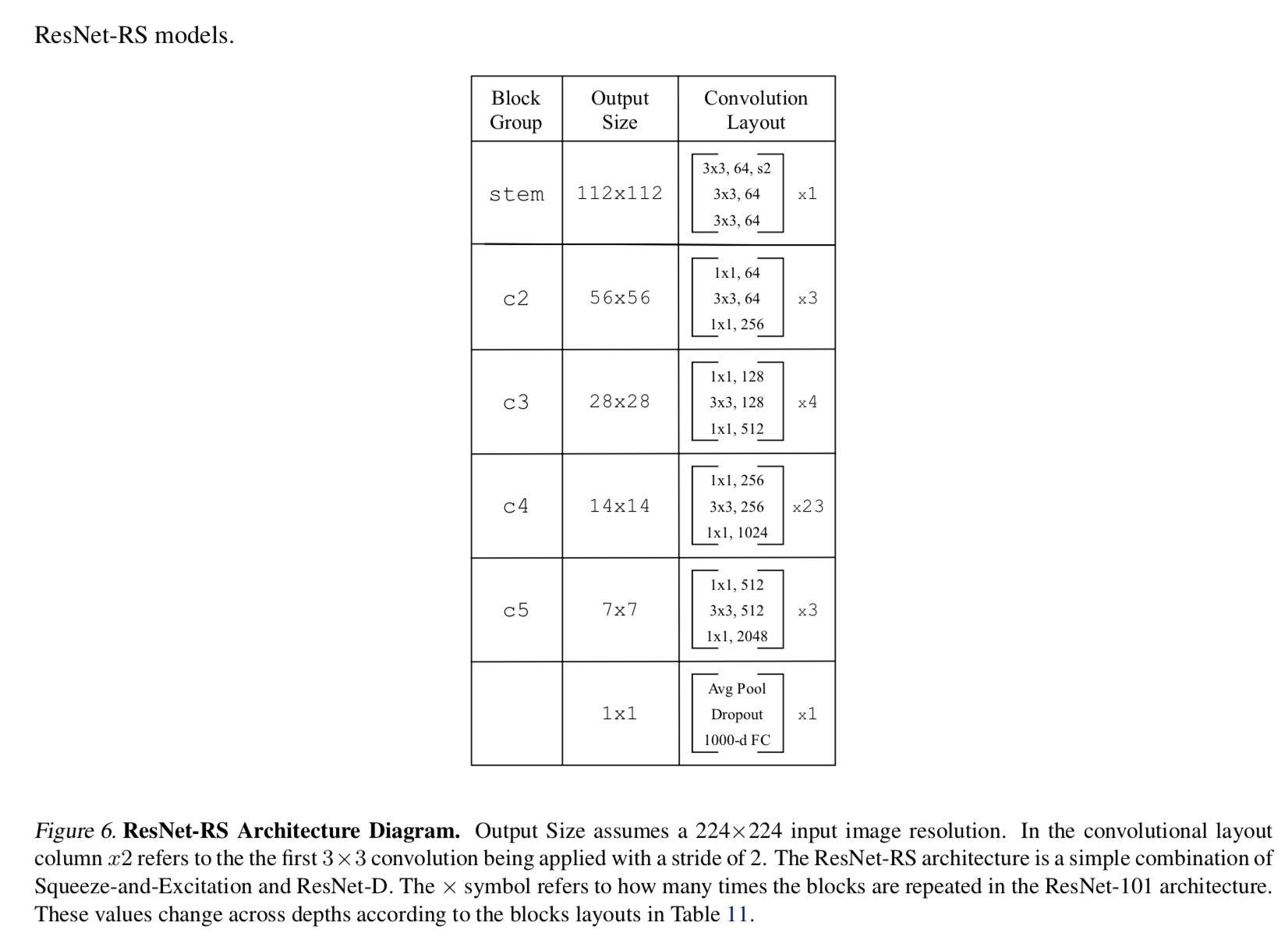
architecture
- use ResNet with two widely used architecture changes
- ResNet-D
- stem的7x7conv换成3个3x3conv
- stem的maxpooling去掉,每个stage的首个3x3conv负责stride2
- residual path上前两个卷积的stride互换(在3x3上下采样)
- id path上的1x1 s2conv替换成2x2 s2的avg pooling+1x1conv
SE in bottleneck
- use se-ratio of 0.25
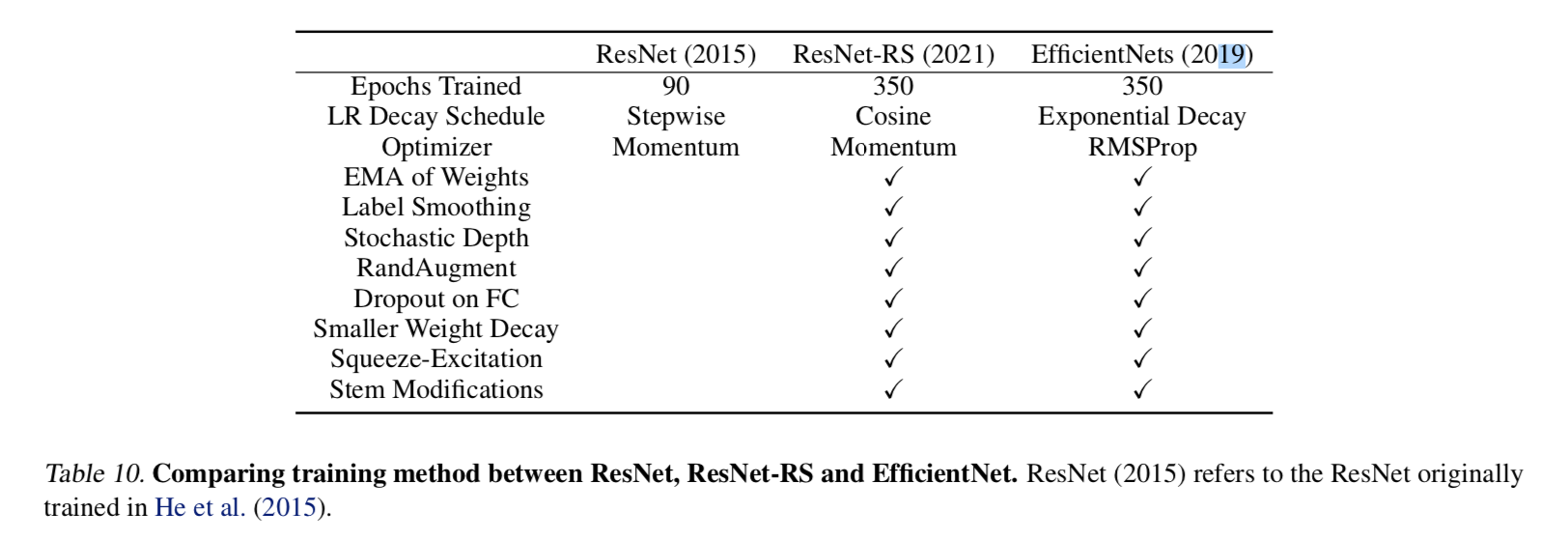
training methods
- match the efficientNet setup
- train for 350 epochs
- use cosine learning rate instead of exponential decay
- RandAugment instead of AutoAugment
- use Momentum optimizer instead of RMSProp
- regularization
- weight decay
- label smoothing
- dropout
- stochastic depth
data augmentation
- we use RandAugment
- EfficientNet use AutoAugment which slightly outperforms RandAugment
hyper:
- droprate
- increase the regularization as the model size increase to limit overfitting
- label smoothing = 0.1
- weight decay = 4e-5
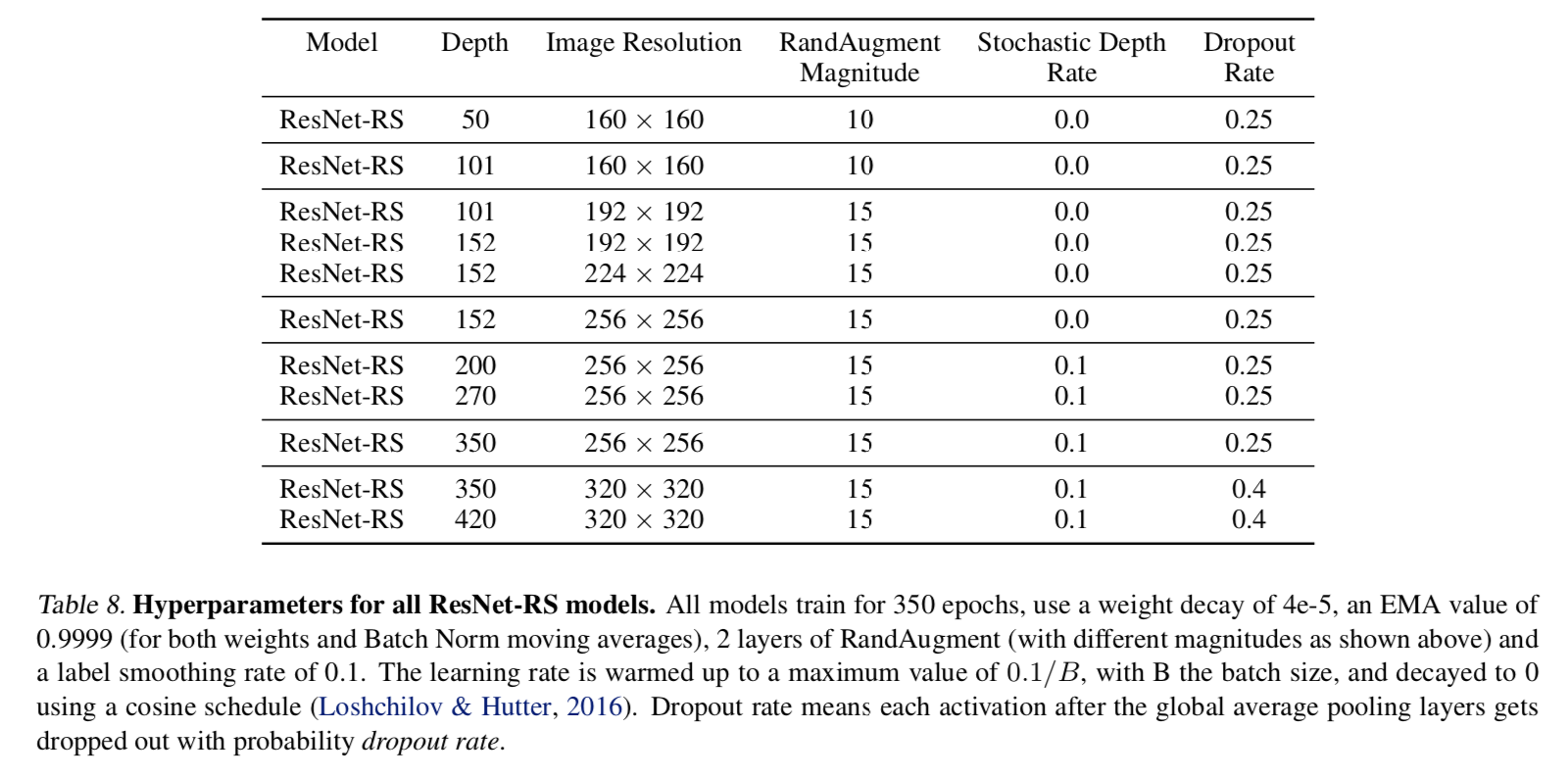
- match the efficientNet setup
improved training methods
additive study
- 总体上看都是additive的
- increase training epochs在添加regularization methods的前提下才不hurt,否则会overfitting
dropout在不降低weight decay的情况下会hurt

weight decay
- 少量/没有regularization methods的情况下:大weight decay防止过拟合,1e-4
- 多/强regularization methods的情况下:适当减小weight decay能涨点,4e-5
improved scaling strategies
search space
- width multiplier:[0.25, 0.5, 1.0, 1.5, 2.0]
- depth:[26, 50, 101, 200, 300, 350, 400]
- resolution:[128, 160, 224, 320, 448]
- increase regularization as model size increase
- observe 10/100/350 epoch regime
we found that the best scaling strategies depends on training regime
strategy1:scale depth
- Depth scaling outperforms width scaling for longer epoch regimes
- width scaling is preferable for shorter epoch regimes
- scaling width可能会引起overfitting,有时候会hurt performance
- depth scaling引入的参数量也比width小
strategy2:slow resolution scaling
- efficientNets/resNeSt lead to very large images
our experiments:大可不必
实验