综述
papers
- deeplabV1: SEMANTIC IMAGE SEGMENTATION WITH DEEP CONVOLUTIONAL NETS AND FULLY CONNECTED CRFS,主要贡献提出了空洞卷积,使得feature extraction阶段输出的特征图维持较高的resolution
- deeplabV2: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs,主要贡献是多尺度ASPP结构
- deeplabV3: Rethinking Atrous Convolution for Semantic Image Segmentation,提出了基于ResNet的串行&并行两种结构,细节上提到了multi-grid,改进了ASPP模块
- deeplabV3+: Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
- Auto-DeepLab: Hierarchical Neural Architecture Search for Semantic Image Segmentation
分割结果比较粗糙的原因
- 池化:将全图抽象化,降低分辨率,会丢失细节信息,平移不变性,使得边界信息不清晰
- 没有利用标签之间的概率关系:CNN缺少对空间、边缘信息等约束
对此,deeplabV1引入了
- 空洞卷积:VGG中提出的多个小卷积核代替大卷积核的方法,只能使感受野线性增长,而多个空洞卷积串联,可以实现指数增长。
- 全连接条件随机场CRF:作为stage2,提高模型捕获细节的能力,提升边界分割精度
大小物体同时分割
deeplabV2引入
- 多尺度ASPP(Atrous Spatial Pyramid Pooling):并行的采用多个采样率的空洞卷积提取特征,再进行特征融合
- backbone model change:VGG16改为ResNet
- 使用不同的学习率
进一步改进模型架构
deeplabV3引入
- ASPP嵌入ResNet后几个block
- 去掉了CRF
使用原始的Conv/pool操作,得到的low resolution score map,pool stride会使得过程中丢弃一部分信息,上采样会得到较大的失真图像,使用空洞卷积,保留特征图上的全部信息,同时keep resolution,减少了信息损失
DeeplabV3的ASPP相比较于V2,增加了一条1x1 conv path和一条image pooling path,加GAP这条path是因为,实验中发现,随着rate的增大,有效的weight数目开始减少(部分超出边界无法有效捕捉远距离信息),因此利用global average pooling提取了image-level的特征并与ASPP的特征并在一起,来补充因为dilation丢失的信息
空洞卷积的path,V2是每条path分别空洞卷积然后接两个1x1conv(没有BN),V3是空洞卷积和BatchNormalization组合
fusion方式,V2是sum fusion,V3是所有path concat然后1x1 conv,得到最终score map
DeeplabV3的串行版本,“In order to maintain original image size, convolutions are replaced with strous convolutions with rates that differ from each other with factor 2”,ppt上说后面几个block复制了block4,每个block里面三层conv,其中最后一层conv stride2,然后为了maintain output size,空洞rate*2,这个不太理解。
multi-grid method:对每个block里面的三层卷积采用不同空洞率,unit rate(e.g.(1,2,4)) * rate (e.g. 2)
deeplabV1: SEMANTIC IMAGE SEGMENTATION WITH DEEP CONVOLUTIONAL NETS AND FULLY CONNECTED CRFS
动机
- brings together methods from Deep Convolutional Neural Networks and probabilistic graphical models
- poor localization property of deep networks
- combine a fully connected Conditional Random Field (CRF)
- be able to localize segment boundaries beyond previous accuracies
- speed: atrous
- accuracy:
- simplicity: cascade modules
论点
- DCNN learns hierarchical abstractions of data, which is desirable for high-level vision tasks (classification)
- but it hampers low-level tasks, such as pose estimation and semantic segmentation, where we want precise localization, rather than abstraction of spatial details
- two technical hurdles in DCNNs when applying to image labeling tasks
- pooling, loss of resolution: we employ the ‘atrous’ (with holes) for efficient dense computation
- spacial invariance: we use the fully connected pairwise CRF to capture fine edge details
Our approach
- treats every pixel as a CRF node
- exploits long-range dependencies
- and uses CRF inference to directly optimize a DCNN-driven cost function
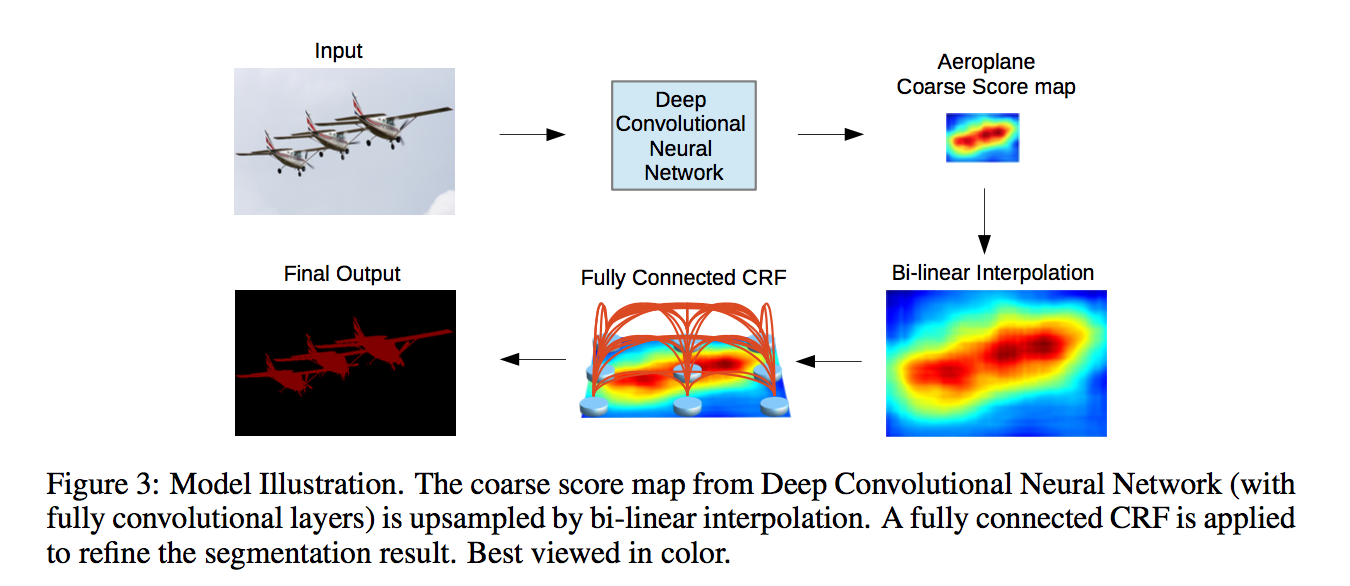
方法
structure
- fully convolutional VGG-16
- keep the first 3 subsampling blocks for a target stride of 8
- use hole algorithm conv filters for the last two blocks
- keep the pooling layers for the purpose of fine-tuing,change strides from 2 to 1
- for dense map(h/8), the first fully convolutional 7*7*4096 is computational, thus change to 4*4 / 3*3 convs
- further computation decreasement: reduce the fc channels from 4096 to 1024
train
- label:ground truth subsampled by 8
- loss function:cross-entropy
test
- x8:simply bilinear interpolation
- fcn:stride32 forces them to use learned upsampling layers, significantly increasing the complexity and training time
CRF
short-range:used to smooth noisy
fully connected model:to recover detailed local structure rather than further smooth it
energy function:
$P(x_i)$ is the bi-linear interpolated probability output of DCNN.
$k^m(f_i, f_j)$ is the Gaussian kernel depends on features (involving pixel positions & pixel color intensities)
multi-scale prediction
- to increase the boundary localization accuracy
- we attach to the input image and the output of each of the first four max pooling layers a two-layer MLP (first layer: 128 3x3 convolutional filters, second layer: 128 1x1 convolutional filters)
- the feature maps above is concatenated to the main network’s last layer feature map
- the new outputs is enhanced by 128*5=640 channels
- we only adjust the newly added weights
- introducing these extra direct connections from fine-resolution layers improves localization performance, yet the effect is not as dramatic as the one obtained with the fully-connected CRF
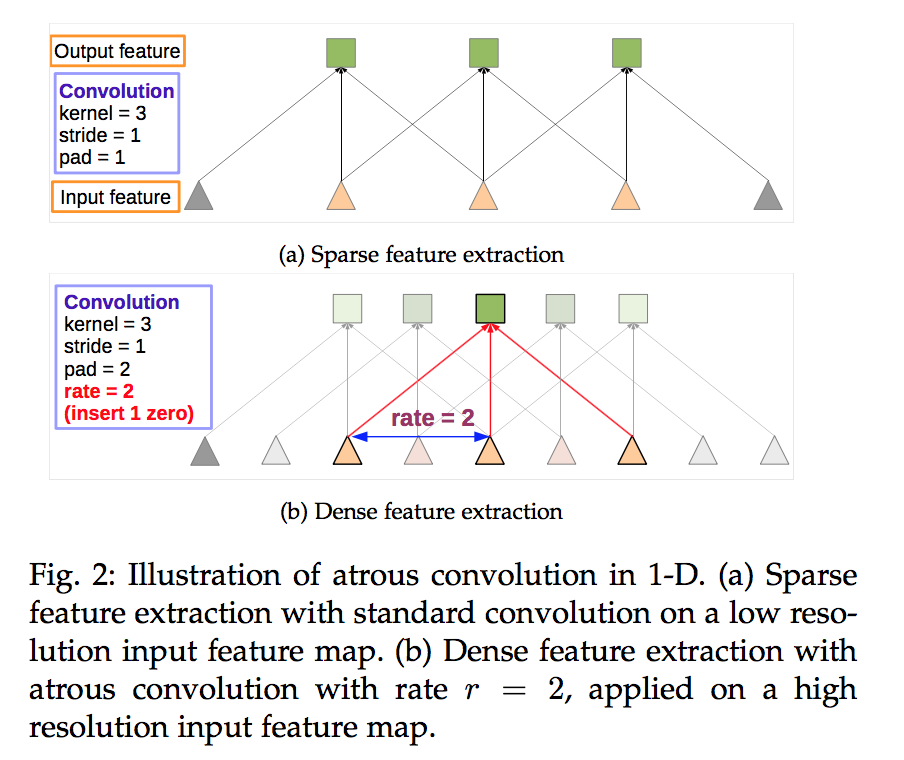
空洞卷积dilated convolution
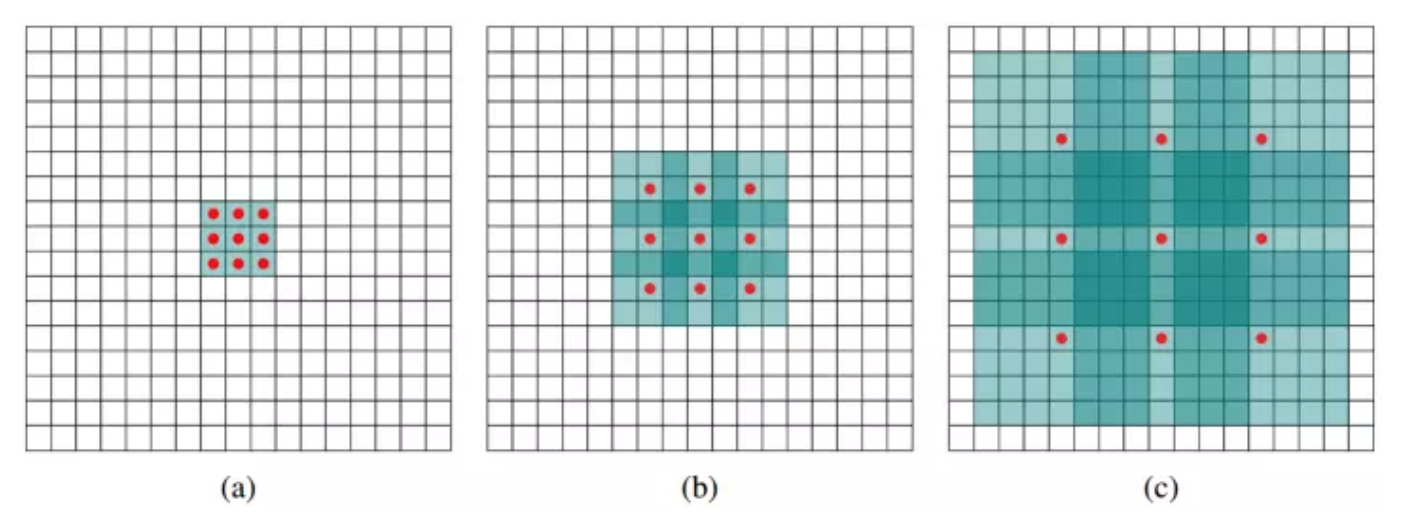
空洞卷积相比较于正常卷积,多了一个 hyper-parameter——dilation rate,指的是kernel的间隔数量(正常的convolution dilatation rate是1)
fcn:先pooling再upsampling,过程中有信息损失,能不能设计一种新的操作,不通过pooling也能有较大的感受野看到更多的信息呢?
如图(b)的2-dilated conv,kernel size只有3x3,但是这个卷积的感受野已经增大到了7x7(假设前一层是3x3的1-dilated conv)
如图(c)的4-dilated conv,kernel size只有3x3,但是这个卷积的感受野已经增大到了15x15(假设前两层是3x3的1-dilated conv和3x3的2-dilated conv)
而传统的三个3x3的1-dilated conv堆叠,只能达到7x7的感受野
dilated使得在不做pooling损失信息的情况下,加大了感受野,让每个卷积输出都包含较大范围的信息
The Gridding Effect:如下图,多次叠加3x3的2-dilated conv,会发现我们将愿输入离散化了。因此叠加卷积的 dilation rate 不能有大于1的公约数。
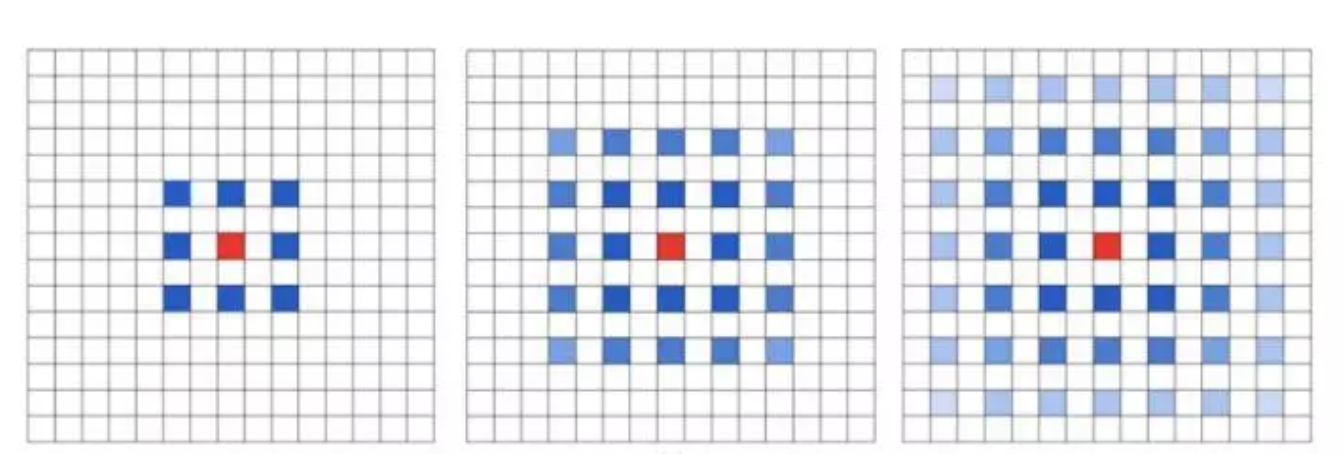
Long-ranged information:增大dilation rate对大物体有效果,对小物体可能有弊无利
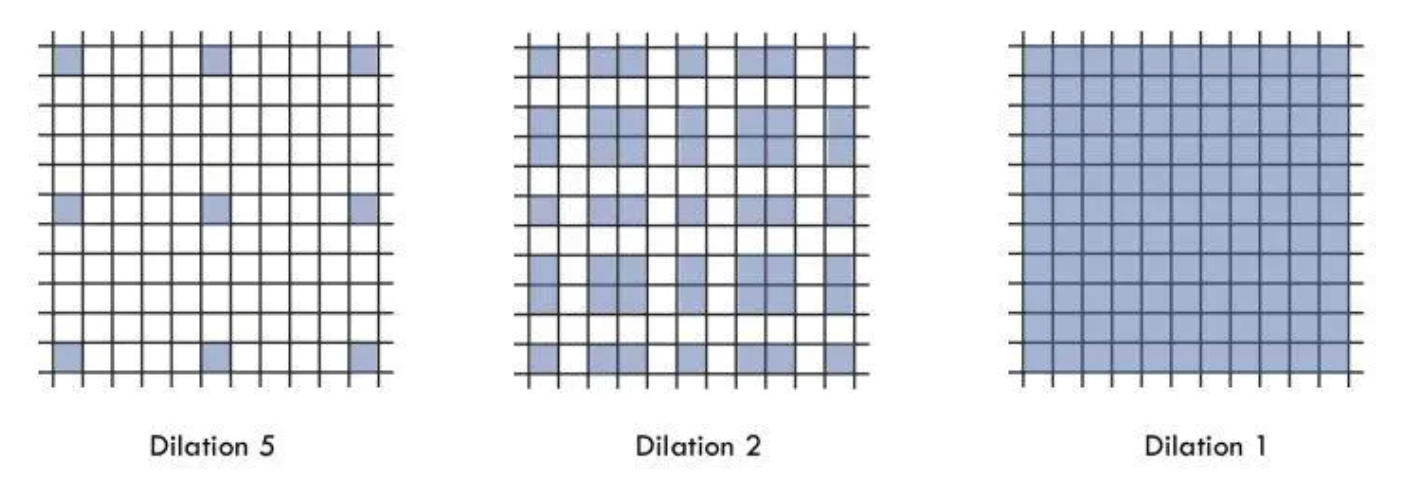
HDC(Hybrid Dilated Convolution)设计结构
叠加卷积的 dilation rate 不能有大于1的公约数,如[2,4,6]
将 dilation rate 设计成锯齿状结构,例如 [1, 2, 5, 1, 2, 5] 循环结构,锯齿状能够同时满足小物体大物体的分割要求(小 dilation rate 来关心近距离信息,大 dilation rate 来关心远距离信息)
满足$M_i = max [M_{i+1}-2r_i, M_{i+1}-2(M_{i+1}-r_i), r_i]$,$M_i$是第i层最大dilation rate
一个可行方案[1,2,5]:
deeplabV2: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs
动机
- atrous convolution:control the resolution
- atrous spatial pyramid pooling (ASPP) :multiple sampling rates
- fully connected Conditional Random Field (CRF)
论点
three challenges in the application of DCNNs to semantic image segmentation
- reduced feature resolution:max-pooling and downsampling (‘striding’) —> atrous convolution
- existence of objects at multiple scales:multi input scale —> ASPP
- reduced localization accuracy due to DCNN invariance:skip-layers —> CRF
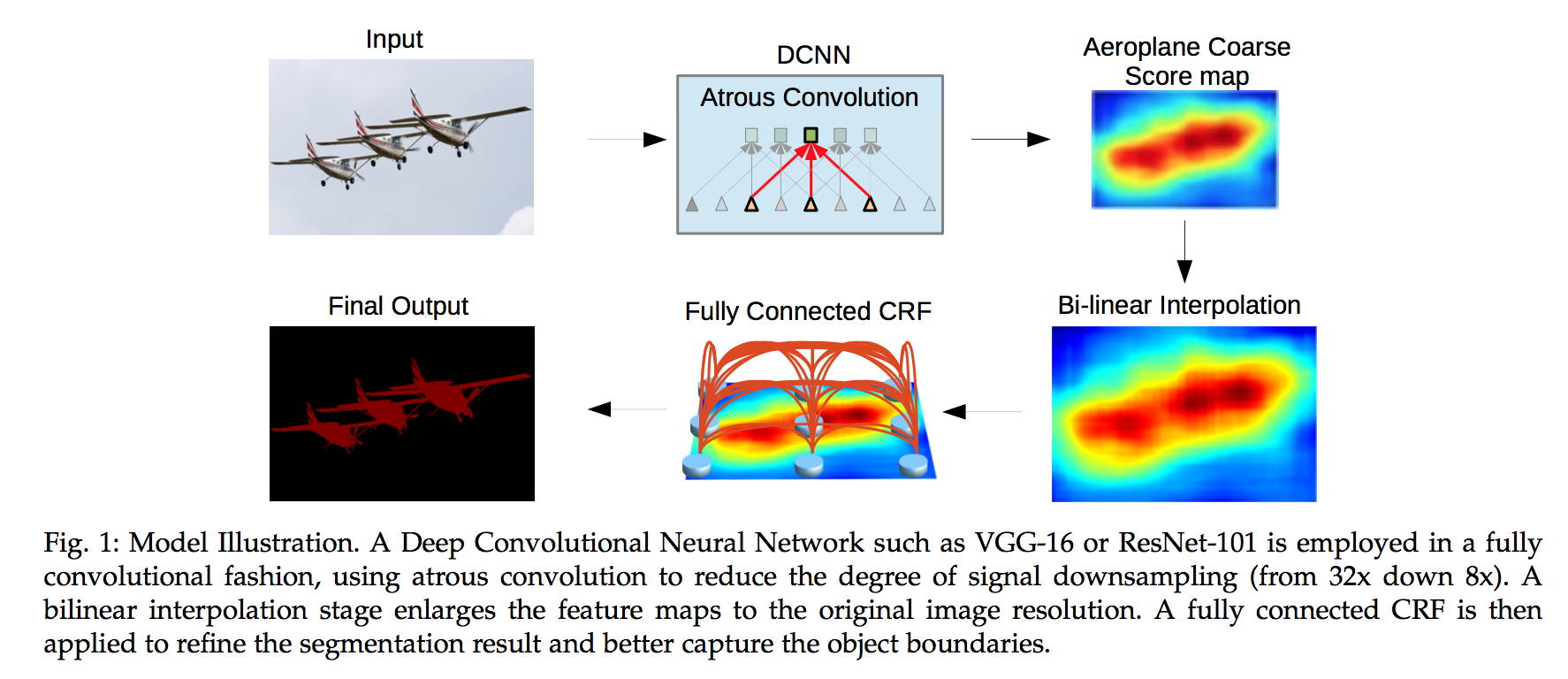
improvements compared to its first version
- better segment objects at multiple scales
- ResNet replaces VGG16
- a more comprehensive experimental evaluation on models & dataset
- related works
- jointly learning of the DCNN and CRF to form an end-to-end trainable feed-forward network
- while in our work still a 2 stage process
- use a series of atrous convolutional layers with increasing rates to aggregate multiscale context
- while in our structure using parallel instead of serial
方法
atrous convolution
- 在下采样以后的特征图上,运行普通卷积,相当于在原图上运行上采样的filter
- 1-D示意图上可以看出,两者感受野相同
- 同时能保持high resolution
while both the number of filter parameters and the number of operations per position stay constant

把backbone中下采样的层(pooling/conv)中的stride改成1,然后将接下来的conv层都改成2-dilated conv:could allow us to compute feature responses at the original image resolution
- efficiency/accuracy trade-off:using atrous convolution to increase the resolution by a factor of 4
- followed by fast bilinear interpolation by a factor of 8 to the original image resolution
Bilinear interpolation is sufficient in this setting because the class score maps are quite smooth unlike FCN

Atrous convolution offers easily control of the field-of-view and finds the best trade-off between accurate localization (small field-of-view) and context assimilation (large field-of-view):大感受野,抽象融合上下文,大感受野,low-level局部信息准确
- 实现:(1)根据定义,给filter上采样,插0;(2)给feature map下采样得到k*k个reduced resolution maps,然后run orgin conv,组合位移结果
- 在下采样以后的特征图上,运行普通卷积,相当于在原图上运行上采样的filter
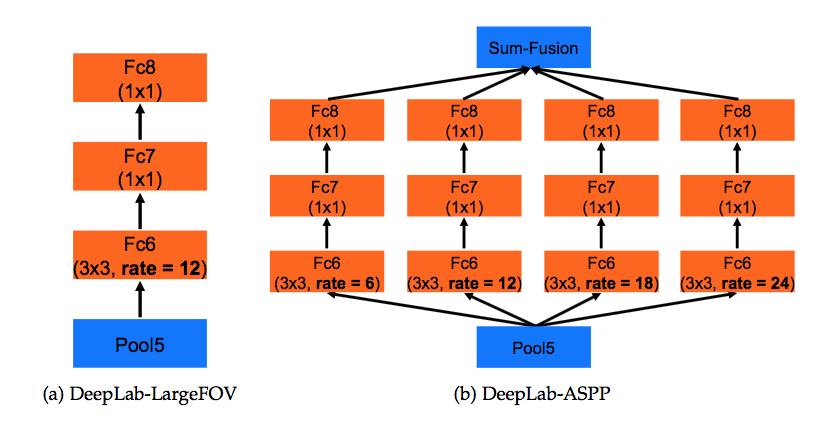
ASPP
multi input scale:
- run parallel DCNN branches that share the same parameters
- fuse by taking at each position the maximum response across scales
- computing
spatial pyramid pooling
- run multiple parallel filters with different rates
- multi-scale features are further processed in separate branches:fc7&fc8
fuse:sum fusion
CRF:keep the same as V1
deeplabV3: Rethinking Atrous Convolution for Semantic Image Segmentation
动机
- for segmenting objects at multiple scales
- employ atrous convolution in cascade or in parallel with multiple atrous rates
- augment ASPP with image-level features encoding global context and further boost performance
- without DenseCRF
- for segmenting objects at multiple scales
论点
- our proposed module consists of atrous convolution with various rates and batch normalization layers
- modules in cascade or in parallel:when applying a 3*3 atrous convolution with an extremely large rate, it fails to capture long range information due to image boundary effects
方法
Atrous Convolution
for each location $i$ on the output $y$ and a filter $w$, an $r$-rate atrous convolution is applied over the input feature map $x$:
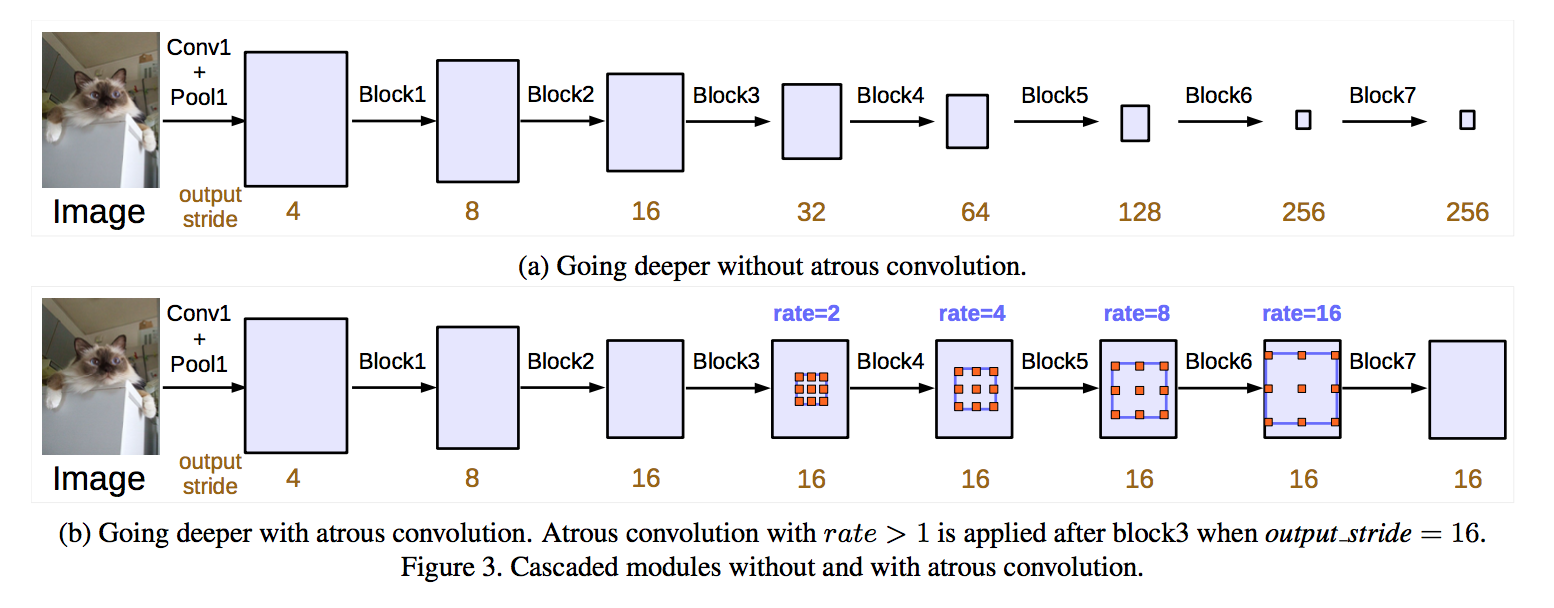
in cascade
- duplicate several copies of the last ResNet block (block4)
extra block5, block6, block7 as replicas of block4
multi-rates
ASPP
we include batch normalization within ASPP
as the sampling rate becomes larger, the number of valid filter weights becomes smaller (beyond boundary)
to incorporate global context information:we adopt image-level features by GAP on the last feature map of the model
GAP —> 1*1*256 conv —> BN —> bilinearly upsample
fusion: concatenated + 1*1 conv
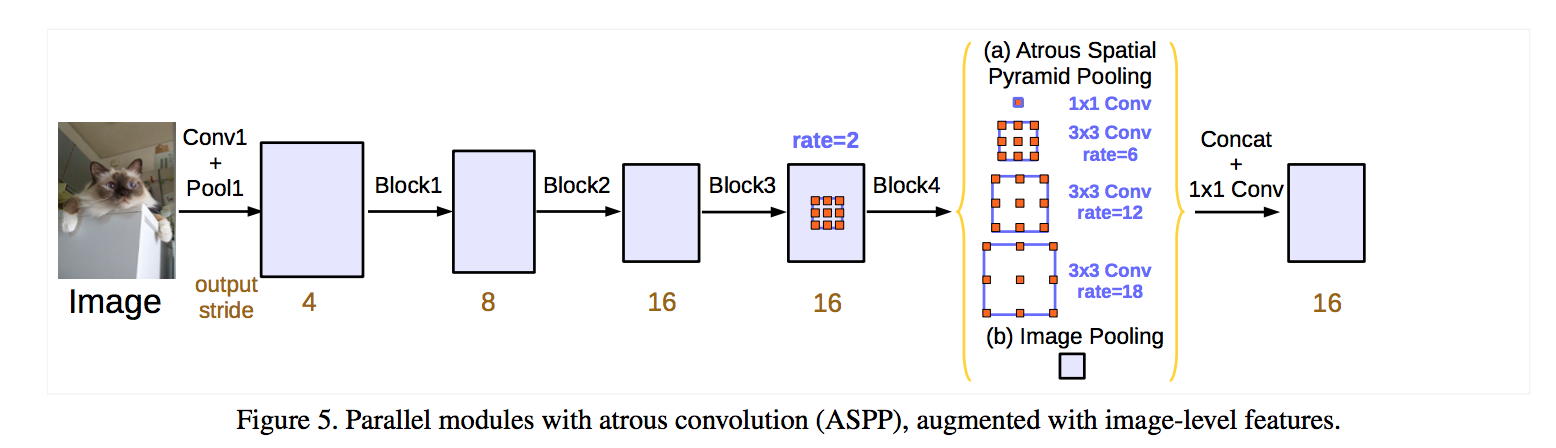
seg:final 1*1*n_classes conv
training details
- large crop size required to make sure the large atrous rates effective
- upsample the output: it is important to keep the groundtruths intact and instead upsample the final logits
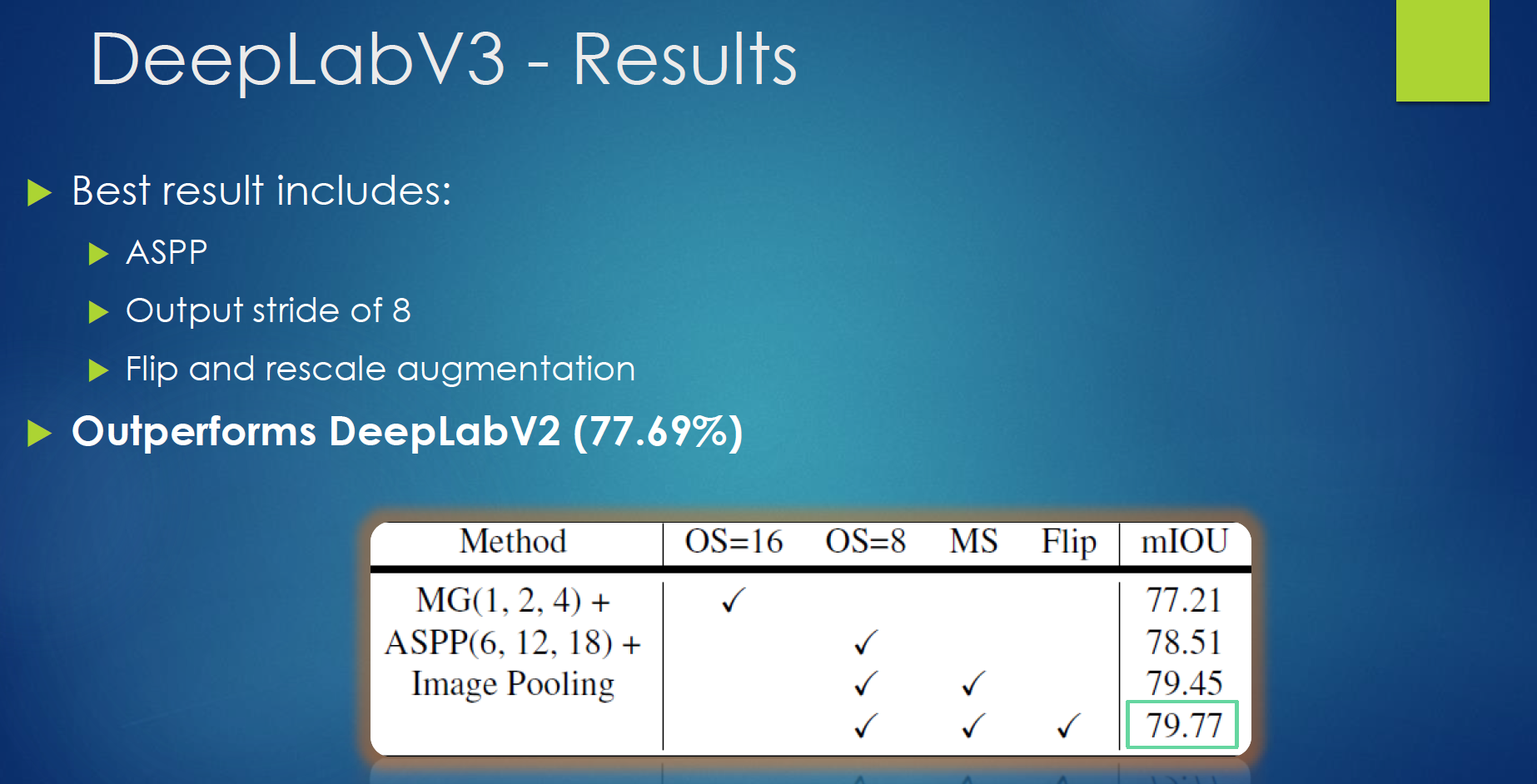
结论
output stride=8 好过16,但是运算速度慢了几倍
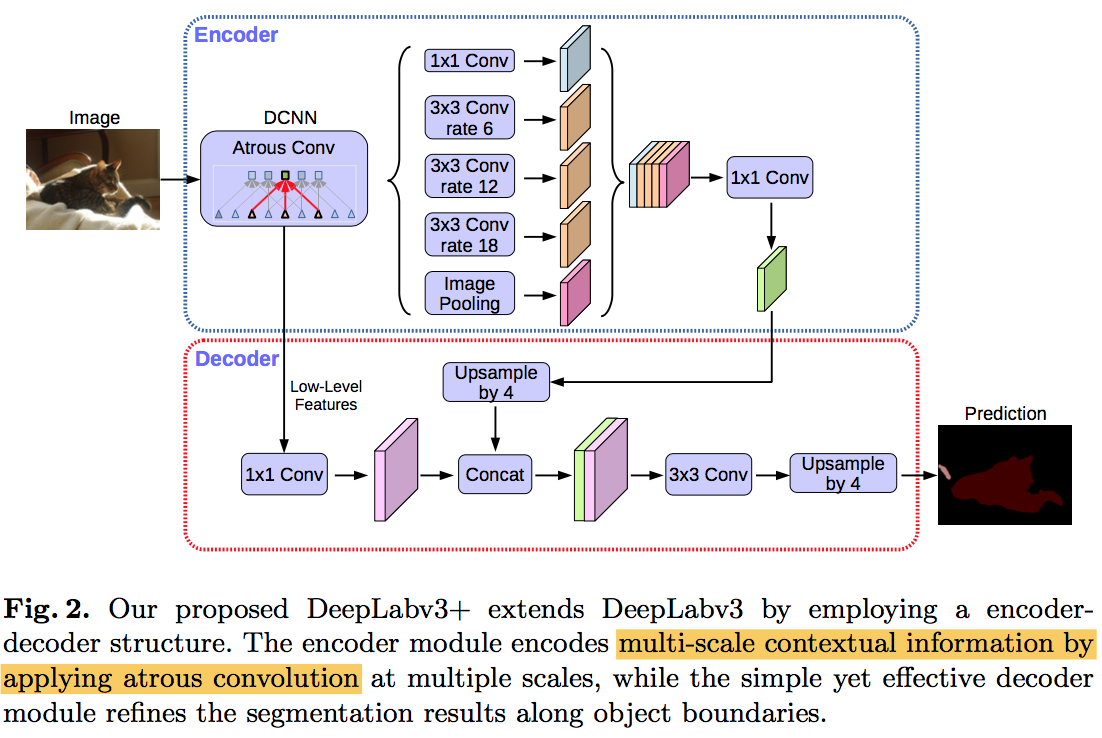
deeplabV3+: Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
动机
- spatial pyramid pooling module captures rich contextual information
- encode-decoder structure captures sharp object boundaries
- combine the above two methods
- propose a simple yet effective decoder module
- explore Xception backbone
论点
- even though rich semantic information is encoded through ASPP, detailed information related to object boundaries is missing due to striding operations
- atrous convolution could alleviate but suffer the computational balance
- while encoder-decoder models lend themselves to faster computation (since no features are dilated) in the encoder path and gradually recover sharp object boundaries in the decoder path
所谓encoder-decoder structure,就是通过encoder和decoder之间的短连接来将不同尺度的特征集成起来,增加这样的shortcut,同时增大网络的下采样率(encoder path上不使用空洞卷积,因此为了达到同样的感受野,得增加pooling,然后保留最底端的ASPP block),既减少了计算,又enrich了local border这种细节特征

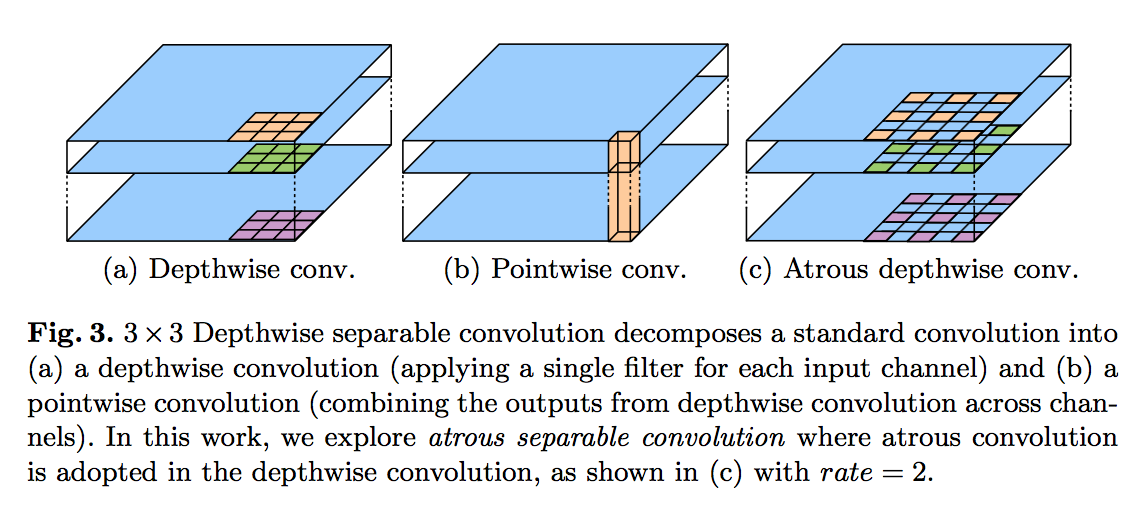
applying the atrous separable convolution to both the ASPP and decoder modules:最后又引入可分离卷积,进一步提升计算效率
方法
atrous separable convolution
significantly reduces the computation complexity while maintaining similar (or better) performance
DeepLabv3 as encoder
- output_stride=16/8:remove the striding of the last 1/2 blocks
- atrous convolution:apply atrous convolution to the blocks without striding
- ASPP:run 1x1 conv in the end to set the output channel to 256
proposed decoder
- naive decoder:bilinearly upsampled by 16
- proposed:first bilinearly upsampled by 4, then concatenated with the corresponding low-level features
- low-level features:
- apply 1x1 conv on the low-level features to reduce the number of channels to avoid outweigh the importance
- the last feature map in res2x residual block before striding
- combined features:apply 3x3 conv(2 layers, 256 channels) to obtain sharper segmentation results
- more shortcut:observed no significant improvement
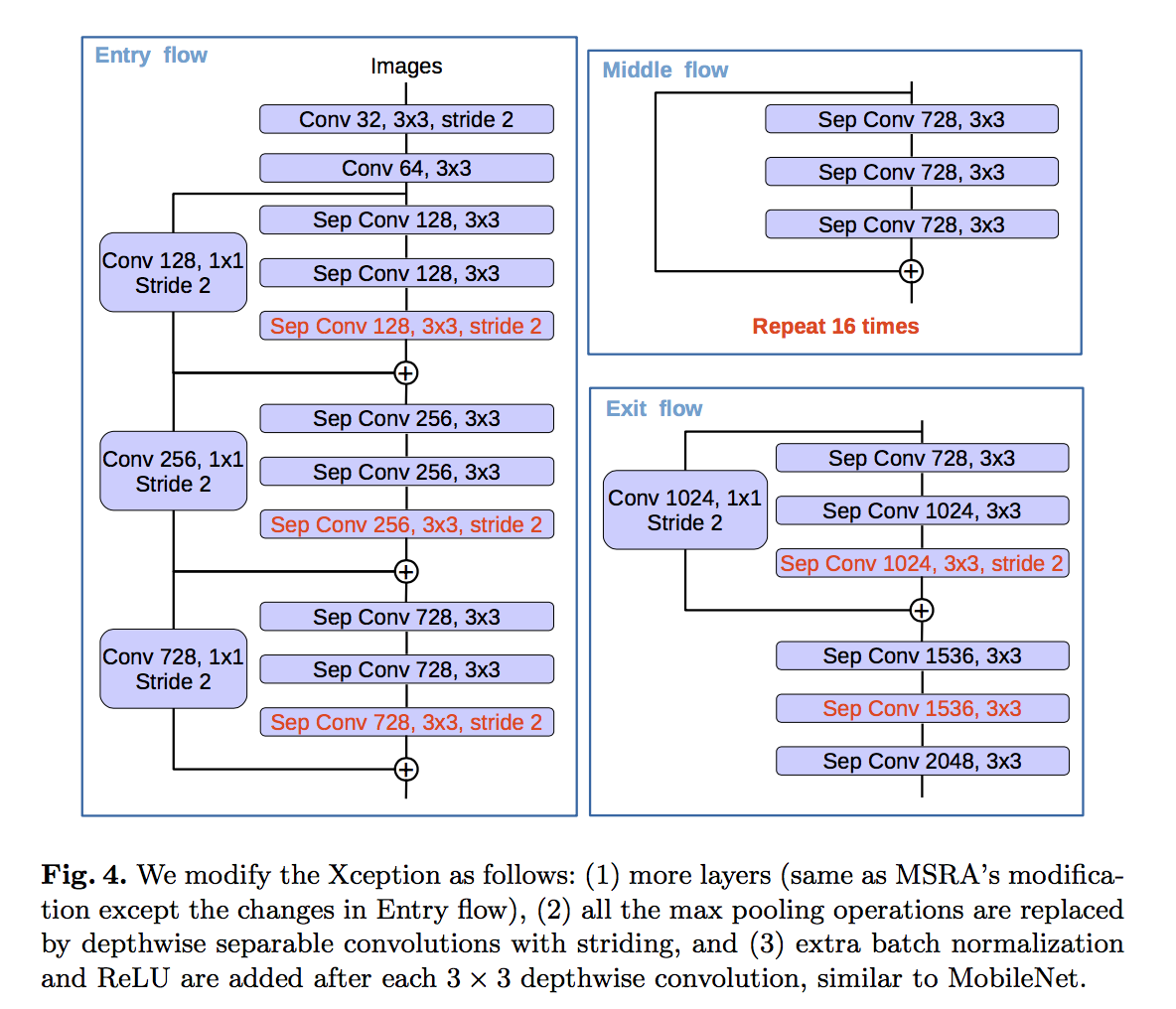
modified Xception backbone
- deeper
- all the max pooling operations are replaced with depthwise separable convolutions with striding
DWconv-BN-ReLU-PWconv-BN-ReLU
实验
decoder effect on border

f