0. 综述
attention的方式分为两种(Reference)
- 学习权重分布
- 部分加权(hard attention)/全部加权(soft attention)
- 原图上加权/特征图上加权
- 空间尺度加权/channel尺度加权/时间域加权/混合域加权
- CAM系列、SE-block系列:花式加权,学习权重,non-local的模块,作用于某个维度
- 任务分解
- 设计不同的网络结构(或分支)专注于不同的子任务,
- 重新分配网络的学习能力,从而降低原始任务的难度,使网络更加容易训练
- STN、deformable conv:添加显式的模块负责学习形变/receptive field的变化,local模块,apply by pixel
- local / non-local
- local模块的结果是pixel-specific的
- non-local模块的结果是全局共同计算的的
- 学习权重分布
基于权重的attention(Reference)
- 注意力机制通常由一个连接在原神经网络之后的额外的神经网络实现
- 整个模型仍然是端对端的,因此注意力模块能够和原模型一起同步训练
- 对于soft attention,注意力模块对其输入是可微的,所以整个模型仍可用梯度方法来优化
- 而hard attention要离散地选择其输入的一部分,这样整个系统对于输入不再是可微的
papers
[deformable conv] Deformable Convolutional Networks
[CBAM] CBAM: Convolutional Block Attention Module
[SE-Net] Squeeze-and-Excitation Networks
[SE-block的一系列变体] SC-SE(for segmentation)、CMPE-SE(复杂又没用)
[SK-Net] Selective Kernel Networks:是attension module,但是主要改进点在receptive field,trick大杂烩
[GC-Net] GCNet: Non-local Networks Meet Squeeze-Excitation Networks and Beyond
CBAM: Convolutional Block Attention Module
- 动机
- attention module
- lightweight and general
- improvements in classification and detection
论点
- deeper: can obtain richer representation
- increased width:can outperform an extremely deep network
- cardinality:results in stronger representation power than depth and width
- attention:improves the representation of interests
- humans exploit a sequence of partial glimpses and selectively focus on salient parts
- Residual Attention Network:computes 3d attention map
- we decompose the process that learns channel attention and spatial attention separately
- SE-block:use global average-pooled features
- we suggest to use max-pooled features as well
方法
- sequentially infers a 1D channel attention map and a 2D spatial attention map
broadcast and element-wise multiplication
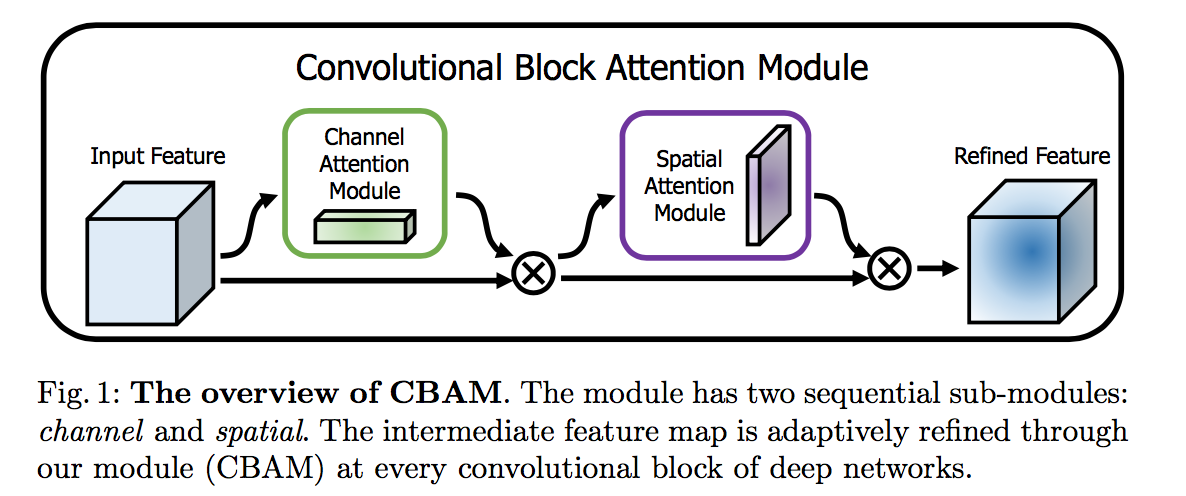
Channel attention module
- focuses on ‘what’ is meaningful
- squeeze the spatial dimension
- use both average-pooled and max-pooled features simultaneously
- both descriptors are then forwarded to a shared MLP to reduce dimension
- 【QUESTION】看论文MLP是线性的吗,没写激活函数
- then use element-wise summation
- sigmoid function
- Spatial attention module
- focuses on ‘where’
- apply average-pooling and max-pooling along the channel axis and concatenate
- 7x7 conv
- sigmoid function
Arrangement of attention modules
- in a parallel or sequential manner
- we found sequential better than parallel
- we found channel-first order slightly better than the spatial-first
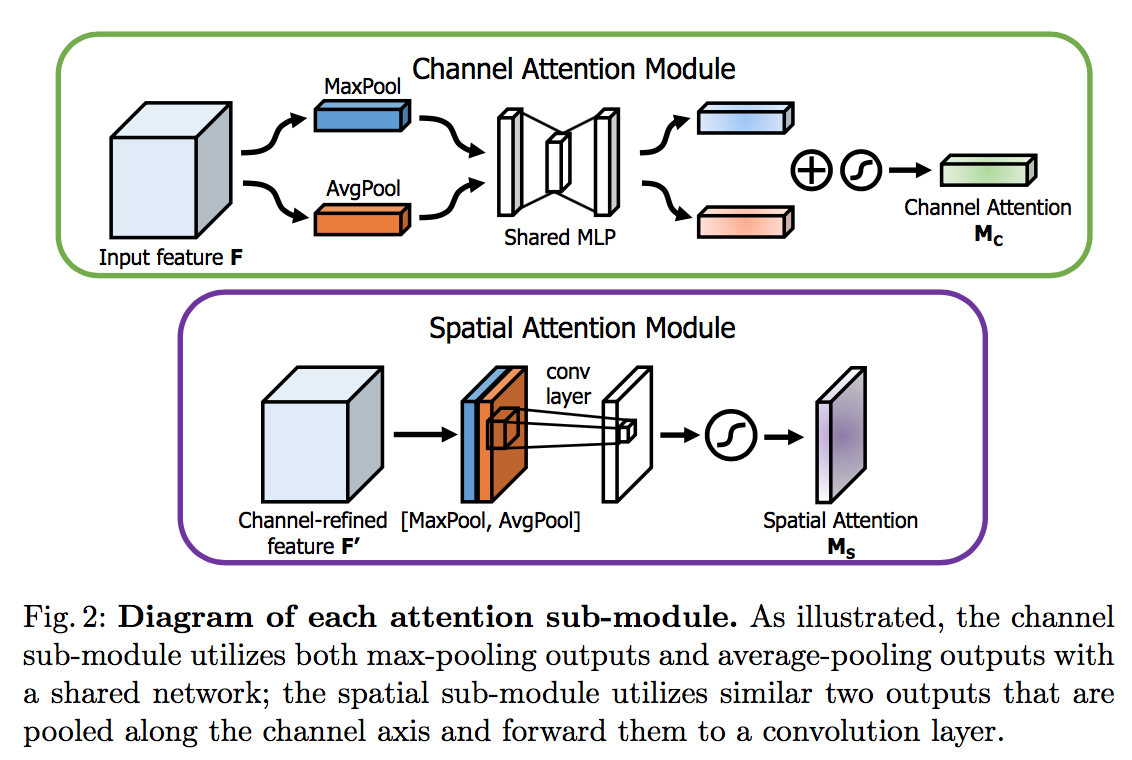
integration
- apply CBAM on the convolution outputs in each block
- in residual path
before the add operation
实验
Ablation studies
- Channel attention:两个pooling path都有效,一起用最好
- Spatial attention:1x1conv直接squeeze也行,avg+max更好,7x7conv略好于3x3conv
- arrangement:前面说了,比SE的单spacial squeeze好,channel在前好于在后,串行好于并行
Classification results:outperform baselines and SE
- Network Visualization
- cover the target object regions better
- the target class scores also increase accordingly
- Object Detection results
- apply to detectors:right before every classifier
- apply to backbone
SK-Net: Selective Kernel Networks
动机
- 生物的神经元的感受野是随着刺激变化而变化的
- propose a selective kernel unit
- adaptively adjust the RF
- multiple branches with different kernel sizes
- guided fusion
- 大杂烩:multi-branch&kernel,group conv,dilated conv,attention mechanism
- SKNet
- by stacking multiple SK units
- 在分类任务上验证
论点
- multi-scale aggregation
- inception block就有了
- but linear aggregation approach may be insufficient
- multi-branch network
- two-branch:以resnet为代表,主要是为了easier to train
- multi-branch:以inception为代表,主要为了得到multifarious features
- grouped/depthwise/dilated conv
- grouped conv:reduce computation,提升精度
- depthwise conv:reduce computation,牺牲精度
- dilated conv:enlarge RF,比dense large kernel节省参数量
- attention mechanism
- 加权系列:
- SENet&CBAM:
- 相比之下SKNet多了adaptive RF
- 动态卷积系列:
- STN不好训练,训好以后变换就定死了
- deformable conv能够在inference的时候也动态的变化变换,但是没有multi-scale和nonlinear aggregation
- 加权系列:
- thus we propose SK convolution
- multi-kernels:大size的conv kernel是用了dilated conv
- nonlinear aggregation
- computationally lightweight
- could successfully embedded into small models
- workflow
- split
- fuse
- select
- main difference from inception
- less customized
- adaptive selection instead of equally addition
- multi-scale aggregation
方法
selective kernel convolution
split
- multi-branch with different kernel size
- grouped/depthwise conv + BN + ReLU
- 5x5 kernel can be further replaced with dilated conv
fuse
- to learn the control of information flow from different branches
- element-wise summation
- global average pooling
- fc-BN-ReLU:reduce dimension,at least 32
select
channel-wise weighting factor A & B & more:A+B + more = 1
fc-softmax
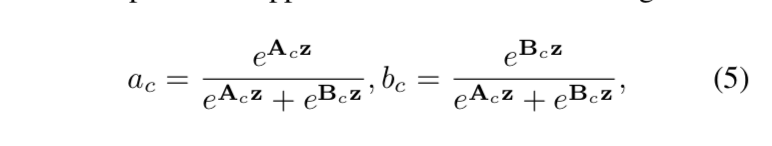
在2分支的情况下,一个权重矩阵A就够了,B是冗余的,因为可以间接算出来
reweighting

network
- start from resnext
- repeated SK units:类似bottleneck
- 1x1 conv
- SK conv
- 1x1 conv
- hyperparams
- number of branches M=2
- group number G=32:cardinality of each path
- reduction ratio r=16:fuse operator中dim-reduction的参数
嵌入到轻量的网络结构
- MobileNet/shuffleNet
- 把其中的3x3 depthwise卷积替换成SK conv

实验
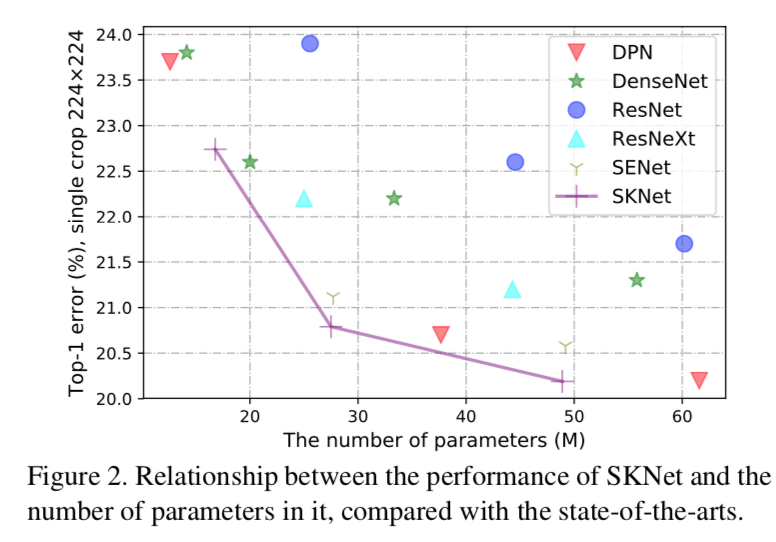
比sort的resnet、densenet、resnext精度都要好
GCNet: Non-local Networks Meet Squeeze-Excitation Networks and Beyond
动机
- Non-Local Network (NLNet)
- capture long-range dependencies
- obtain query-specific global context
- but we found global contexts are almost the same for different query positions
- we produce
- query-independent formulation
- smiliar structure as SE-Net
- aims at global context modeling
- Non-Local Network (NLNet)
论点
Capturing long-range dependency
mainly by sdeeply stacking conv layers:inefficient
non-local network
- via self-attention mechanism
- computes the pairwise relations between the query position then aggregate
但是不同位置query得到的attention map基本一致

we simply the non-local block
- query-independent
- maintain acc & save computation
our proposed GC-block
- unifies both the NL block and the SE block
- three steps
- global context modeling:
- feature transform module:capture channel-wise interdependency
- fusion module:merge into the original features
多种任务上均有涨点
- 但都是在跟resnet50对比
revisit NLNet
non-local block
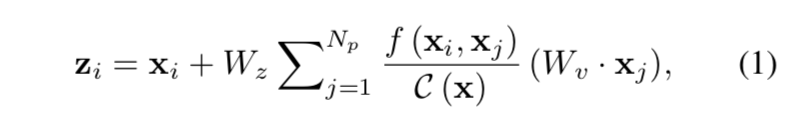
$f(x_i, x_j)$:
- encodes the relationship between position i & j
- 计算方式有Gaussian、Embedded Gaussian、Dot product、Concat
- different instantiations achieve comparable performance
$C(x)$:norm factor
$x_i + \sum^{N_p} F(x_j)$:aggregates a specific global feature on $x_i$
widely-used Embedded Gaussian:
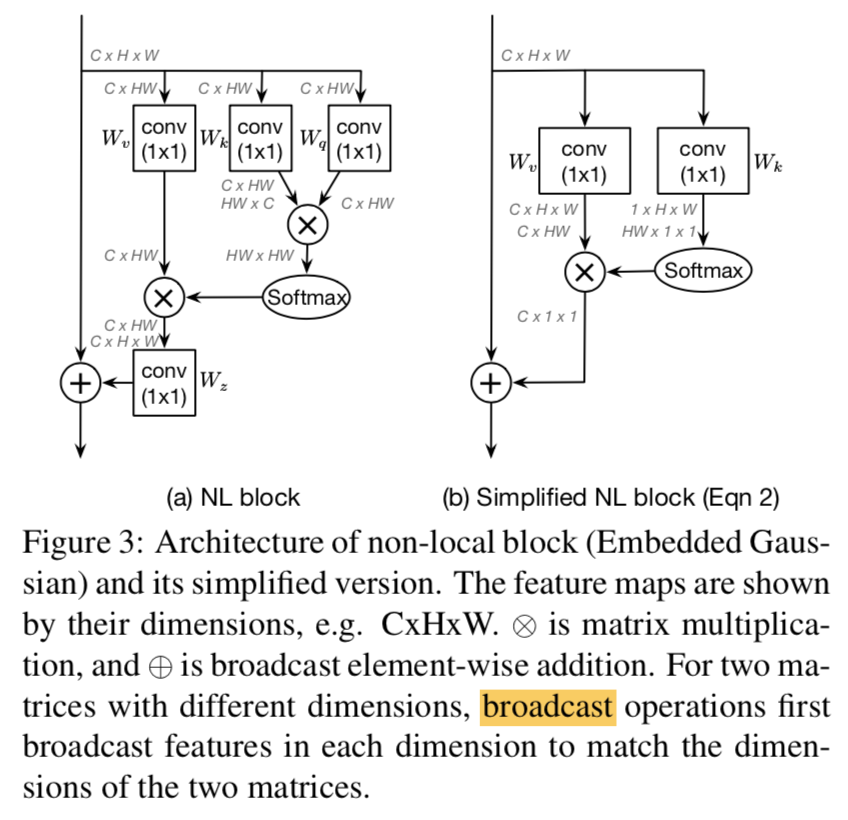
嵌入方式:
- Mask R-CNN with FPN and Res50
- only add one non-local block right before the last residual block of res4
observations & inspirations
- distances among inputs show that input features are discriminated
- outputs & attention maps are almost the same:global context after training is actually independent of query position
- inspirations
- simplify the Non-local block
- no need of query-specific
方法
simplifying form of NL block:SNL
求一个common的global feature,share给全图每个position
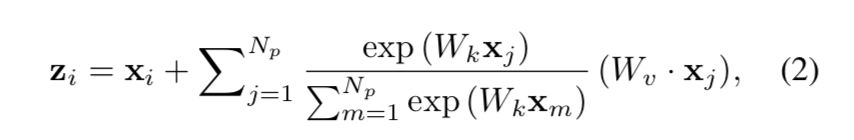
进一步简化:把$x_j$的1x1 conv提到前面,FLOPs大大减少,因为feature scale从HW变成了1x1
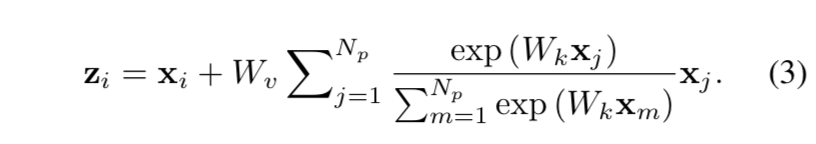
the SNL block achieves comparable performance to the NL block with significantly lower FLOPs
global context modeling
- SNL可以抽象成三部分:
- global attention pooling:通过$W_k$ & softmax获取attention weights,然后进行global pooling
- feature transform:1x1 conv
- feature aggregation:broadcast element-wise add
SE-block也可以分解成类似的抽象
- global attention pooling:用了简单的global average pooling
- feature transform:用了squeeze & excite的fc-relu-fc-sigmoid
- feature aggregation:broadcast element-wise multiplication
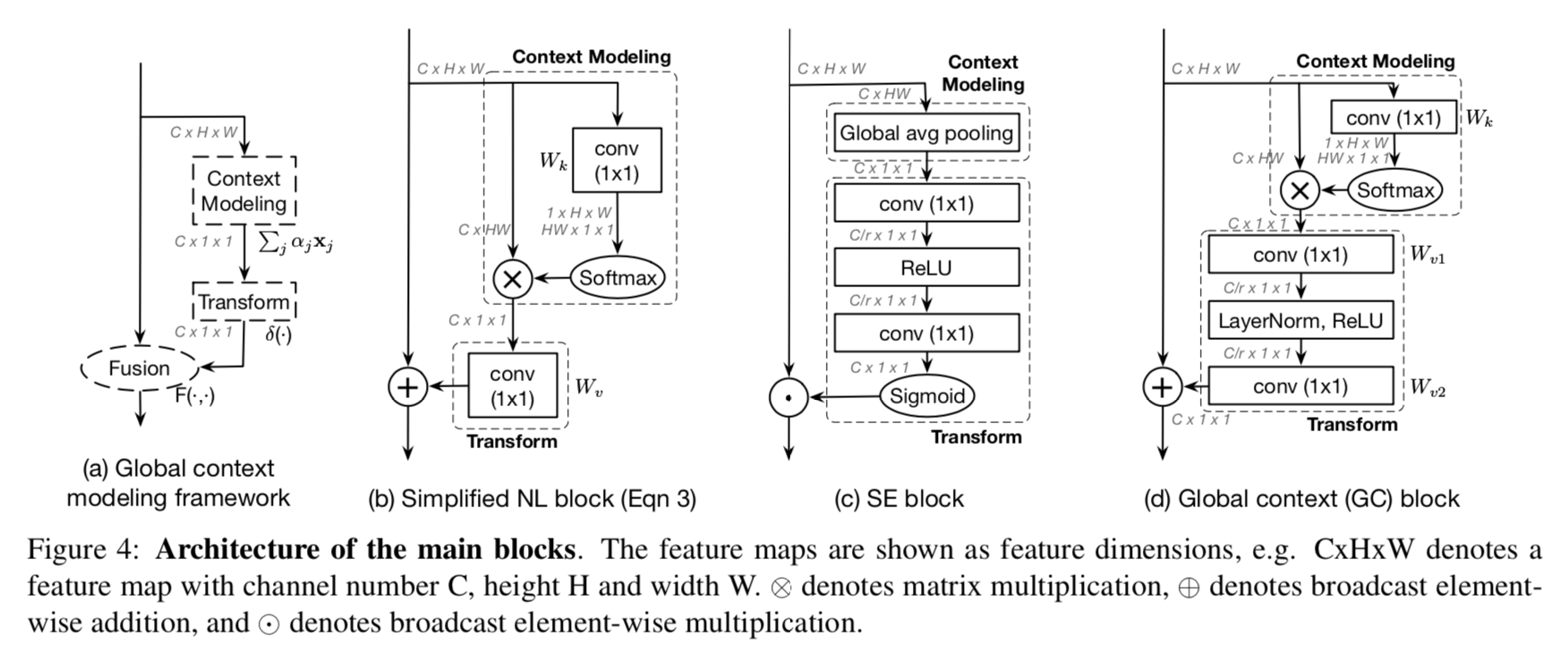
- SNL可以抽象成三部分:
Global Context Block
- integrate the benefits of both
- SNL global attention pooling:effective modeling on long-range dependency
- SE bottleneck transform:light computation(只要ratio大于2就会节省参数量和计算量)
- 特别地,在SE transform的squeeze layer上,又加了BN
- ease optimization
- benefit generalization
- fusion:add
- 嵌入方式:
- GC-ResNet50
- add GC-block to all layers (c3+c4+c5) in resnet50 with se ratio of 16
- integrate the benefits of both
relationship to SE-block
- 首先是fusion method reflects different goals
- SE基于全局信息rescales the channels,间接使用
- GC直接使用,将long-range dependency加在每个position上
- 其次是norm layer
- ease optimization
- 最后是global attention pooling
- SE的GAP是a special case
- weighting factors shows superior
- 首先是fusion method reflects different goals