综述
图像特征的提取能力是CNN的核心能力,而SE block可以起到为CNN校准采样的作用。
根据感受野理论,特征矩阵主要来自于样本的中央区域,处在边缘位置的酒瓶的图像特征很大概率会被pooling层抛弃掉。而SE block的加入就可以通过来调整特征矩阵,增强酒瓶特征的比重,提高它的识别概率。

- [SE-Net] Squeeze-and-Excitation Networks
- [SC-SE] Concurrent Spatial and Channel ‘Squeeze & Excitation’ in Fully Convolutional Networks
- [CMPE-SE] Competitive Inner-Imaging Squeeze and Excitation for Residual Network
SENet: Squeeze-and-Excitation Networks
动机
- prior research has investigated the spatial component to achieve more powerful representations
- we focus on the channel relationship instead
- SE-block:adaptively recalibrates channel-wise feature responses by explicitly modelling interdependencies between channels
- enhancing the representational power
- in a computationally efficient manner
论点
- stronger network:
- deeper
- NiN-like bocks
- cross-channel correlations in prior work
- mapped as new combinations of features through 1x1 conv
- concentrated on the objective of reducing model and computational complexity
- In contrast, we found this mechanism
- can ease the learning process
- and significantly enhance the representational power of the network
- Attention
- Attention can be interpreted as a means of biasing the allocation of available computational resources towards the most informative components
- Some works provide interesting studies into the combined use of spatial and channel attention
- Attention can be interpreted as a means of biasing the allocation of available computational resources towards the most informative components
- stronger network:
方法
SE-block
The channel relationships modelled by convolution are inherently implicit and local
we would like to provide it with access to global information
squeeze:using global average pooling
excitation:nonlinear & non-mutually-exclusive using sigmoid
bottleneck:a dimensionality-reduction layer $W_1$ with reduction ratio $r$ and ReLU and a dimensionality-increasing layer $W_2$
$s = F_{ex}(z,W) = \sigma (W_2 \delta(W_1 z))$
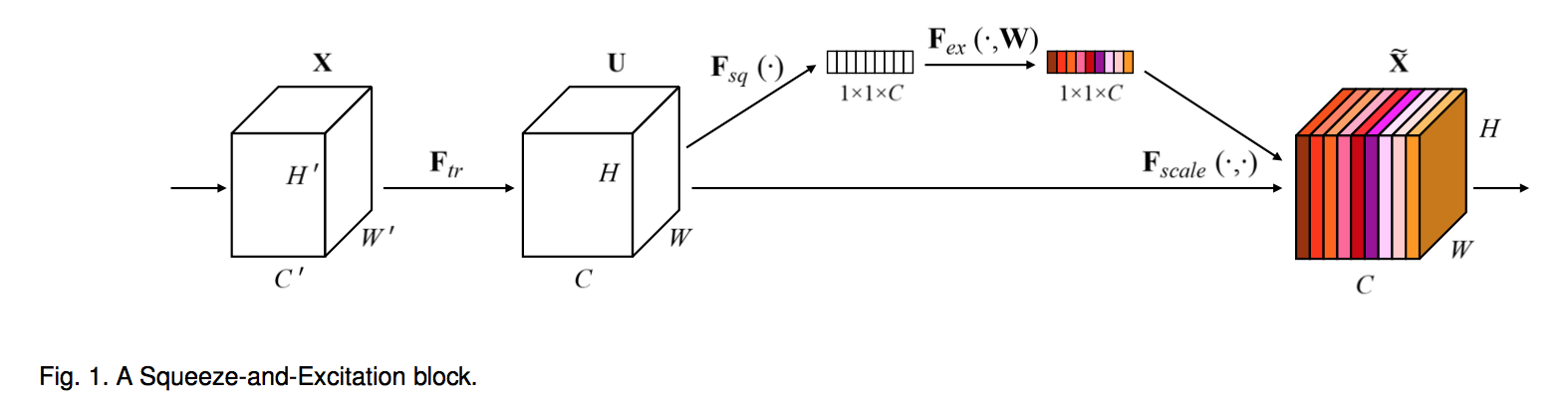
integration
- insert after the non-linearity following each convolution
- inception:take the transformation $F_{tr}$ to be an entire Inception module
residual:take the transformation $F_{tr}$ to be the non-identity branch of a residual module
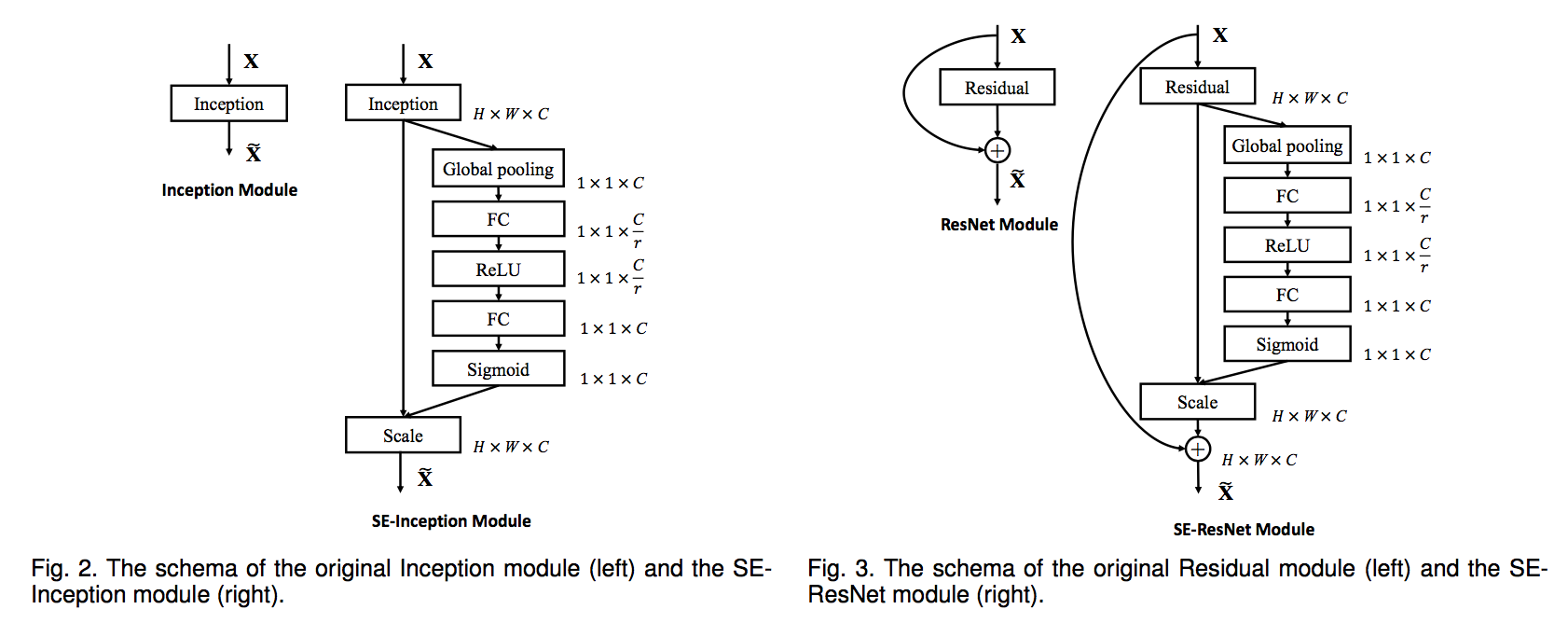
model and computational complexity
- ResNet50 vs. SE-ResNet50:0.26% relative increase GFLOPs approaching ResNet10’s accuracy
- the additional parameters result solely from the two FC layers, among which the final stage FC claims the majority due to being performed across the greatest number of channels
- the costly final stage of SE blocks could be removed at only a small cost in performance
ablations
- FC
- removing the biases of the FC layers in the excitation facilitates the modelling of channel dependencies
- reduction ratio
- performance is robust to a range of reduction ratios
- In practice, using an identical ratio throughout a network may not be optimal due to the distinct roles performed by different layers
- squeeze
- global average pooling vs. global max pooling:average pooling slightly better
- excitation
- Sigmoid vs. ReLU vs. tanh:
- tanh:slightly worse
- ReLU:dramatically worse
- Sigmoid vs. ReLU vs. tanh:
- stages
- each stages brings benefits
- combination make even better
- integration strategy
- fairly robust to their location, provided that they are applied prior to branch aggregation
- inside the residual unit:fewer channels, fewer parameters, comparable accuracy
- FC
- primitive understanding
- squeeze
- the use of global information has a significant influence on the model performance
- excitation
- the distribution across different classes is very similar at the earlier layers (general features)
- the value of each channel becomes much more class-specific at greater depth
- SE_5_2 exhibits an interesting tendency towards a saturated state in which most of the activations are close to one
- SE_5_3 exhibits a similar pattern emerges over different classes, up to a modest change in scale
- suggesting that SE_5_2 and SE_5_3 are less important than previous blocks in providing recalibration to the network (thus can be removed)
- squeeze
APPENDIX
- 在ImageNet上SOTA的模型是SENet-154,top1-err是18.68,被标记在了efficientNet论文的折线图上
- SE-ResNeXt-152(64x4d)
- input=(224,224):top1-err是18.68
- input=320/299:top1-err是17.28
- further difference
- each bottleneck building block的第一个1x1 convs的通道数减半
- stem的第一个7x7conv换成了3个连续的3x3 conv
- 1x1的s2 conv换成了3x3的s2 conv
- fc之前添加dropout layer
- label smoothing
- 最后几个training epoch将BN层的参数冻住,保证训练和测试的参数一致
- 64 GPUs,batch size=2048(32 per GPU)
- initial lr=1.0
- SE-ResNeXt-152(64x4d)
- 在ImageNet上SOTA的模型是SENet-154,top1-err是18.68,被标记在了efficientNet论文的折线图上
SC-SE: Concurrent Spatial and Channel ‘Squeeze & Excitation’ in Fully Convolutional Networks
动机
- image segmentation task 上面SE-Net提出来主要是针对分类
- three variants of SE modules
- squeezing spatially and exciting channel-wise (cSE)
- squeezing channel-wise and exciting spatially (sSE)
- concurrent spatial and channel squeeze & excitation (scSE)
- integrate within three different state-of-the- art F-CNNs (DenseNet, SD-Net, U-Net)
论点
- F-CNNs have become the tool of choice for many image segmentation tasks
- core:convolutions that capturing local spatial pattern along all input channels jointly
- SE block factors out the spatial dependency by global average pooling to learn a channel specific descriptor (later refered to as cSE /channel-SE)
- while for image segmentation, we hypothesize that the pixel-wise spatial information is more informative
- thus we propose sSE(spatial SE) and scSE(spatial and channel SE)
can be seamlessly integrated by placing after every encoder and decoder block
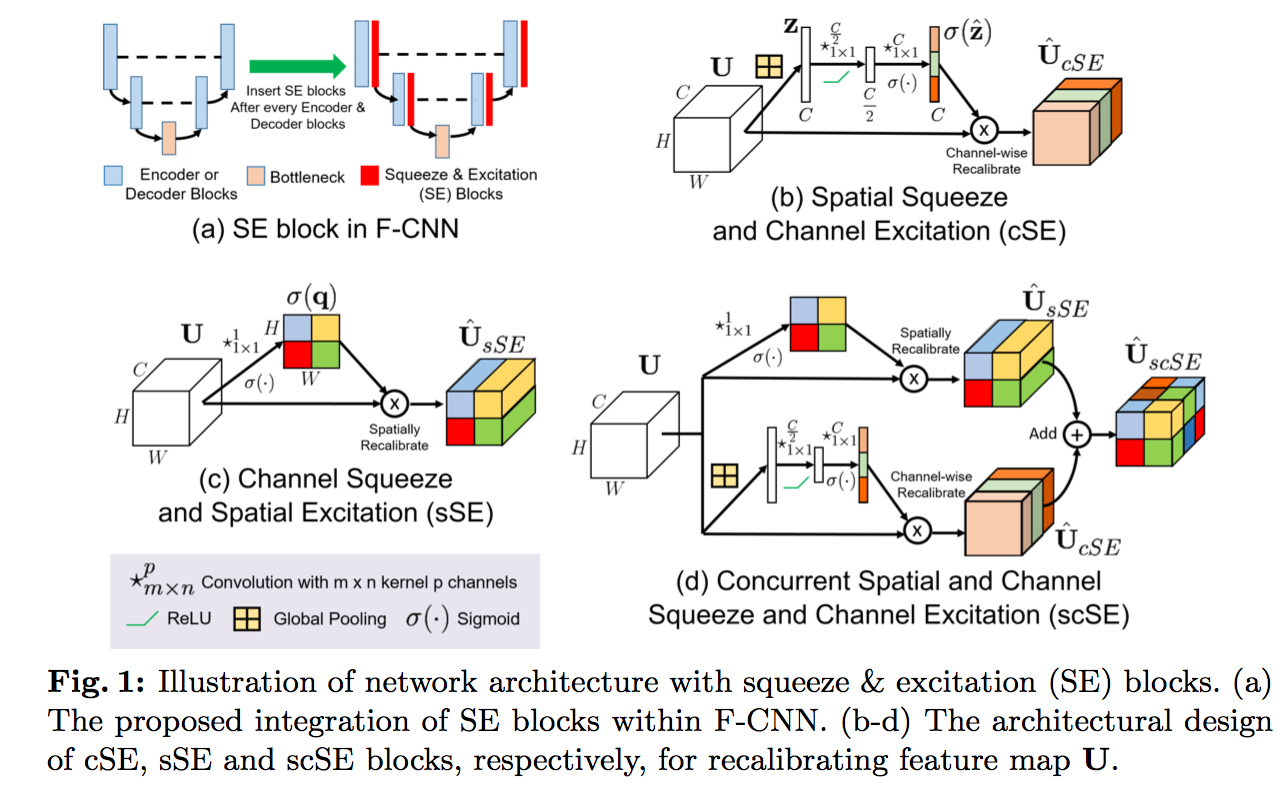
方法
- cSE
- GAP:embeds the global spatial information into a vector
- FC-ReLU-FC-Sigmoid:adaptively learns the importance
- recalibrate
- sSE
- 1x1 conv:generating a projection tensor representing the linearly combined representation for all channels C for a spatial location (i,j)
- Sigmoid:rescale
- recalibrate
- scSE
- by element-wise addition
- encourages the network to learn more meaningful feature maps ———- relevant both spatially and channel-wise
- cSE
实验
F-CNN architectures:
- 4 encoder blocks, one bottleneck layer, 4 decoder blocks and a classification layer
- class imbalance:median frequency balancing ce
dice cmp:scSE > sSE > cSE > vanilla
小区域类别的分割,观察到使用cSE可能会差于vanilla: might have got overlooked by only exciting the channels
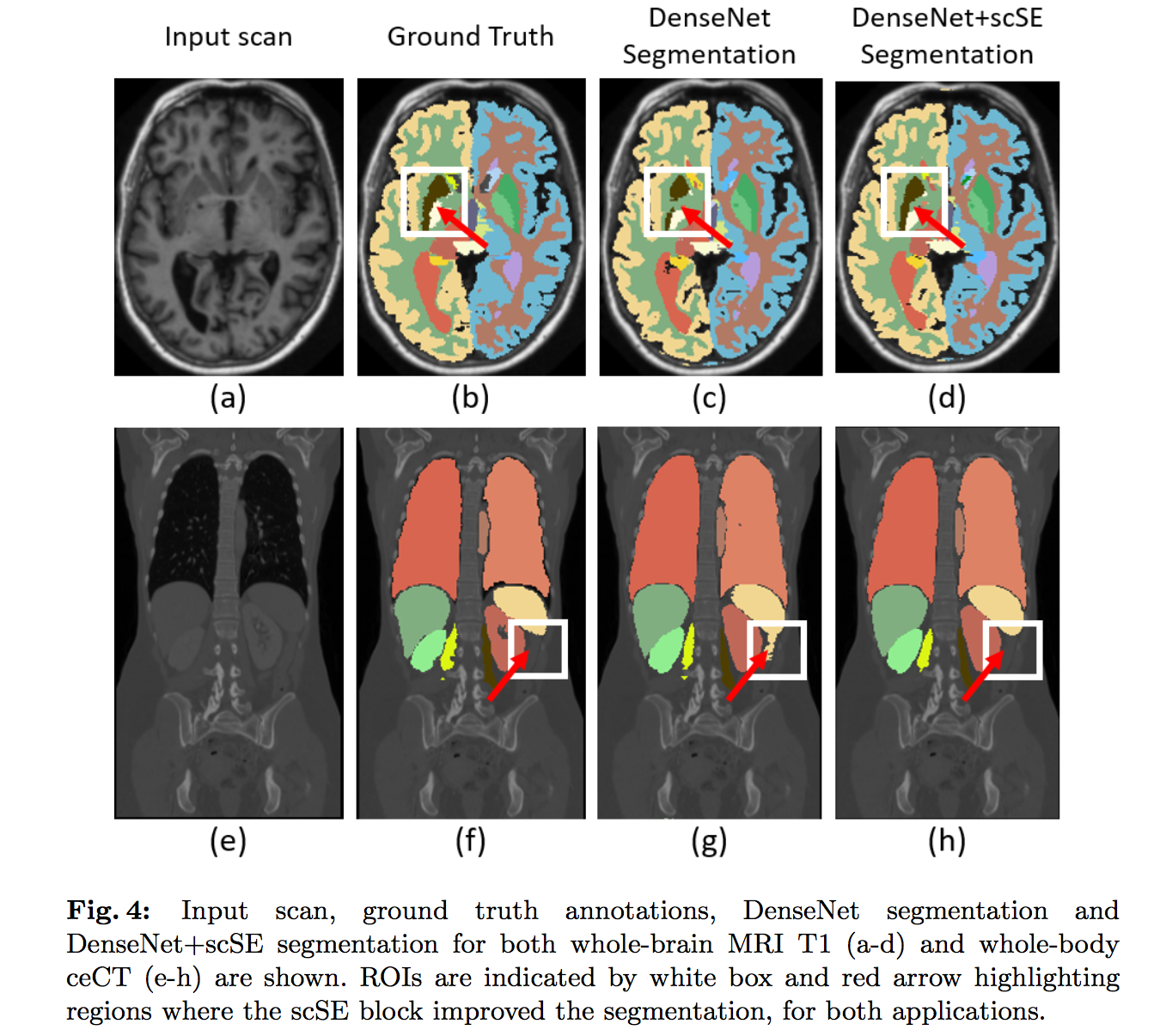
定性分析:
- 一些under segmented的地方,scSE improves with the inclusion
一些over segmented的地方,scSE rectified the result
Competitive Inner-Imaging Squeeze and Excitation for Residual Network
- 动机
- for residual network
- the residual architecture has been proved to be diverse and redundant
- model the competition between residual and identity mappings
- make the identity flow to control the complement of the residual feature maps
论点
- For analysis of ResNet, with the increase in depth, the residual network exhibits a certain amount of redundancy
with the CMPE-SE mechanism, it makes residual mappings tend to provide more efficient supplementary for identity mappings
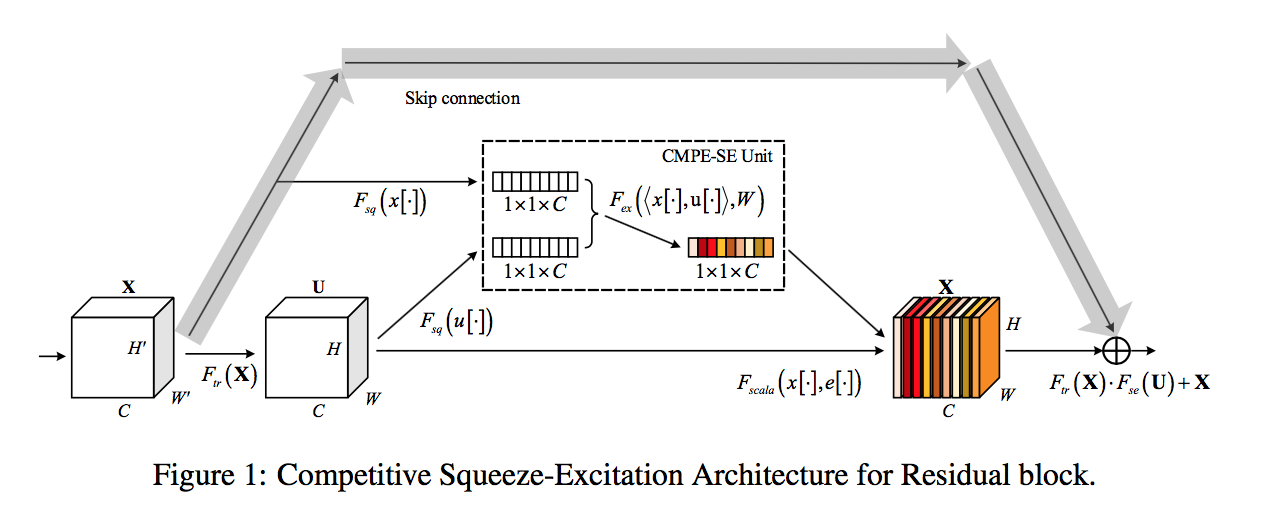
方法
主要提出了三种变体:
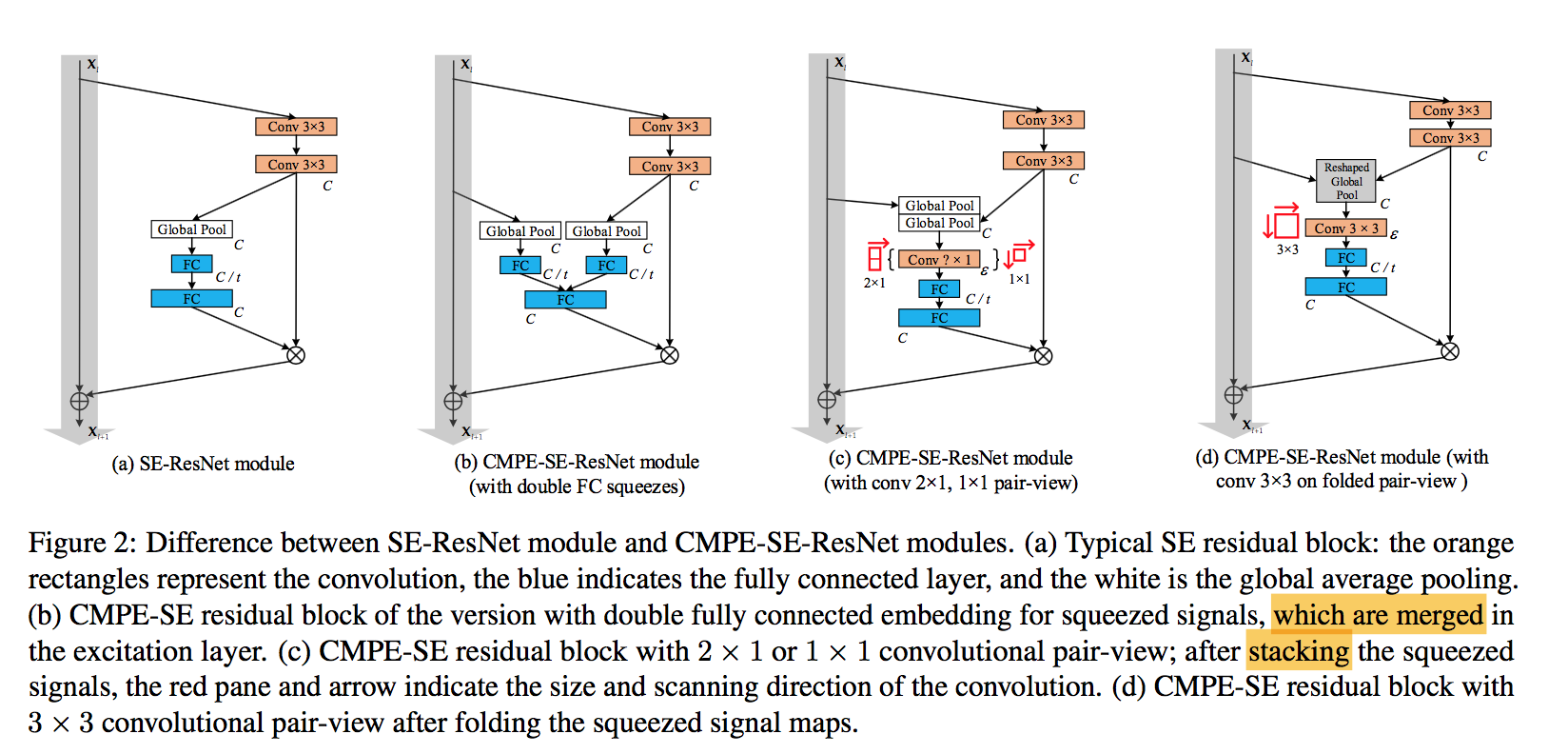
第一个变体:
- 两个分支id和res分别GAP出一个vector,然后fc reduct by ratio,然后concat,然后channel back
- Implicitly, we can believe that the winning of the identity channels in this competition results in less weights of the residual channels
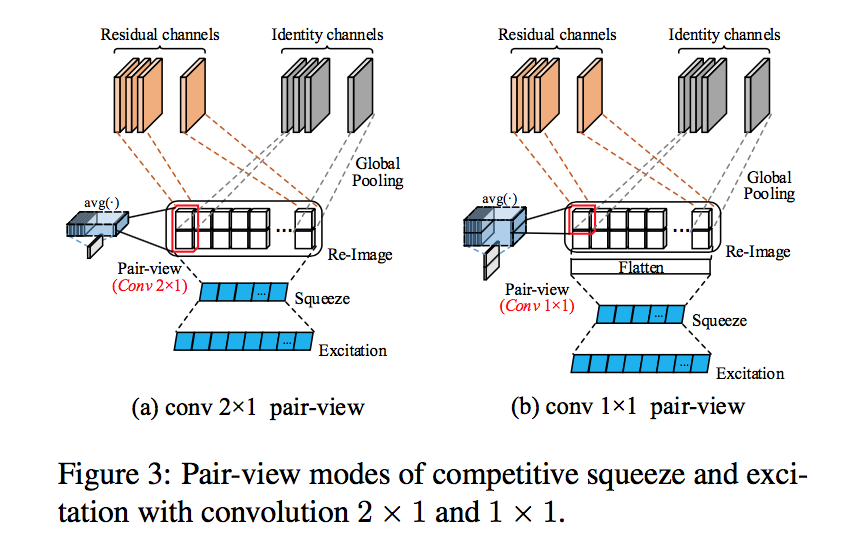
第二个变体:
两种方案
- 2x1 convs:对上下相应位置的元素求avg
- 1x1 convs:对全部元素求avg,然后flatten
第三个变体:
两边的channel-wise vector叠起来,然后reshape成矩阵形式,然后3x3 conv,然后flatten
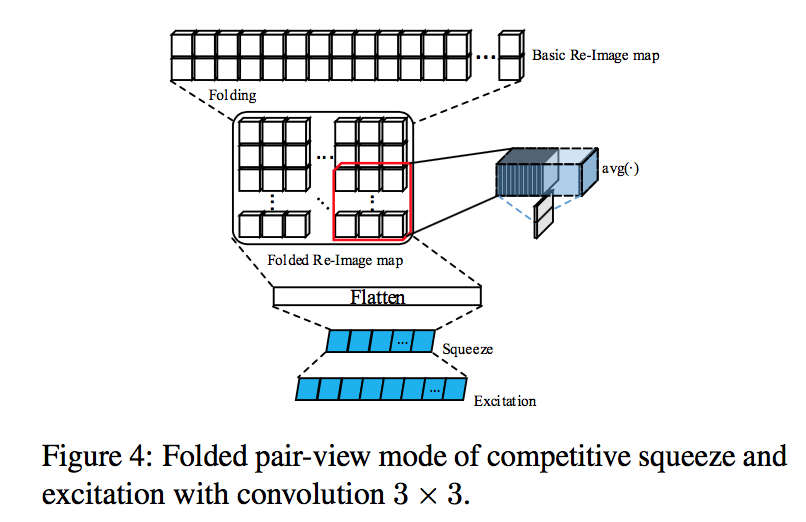
比较扯,不浪费时间分析了。