preview
动机
- 计算力有限
- 模型压缩/使用小模型
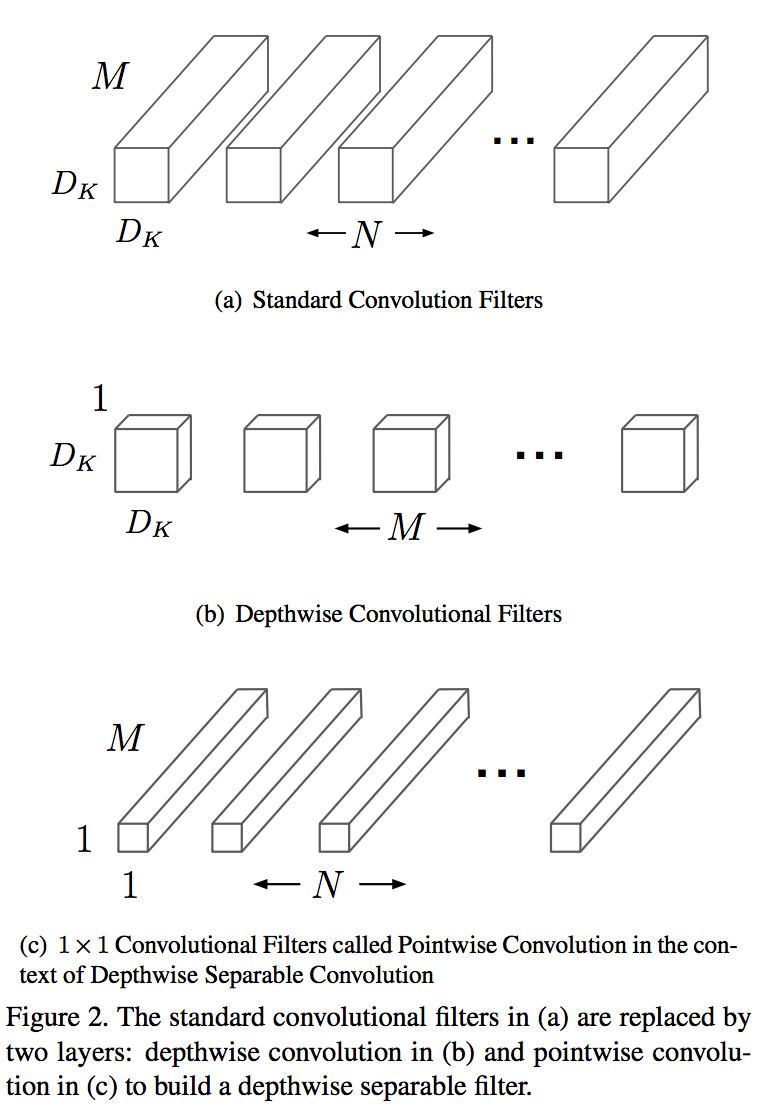
深度可分离卷积 Depthwise Separable Convolution
- 将标准卷积拆分为两个操作:深度卷积(depthwise convolution) 和逐点卷积(pointwise convolution)
- 标准卷积:参数量k*k*input_channel*output_channel
- 深度卷积(depthwise convolution) :针对每个输入通道采用不同的卷积核,参数量k*k*input_channel
- 逐点卷积(pointwise convolution):就是普通的卷积,只不过其采用1x1的卷积核,参数量1*1*input_channel*output_channel
with BN and ReLU:

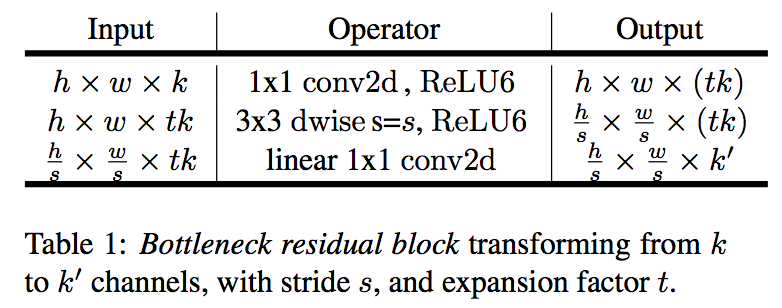
DW没有改变通道数的能力,如果输入层的通道数很少,DW也只能在低维空间提特征,因此V2提出先对原始输入做expansion,用一个非线性PW升维,然后DW,然后再使用一个PW降维,值得注意的是,第二个PW不使用非线性激活函数,因为作者认为,relu作用在低维空间上会导致信息损失。
进一步缩减计算量
- 通道数缩减:宽度因子 alpha
- 分辨率缩减:分辨率因子rho
papers
- [V1 CVPR2017] MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications,Google,主要贡献Depthwise Separable Convolution
- [V2 CVPR2018] MobileNetV2: Inverted Residuals and Linear Bottlenecks,Google,主要贡献inverted residual with linear bottleneck
- [V3 ICCV2019] Searching for MobileNetV3,Google,模型结构升级多了SE(inverted-res-block + SE-block),是通过NAS而非手动设计
- [EfficientNet-lite ICML2019] EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks,efficientNet家族的scale-down版本,原始的EfficientNet是基于Mobile3的basic block,而Lite版本有很多专供移动端的改动:去掉SE、改用RELU6、
- [MobileOne 2022] An Improved One millisecond Mobile Backbone,Apple,
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
- 动机
- efficient models:uses depthwise separable convolutions and two simple global hyper-parameters
- resource and accuracy tradeoffs
- a class of network architectures that allows a model developer to specifically choose a small network that matches the resource restrictions (latency, size) for their application
论点:
- the general trend has been to make deeper and more complicated networks in order to achieve higher accuracy
- not efficient on computationally limited platform
- building small and efficient neural networks:either compressing pretrained networks or training small networks directly
- Many papers on small networks focus only on size but do not consider speed
- speed & size 不完全对等
- size:depthwise separable convolutions, bottleneck approaches, compressing pretrained networks, distillation
方法
depthwise separable convolutions
- a form of factorized convolutions:a standard conv splits into 2 layers
- factorize the filtering and combination steps of standard conv
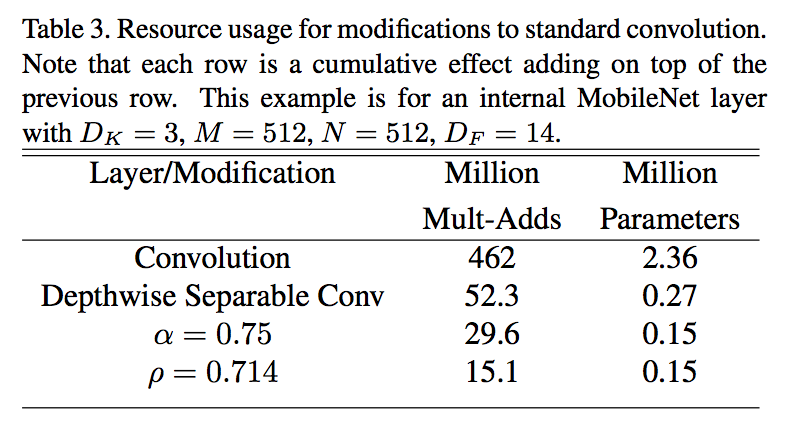
- drastically reducing computation and model size to $\frac{1}{N} + \frac{1}{D_k^2}$
- use both batchnorm and ReLU nonlinearities for both layers
MobileNet uses 3 × 3 depthwise separable convolutions which bring between 8 to 9 times less computation
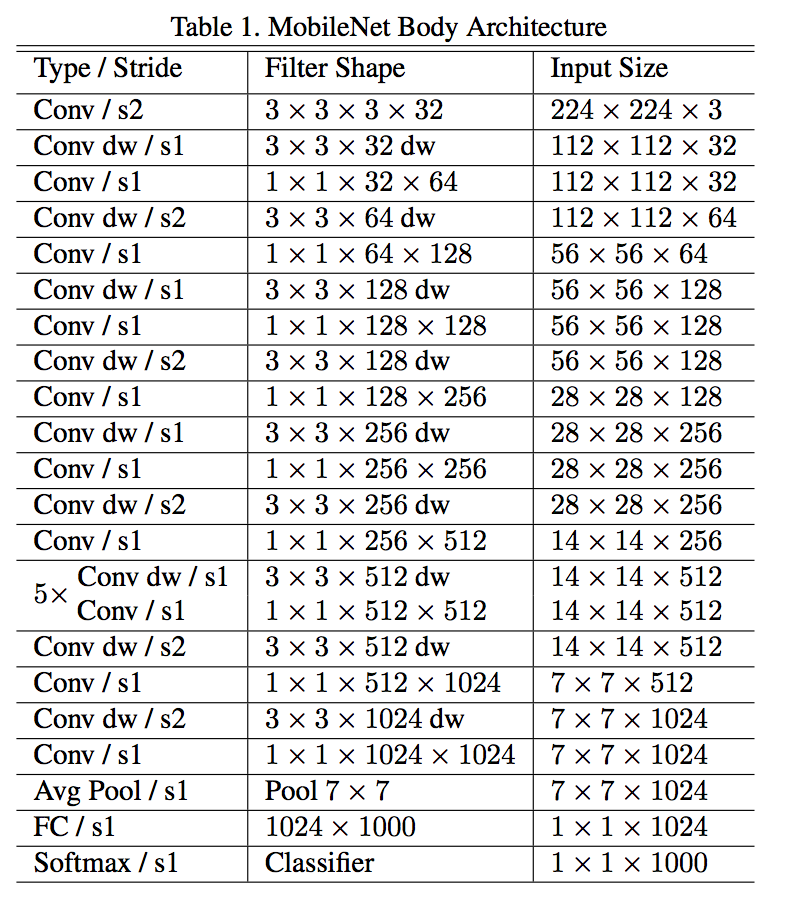
MobileNet
- the first layer is a full convolution, the rest depthwise separable convolutions
- down sampling is handled with strided convolution
- all layers are followed by a BN and ReLU nonlinearity
- a final average pooling reduces the spatial resolution to 1 before the fully connected layer.
the final fully connected layer has no nonlinearity and feeds into a softmax layer for classification
training so few parameters
- RMSprop
- less regularization and data augmentation techniques because small models have less trouble with overfitting
- it was important to put very little or no weight decay (l2 regularization)
- do not use side heads or label smoothing or image distortions
Width Multiplier: Thinner Models
- thin a network uniformly at each layer
- the input channels $M$ and output channels $N$ becomes $\alpha M$ and $\alpha N$
- $\alpha=1$:baseline MobileNet $\alpha<1$:reduced MobileNet
- reduce the parameters roughly by $\alpha^2$
Resolution Multiplier: Reduced Representation
- apply this to the input image
- the input resolution of the network is typically 224, 192, 160 or 128
- $\rho=1$:baseline MobileNet $\rho<1$:reduced MobileNet
reduce the parameters roughly by $\rho^2$
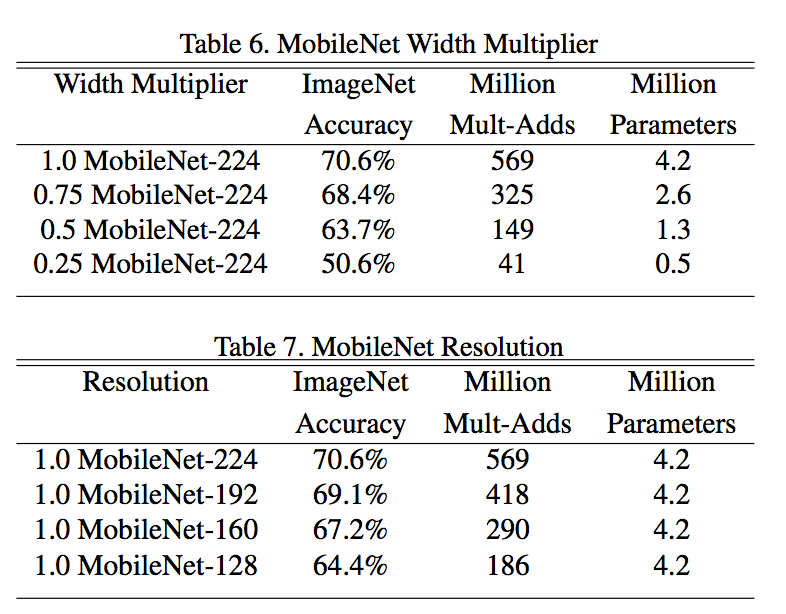
结论
- using depthwise separable convolutions compared to full convolutions only reduces accuracy by 1% on ImageNet but saving tremendously on mult-adds and parameters

- at similar computation and number of parameters, thinner MobileNets is 3% better than making them shallower

- trade-offs based on the two hyper-parameters
MobileNetV2: Inverted Residuals and Linear Bottlenecks
动机
- a new mobile architecture
- based on an inverted residual structure
- remove non-linearities in the narrow layers in order to maintain representational power
- prove on multiple tasks
- object detection:SSDLite
- semantic segmentation:Mobile DeepLabv3
- a new mobile architecture
方法
Depthwise Separable Convolutions
- replace a full convolutional opera- tor with a factorized version
- depthwise convolution, it performs lightweight filtering per input channel
- pointwise convolution, computing linear combinations of the input channels
Linear Bottlenecks
- ReLU results in information loss in lower dimension space
- expansion ratio:if we have lots of channels, information might still be preserved in the other channels
linear:bottleneck上面不包含非线性激活单元
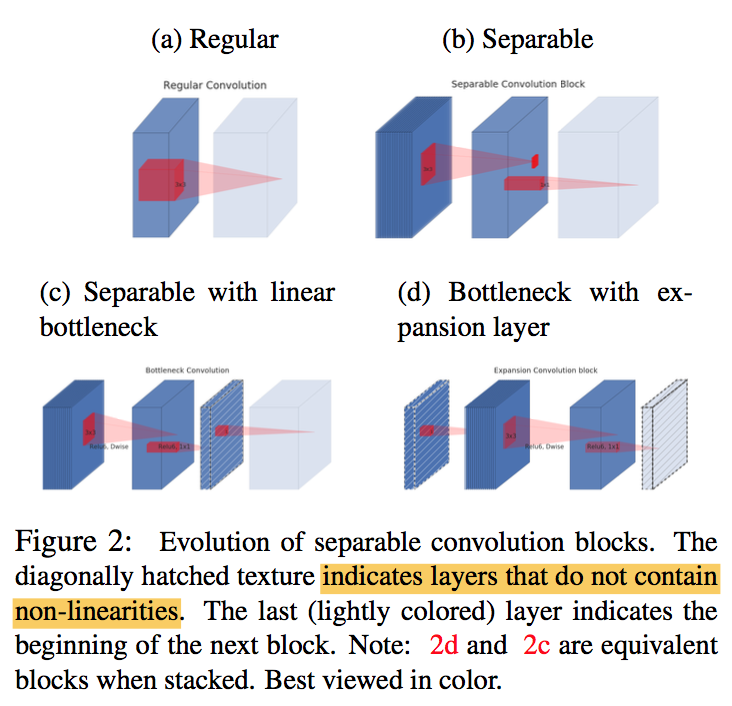
Inverted residuals
- bottlenecks actually contain all the necessary information
- expansion layer acts merely as an implementation detail that accompanies a non-linear transformation
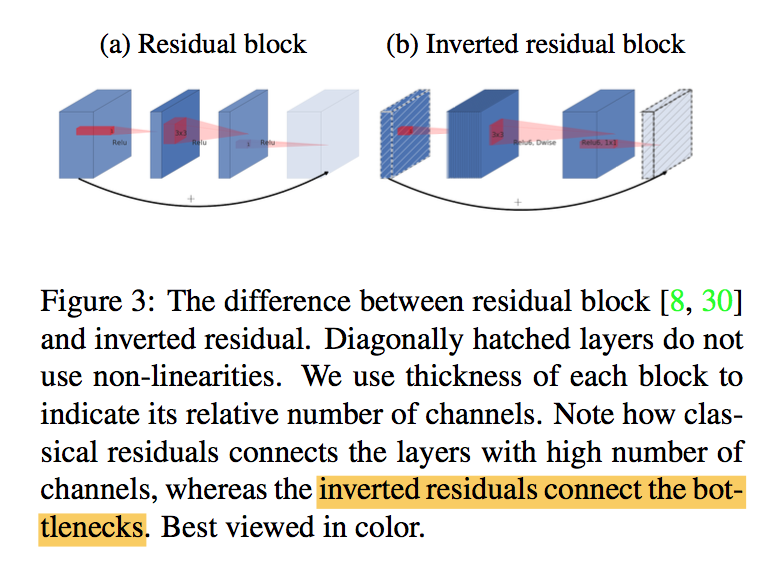
- parameter count:
- basic building block is a bottleneck depth-separable convolution with residuals
* interpretation
* provides a natural separation between the input/output
* expansion:capacity
* layer transformation:expressiveness
* MobileNetV2 model architecture
* initial filters:32
* ReLU6:use ReLU6 as the non-linearity because of its robustness when used with low-precision computation
* use constant expansion rate between 5 and 10 except the 1st:smaller network inclines smaller and larger larger
<img src="MobileNets/MobileNetV2.png" width="40%" />
* comparison with other architectures
<img src="MobileNets/cmpV2.png" width="40%" />
实验
Object Detection
- evaluate the performance as feature extractors
- replace all the regular convolutions with separable convolutions in SSD prediction layers:backbone没有改动,只替换头部的卷积,降低计算量
- achieves competitive accuracy with significantly fewer parameters and smaller computational complexity
Semantic Segmentation
- build DeepLabv3 heads on top of the second last feature map of MobileNetV2
- DeepLabv3 heads are computationally expensive and removing the ASPP module significantly reduces the MAdds
ablation
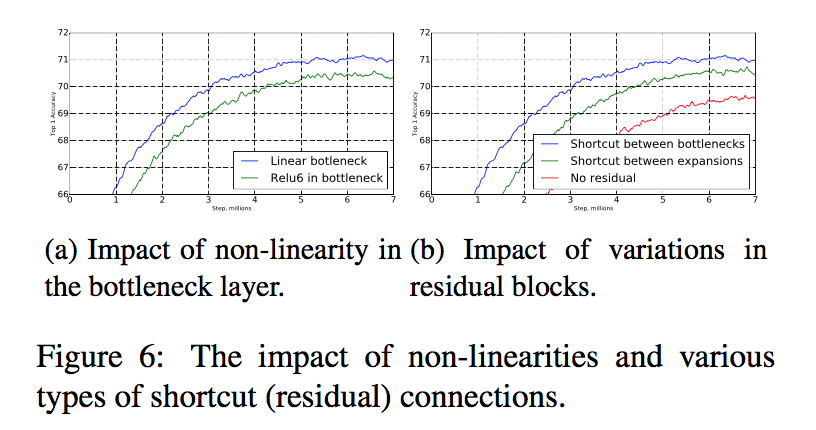
- inverted residual connections:shortcut connecting bottleneck perform better than shortcuts connecting the expanded layers 在少通道的特征上进行短连接
linear bottlenecks:linear bottlenecks improve performance, providing support that non-linearity destroys information in low-dimensional space
Searching for MobileNetV3
动机
- automated search algorithms and network design work together
- classification & detection & segmentation
- a new efficient segmentation decoder Lite Reduced Atrous Spatial Pyramid Pooling (LR-ASPP)
- new efficient versions of nonlinearities
论点
- reducing
- the number of parameters
- the number of operations (MAdds)
- inference latency
- related work
- SqueezeNet:1x1 convolutions
- MobileNetV1:separable convolution
- MobileNetV2:inverted residuals
- ShuffleNet:group convolutions
- CondenseNet:group convolutions
- ShiftNet:shift operation
- MnasNet:MobileNetV2+SE-block,attention modules are placed after the depthwise filters in the expansion
- reducing
方法
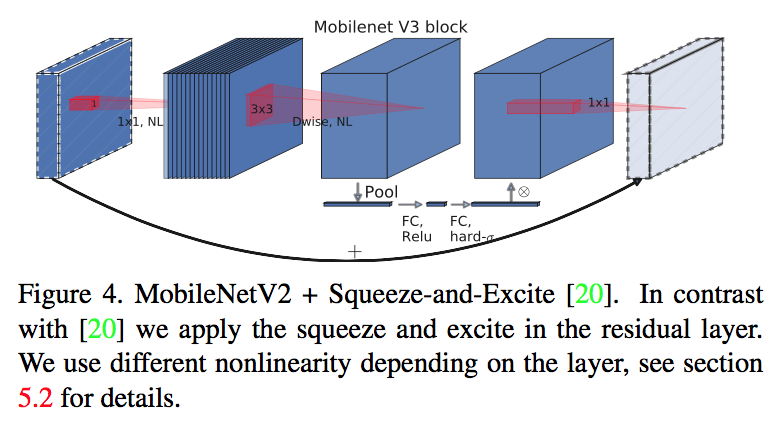
base blocks
- combination of ideas from [MobileNetV1, MobileNetV2, MnasNet]
- inverted-res-block + SE-block
- swish nonlinearity
- hard sigmoid
Network Search
- use platform-aware NAS to search for the global network structures
- use the NetAdapt algorithm to search per layer for the number of filters
Network Improvements
redesign the computionally-expensive layers at the beginning and the end of the network
- the last block of MobileNetV2’s inverted bottleneck structure
- move this layer past the final average pooling:移动到GAP后面去,作用在1x1的featuremap上instead of 7x7,曲线救国
a new nonlinearity, h-swish
the initial set of filters are also expensive:usually start with 32 filters in a full 3x3 convolution to build initial filter banks for edge detection
reduce the number of filters to 16 and use the hard swish nonlinearity
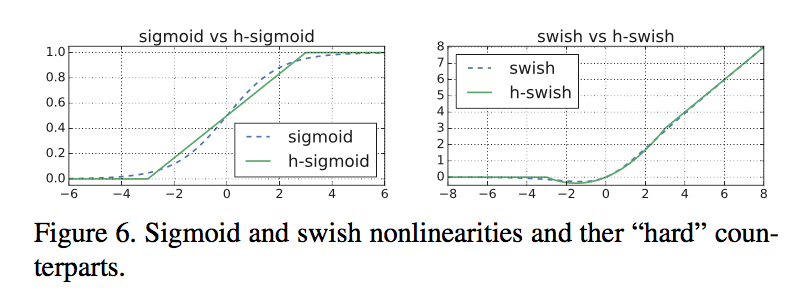
most of the benefits swish are realized by using them only in the deeper layers:只在后半段网络中用
SE-block
- ratio:all to fixed to be 1/4 of the number of channels in expansion layer
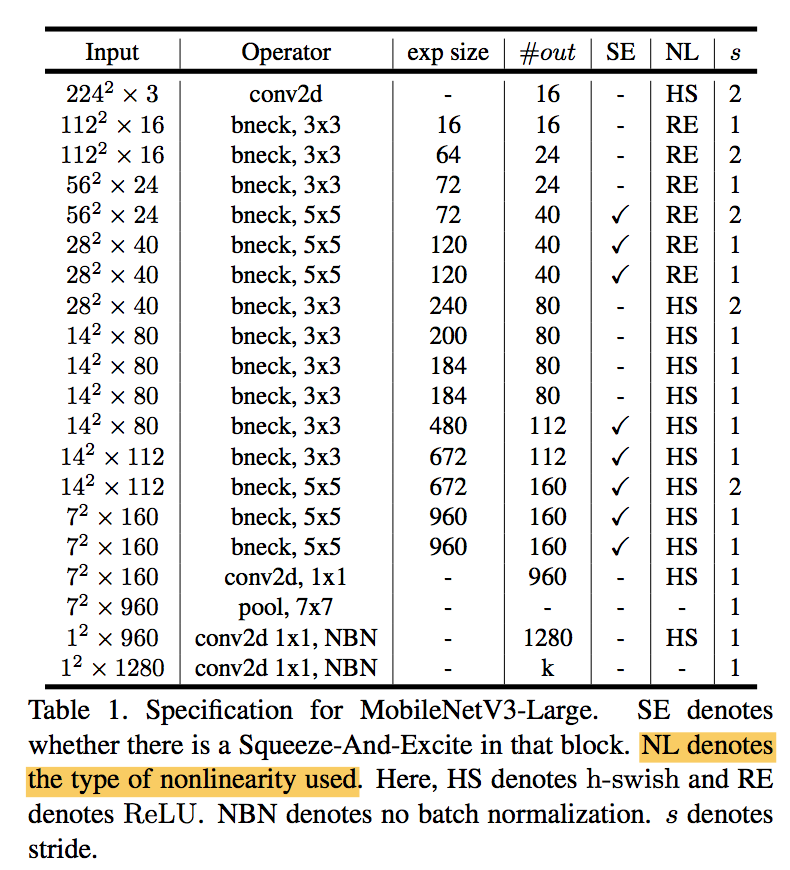
MobileNetV3 architecture
实验
Detection
- use MobileNetV3 as replacement for the backbone feature extractor in SSDLite:改做backbone了
- reduce the channel counts of C4&C5’s block:因为MobileNetV3原本是被用来输出1000类的,transfer到90类的coco数据集上有些redundant
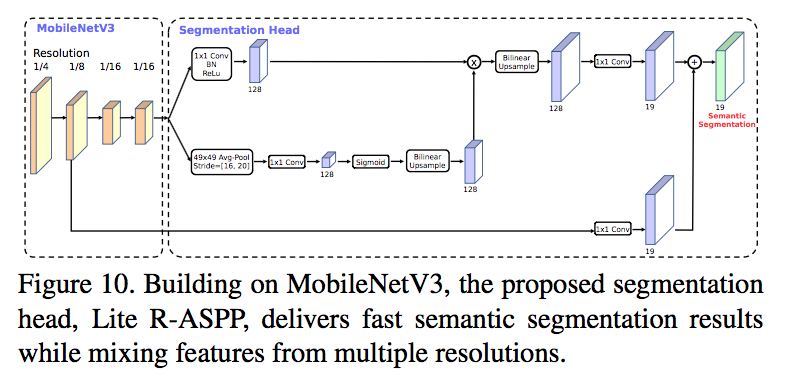
Segmentation
as network backbone
compare two segmentation heads
- R-ASPP:reduced design of the Atrous Spatial Pyramid Pooling module with only two branches
Lite R-ASPP:类SE-block的设计,大卷积核,大步长
EfficientNet-lite
没有专门的paper
model zoo
| model | width | depth | resolution | droprate |
| ————————— | ——- | ——- | ————— | ———— |
| efficientnet-lite0 | 1. | 1. | 224 | .2 |
| efficientnet-lite1 | 1. | 1.1 | 240 | .2 |
| efficientnet-lite2 | 1.1 | 1.2 | 260 | .3 |
| efficientnet-lite3 | 1.2 | 1.4 | 280 | .3 |
| efficientnet-lite4 | 1.4 | 1.8 | 300 | .3 |
| | | | | |关键数据:
- lite4精度可以达到80.4%,同时保持在Pixel 4 CPU上real-time运行:30ms/image
- latency:10-30ms
- model size:5M-15M
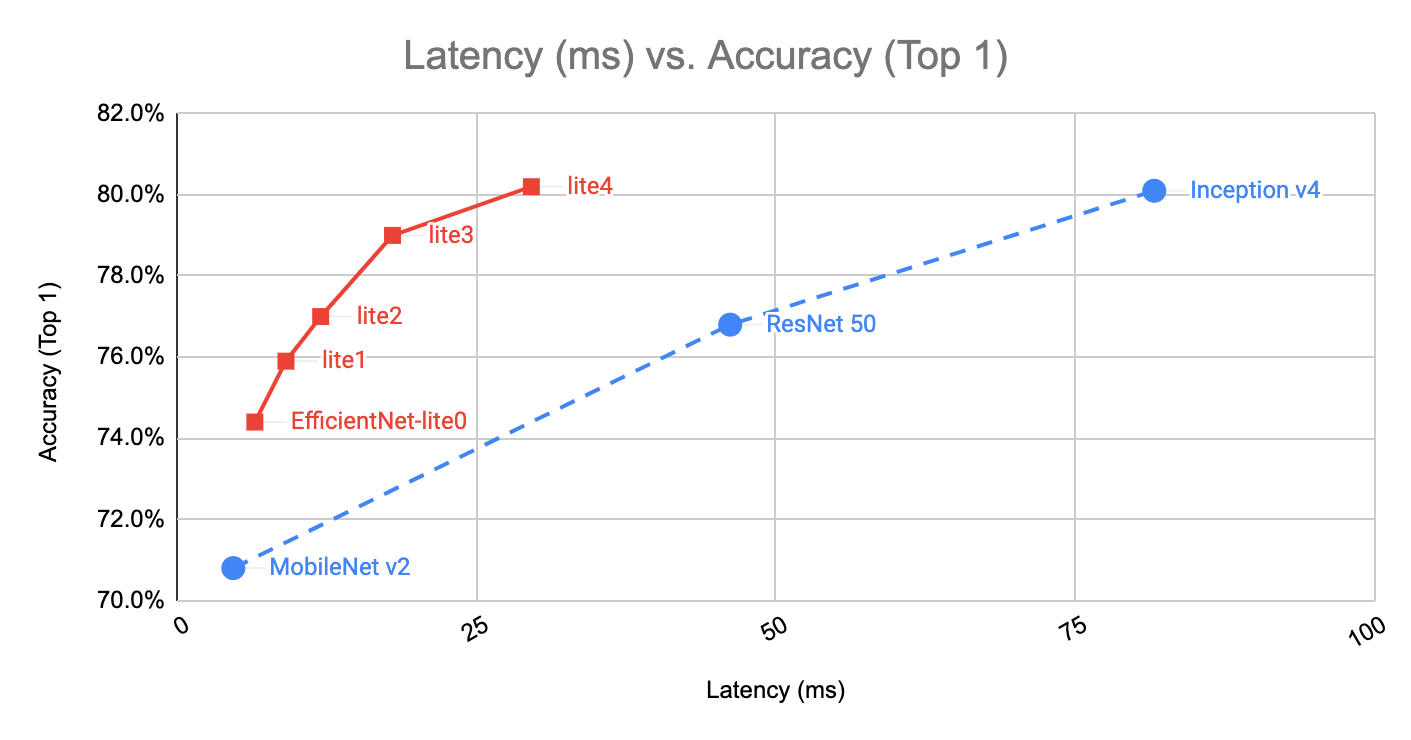
<img src="MobileNets/lite-size.png" width="40%;" />
3. challenges
* Quantization量化:移动端设备支持的浮点精度有限——训练后量化,将浮点模型tf model转化成tfLite model(全整数int8/半浮点float16),
* Heterogeneous hardware移动端设备参差不齐:好多操作不支持,尽量替换成底层支持的op
4. modifications
* Removed squeeze-and-excitation networks:去掉SE,not well supported
* swish替换成RELU6:有利于post-training quantization
* 一开始将浮点替换成整型的时候观察到huge acc drop:75 -> 48
* 发现是因为浮点太wide-ranged了,直接映射到int8太多精度损失
* 所以替换成激活区间有限的relu6 [0,6]
<img src="MobileNets/int8.png" width="40%;" /><img src="MobileNets/quantization.png" width="40%;" />
* Fixed the stem and head while scaling models up:stem的resolution大,head的channel大,scaleup都对参数量/计算量影响比较大,只scaleup中间的stage
MobileOne: An Improved One millisecond Mobile Backbone
动机
- FLOPs & 参数量等指标并不直接和移动端latency相关
this paper
- 调研了各种mobileNets的优化瓶颈:architectural and optimization bottlenecks
- 提出了MobileOne
精度
- 低于1ms/image的速度,top 1 acc 75.9%
- 上面的eff-lite0要10ms,top 1 acc 74.+%,涨点2.3%
Mobile- Former精度近似,速度要快38x
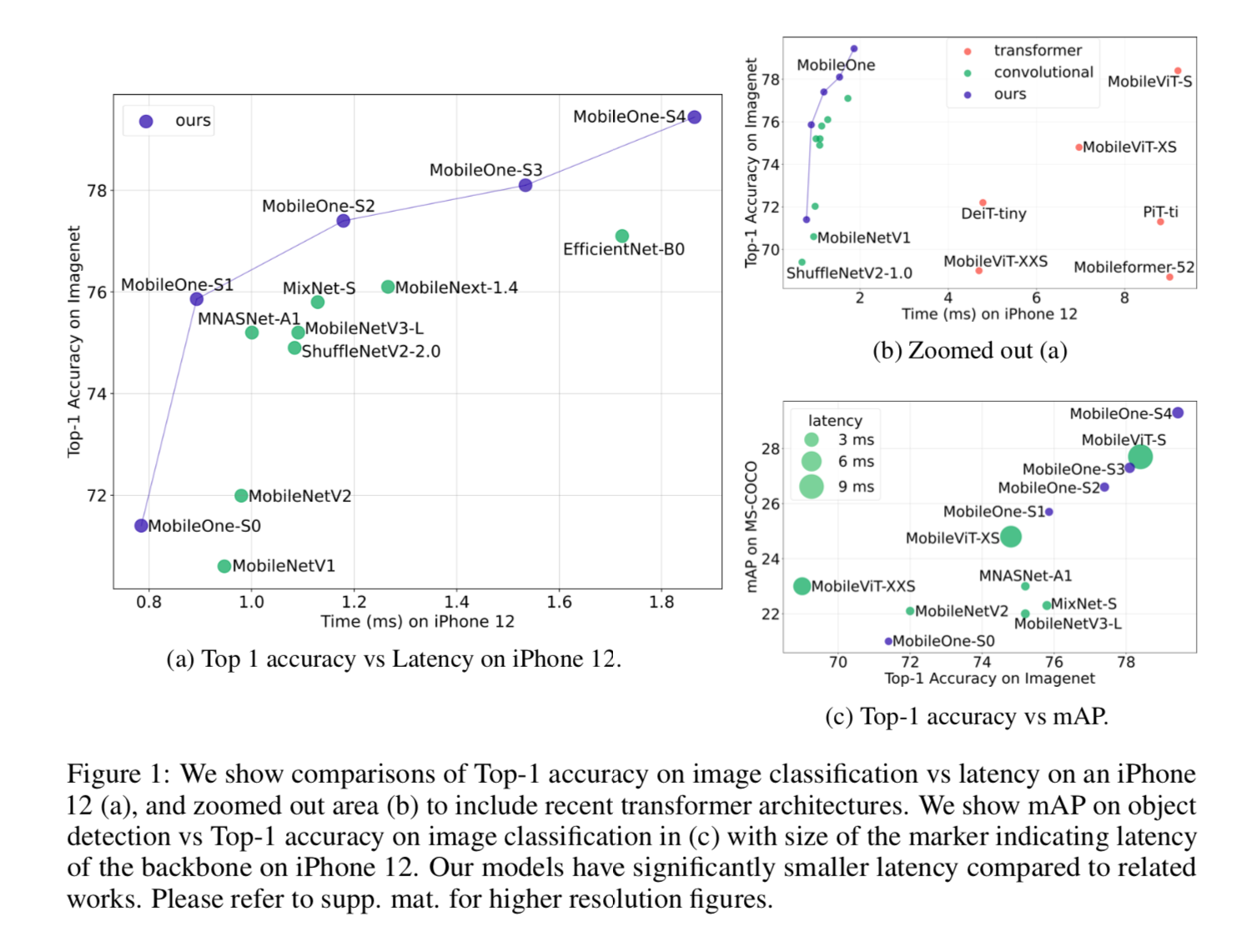
论点
- previous methods
- 大部分foucs on 优化FLOPs
- 而且会引入new architecture designs & custom layers,如hard-swish,这在移动端通常不原生支持
- existing metric & latency
- FLOPs does not account for memory cost and degree of parallelism
- sharing parameters leads to higher FLOPS but smaller model size
- skip-connections / branching incur memory costs
- 结构优化
- 要找到真正限制on-device latency的要素
- 训练优化
- 直接训练小模型精度肯定差,通常是decoupling train-time & test-time architecture
- 进一步地还做了relaxing regularization
- the proposed MobileOne
- use basic operators
- introduces linear branches which get re-parameterized at inference-time:与之前方法的区别是引入了over-parameterization branches【repVGG是把常规的resblock搞成一个线形op了,本文的branch有k个,是把好多个branch合并一起,所以起名叫over?】
- inference time model has only feed-forward structure
- generalizes well to other tasks:在分类、检测、分割上都outperforming
- previous methods
方法
Metric Correlations
parameter count and FLOPs
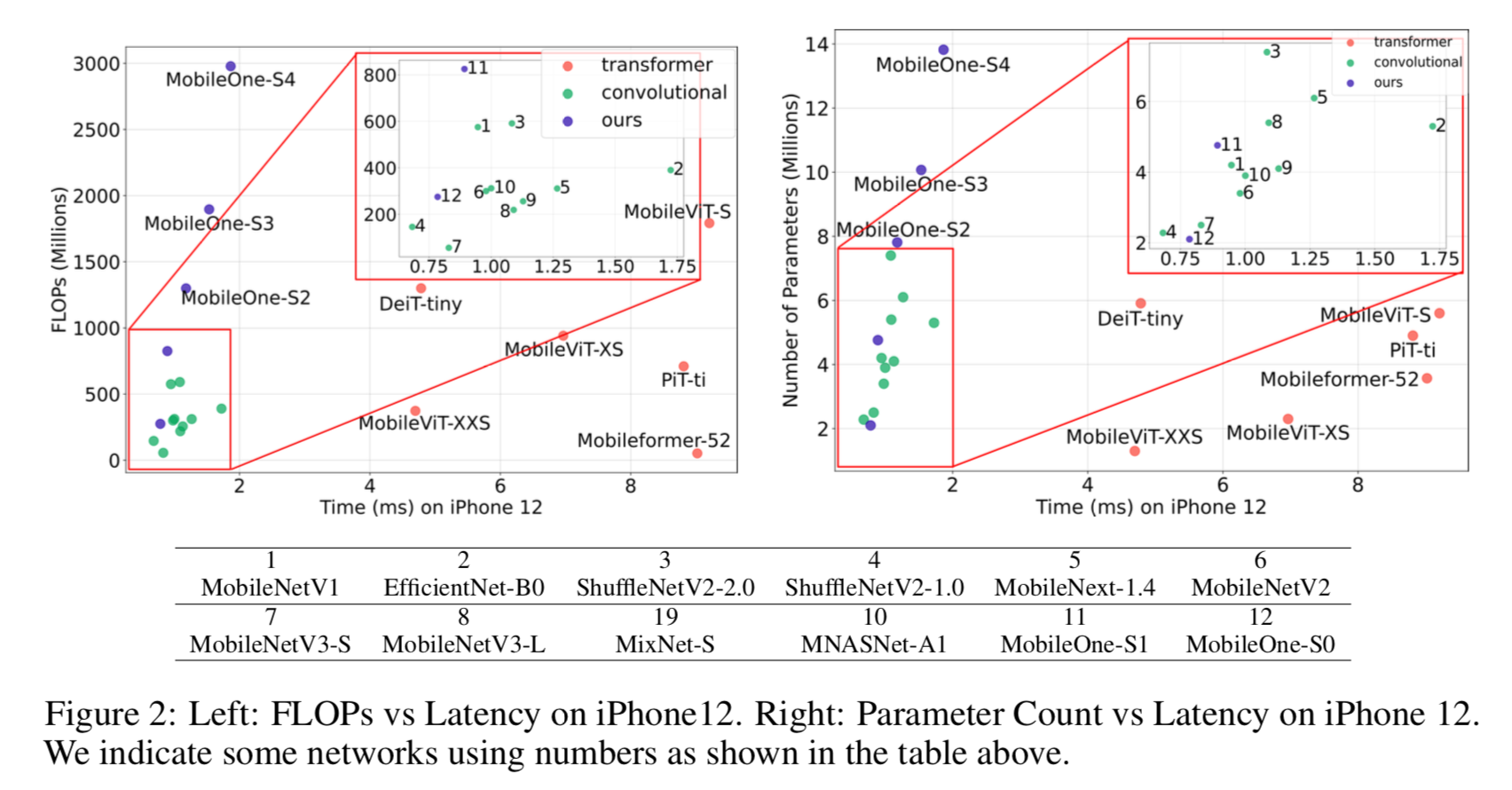
很多模型参数量很大,但是latency更小——只要右边的点纵坐标比左边的低都是这种case,如3(efficientnet-b0)&2(shufflenet-v2)
FLOPs和参数量近似的情况下,卷积模型通常比他们的transformer counterpart latency更小——可以看到transformer模型都在右下角
CPU correlation
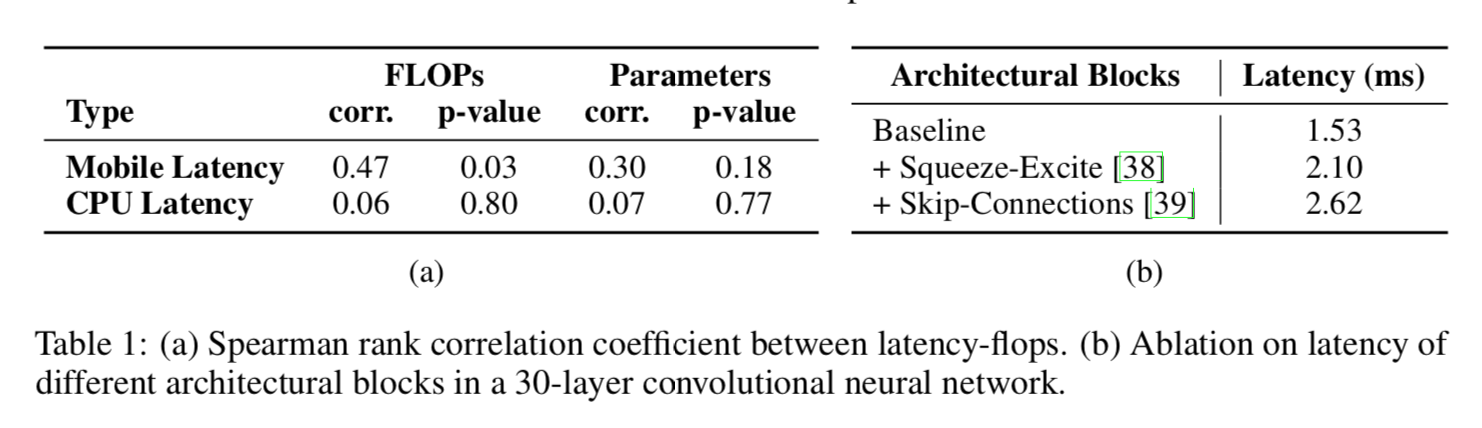
- mobile device与FLOPs适度相关,与参数量基本无关
- CPU的latency更无关
- 结构的影响更大,SE-block和skip都影响挺大的
Key Bottlenecks
Activation Functions
搞了同样的网络架构,用不同的激活函数
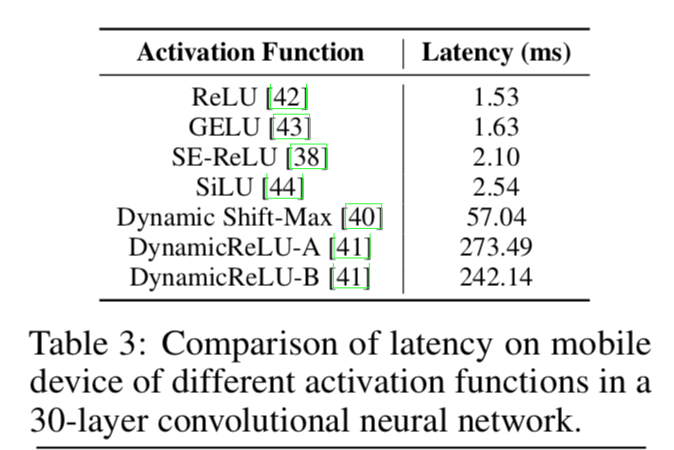
激活函数越花,latency越大,归因于synchronization cost,个别激活函数有通过特殊硬件加速的实现
- 从通用角度,本文选用ReLU
Architectural Blocks
- 根本因素是memory access cost & degree of parallelism
- 分支越多,memory access cost越大,因为存在多节点交互更多
- 而像global pooling这种force synchronization需要同步计算的,也影响overall run-time
- 上面截图有这个
MobileOne Architecture
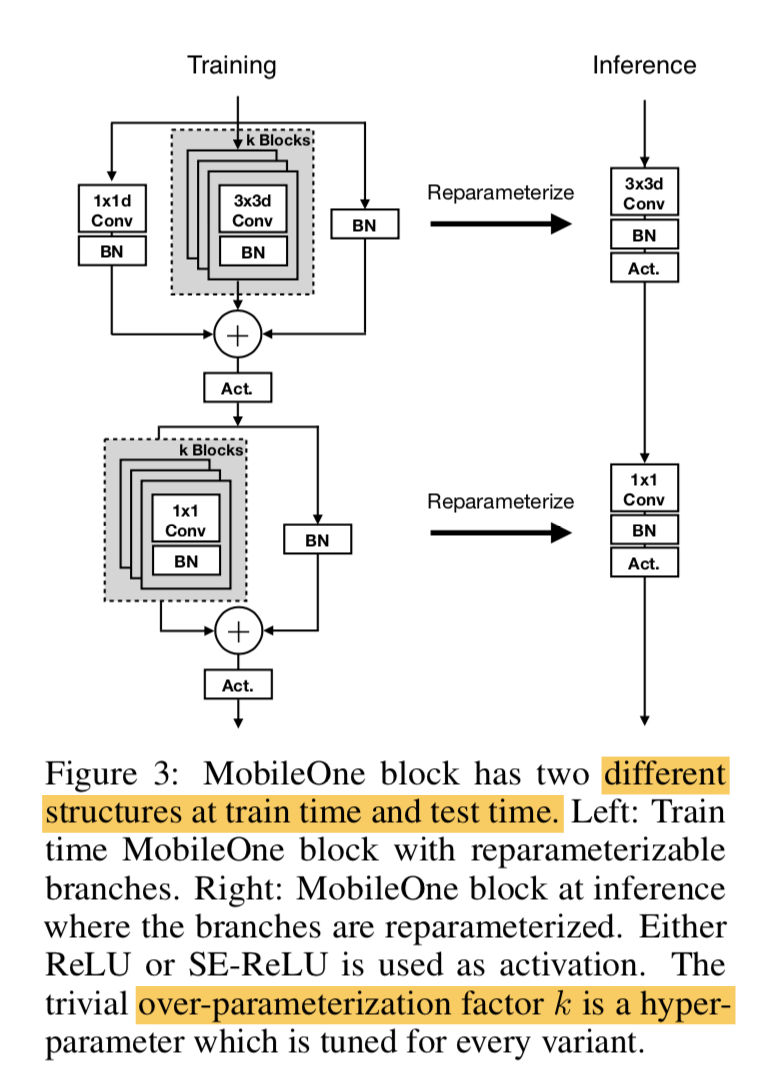
MobileOne Block
- training & test time 不一样
- training time
- basic block还是类似mobileV1的depth-wise + point-wise
- 每个3x3 donv 和 1x1 pconv都变成了一个多分枝的block
- block有k个 re-parameterizable branch,k是个超参,1-5
- 除此之外还有两个常规的branch:1x1 dconv & BN
inference time
- 只有一条data steam
- 合并思路类似repvgg:所有的线形计算都可以合并
Model Scaling
提供了5个尺寸的模型,主要变化在channel,深度是没变的

Training
- 小模型训练,need less regularization,但是weight decay对训练初期又很重要
- cosine schedule for both LR & weight decay
- 还用了efficientNetV2里面提到的progressive learning:从简单任务开始训练,逐渐增加难度(resolution & dataaug) & 超参(regularization)
还有EMA:model ensemble
