综述
感受野
除了卷积和池化,其他层并不影响感受野大小
感受野与卷积核尺寸kernel_size和步长stride有关
递归计算:
其中$cur_RF$是当前层(start from 1),$kernel_size$、$stride$是当前层参数,$N_RF$是上一层的感受野。
Understanding the Effective Receptive Field in Deep Convolutional Neural Networks
动机
effective receptive field
the effect of nonlinear activations, dropout, sub-sampling and skip connections on it
论点
- it is critical for each output pixel to have a big receptive field, such that no important information is left out when making the prediction
- deeper network:increase the receptive field size linearly
- Sub-sampling:increases the receptive field size multiplicatively
- it is easy to see that pixels at the center of a receptive field have a much larger impact on an output:前向传播的时候,中间位置的像素点有更多条path通向output
方法看不懂直接看结论
dropout does not change the Gaussian ERF shape
Subsampling and dilated convolutions turn out to be effective ways to increase receptive field size quickly
Skip-connections make ERFs smaller
ERFs are Gaussian distributed
- uniformly和随机初始化都是perfect Gaus- sian shapes
加上非线性激活函数以后是near Gaussian shapes

with different nonlinearities

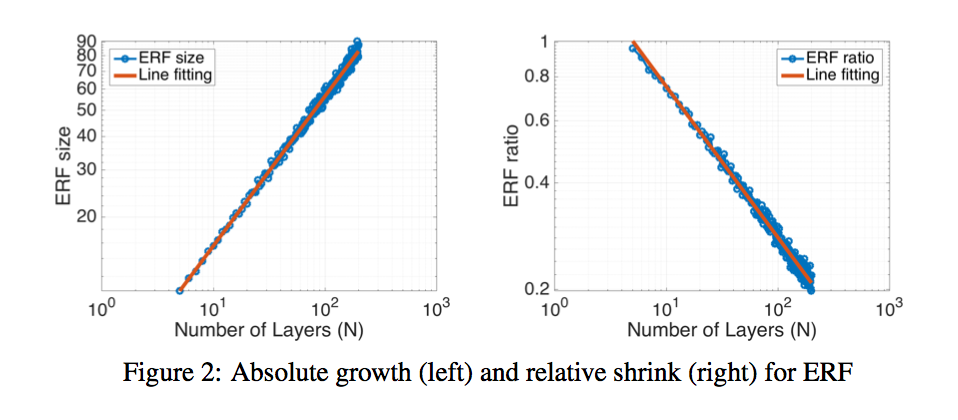
$\sqrt n$ absolute growth and $1/\sqrt n$ relative shrinkage:RF是随着layer线性增长的,ERF在log上0.56的斜率,约等于$\sqrt n$
Subsampling & dilated convolution increases receptive field
- The reference baseline is a convnet with 15 dense convolution layers
- Subsampling:replace 3 of the 15 convolutional layers with stride-2 convolution
dilated:replace them with dilated convolution with factor 2,4 and 8,rectangular ERF shape

evolves during training
- as the networks learns, the ERF gets bigger, and at the end of training is significantly larger than the initial ERF
- classification
- 32*32 cifar 10
- theoretical receptive field of our network is actually 74 × 74
- segmentation
- CamVid dataset
- the theoretical receptive field of the top convolutional layer units is quite big at 505 × 505
实际的ERF都很小,都没到原图大小

increase the effective receptive field
- New Initialization:
- makes the weights at the center of the convolution kernel to have a smaller scale, and the weights on the outside to be larger
- 30% speed-up of training
- 其他效果不明显
- Architecturalchanges
- sparsely connect each unit to a larger area
- dilated convolution or even not grid-like
- New Initialization:
g