1. Visualizing and Understanding Convolutional Networks
动机
- give insight into the internal operation and behavior of the complex models
- then one can design better models
- reveal which parts of the scene in image are important for classification
- explore the generalization ability of the model to other datasets
论点
most visualizing methods limited to the 1st layer where projections to pixel space are possible
Our approach propose a method that could projects high level feature maps to the pixel space
* some methods give some insight into invariances basing on a simple quadratic approximation
* Our approach, by contrast, provides a non-parametric view of invariance
* some methods associate patches that responsible for strong activations at higher layers
* In our approach they are not just crops of input images, but rather top-down projections that reveal structures
方法
3.1 Deconvnet: use deconvnet to project the feature activations back to the input pixel space
- To examine a given convnet activation, we set all other activations in the layer to zero and pass the feature maps as input to the attached deconvnet layer
- Then successively (i) unpool, (ii) rectify and (iii) filter to reconstruct the activity of the layer beneath until the input pixel space is reached
- 【Unpooling】using switches
- 【Rectification】the convnet uses relu to ensure always positive, same for back projection
- 【Filtering】transposed conv
Due to unpooling, the reconstruction obtained from a single activation resembles a small piece of the original input image
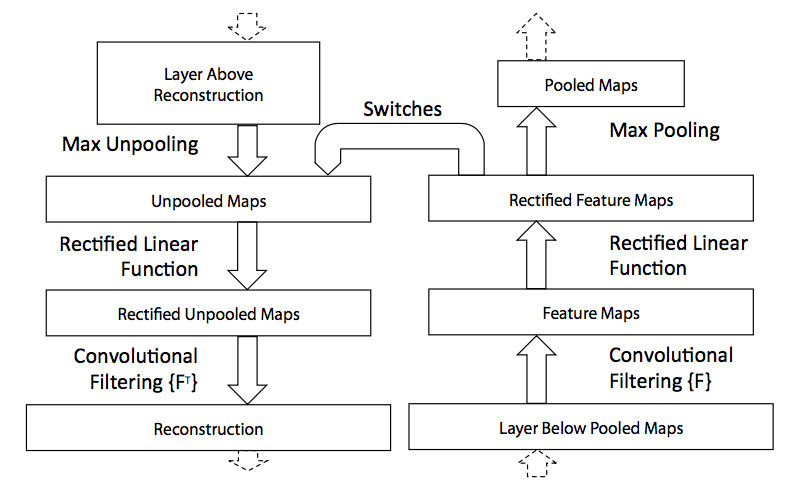
3.2 CNN model
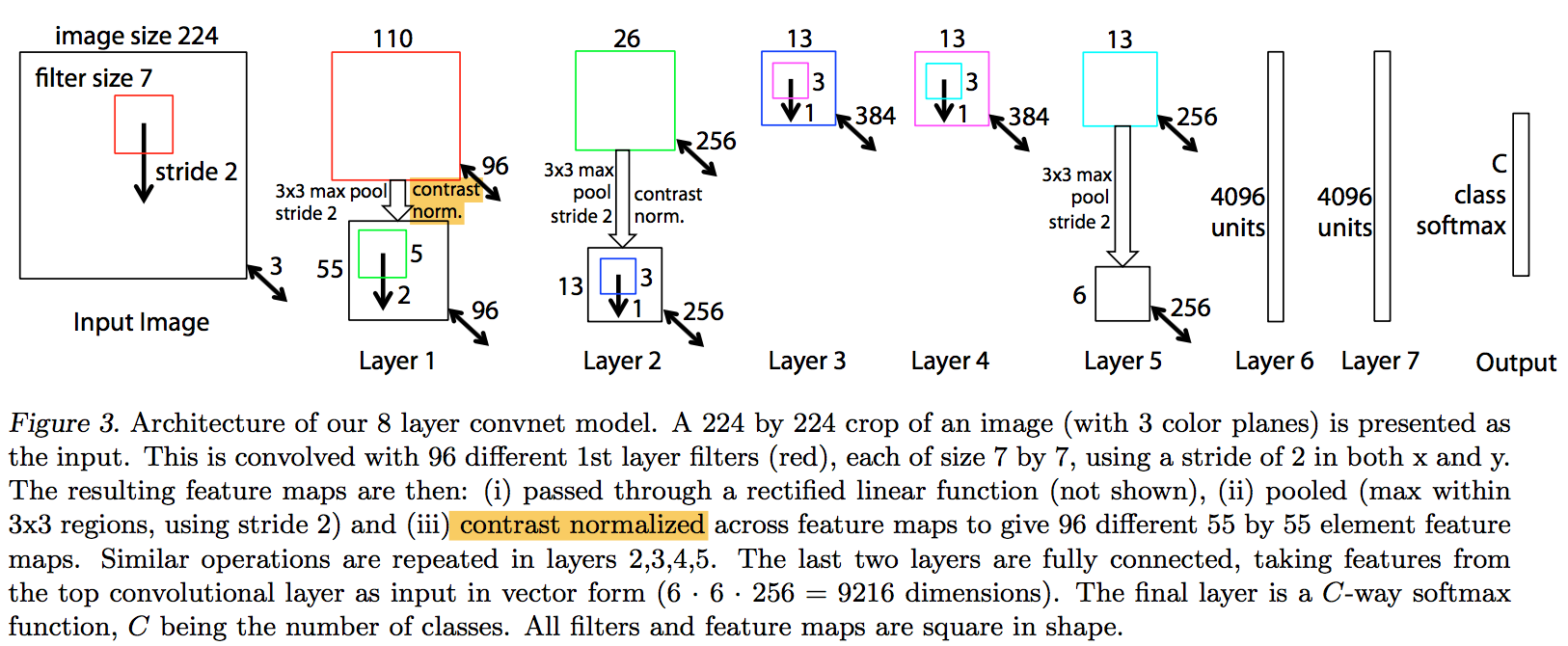
3.3 visualization among layers
for each layer, we take the top9 strongest activation across the validation data
- calculate the back projection separately
alongside we provide the corresponding image patches
3.4 visualization during training
randomly choose several strongest activation of a given feature map
lower layers converge fast, higher layers conversely
3.5 visualizing the Feature Invariance
5 sample images being translated, rotated and scaled by varying degrees
- Small transformations have a dramatic effect in the first layer of the model(c2 & c3对比)
the network is stable to translations and scalings, but not invariant to rotation
3.6 architecture selection
old architecture(stride4, filterSize11):The first layer filters are a mix of extremely high and low frequency information, with little coverage of the mid frequencies. The 2nd layer visualization shows aliasing artifacts caused by the large stride 4 used in the 1st layer convolutions. (这点可以参考之前vnet中提到的,deconv导致的棋盘格伪影,大stride会更明显)
smaller stride & smaller filter(stride2, filterSize7):more coverage of mid frequencies, no aliasing, no dead feature
3.7
对于物体的关键部分遮挡之后会极大的影响分类结果
- 第二个和第三个例子中分别是文字和人脸的响应更高,但是却不是关键部分。
理解
4.1 总的来说,网络学习到的特征,是具有辨别性的特征,通过可视化就可以看到我们提取到的特征忽视了背景,而是把关键的信息给提取出来了。从layer 1、layer 2学习到的特征基本上是颜色、边缘等低层特征;layer 3则开始稍微变得复杂,学习到的是纹理特征,比如上面的一些网格纹理;layer 4学习到的则是较多的类别信息,比如狗头;layer 5对应着更强的不变性,可以包含物体的整体信息。。
4.2 在网络迭代的过程中,特征图出现了sudden jumps。低层在训练的过程中基本没啥变化,比较容易收敛,高层的特征学习则变化很大。这解释了低层网络的从训练开始,基本上没有太大的变化,因为梯度弥散。高层网络刚开始几次的迭代,变化不是很大,但是到了40~50的迭代的时候,变化很大,因此我们以后在训练网络的时候,不要着急看结果,看结果需要保证网络收敛。
4.3 图像的平移、缩放、旋转,可以看出第一层中对于图像变化非常敏感,第7层就接近于线性变化。
2. Striving for Simplicity: The All Convolutional Net
动机
- traditional pipeline: alternating convolution and max-pooling layers followed by a small number of fully connected layers
- questioning the necessity of different components in the pipeline, max-pooling layer to be specified
- to analyze the network we introduce a new variant of the “deconvolution approach” for visualizing features
论点
- two major improving directions based on traditional pipeline
- using more complex activation functions
- building multiple conv modules
- we study the most simple architecture we could conceive
- a homogeneous network solely consisting of convolutional layers
- without the need for complicated activation functions, any response normalization or max-pooling
- reaches state of the art performance
- two major improving directions based on traditional pipeline
方法
replace the pooling layers with standard convolutional layers with stride two
- the spatial dimensionality reduction performed by pooling makes covering larger parts of the input in higher layers possible
- which is crucial for achieving good performance with CNNs
make use of small convolutional layers
- greatly reduce the number of parameters in a network and thus serve as a form of regularization
- if the topmost convolutional layer covers a portion of the image large enough to recognize its content then fully connected layers can also be replaced by simple 1-by-1 convolutions
the overall architecture consists only of convolutional layers with rectified linear non-linearities and an averaging + softmax layer to produce predictions
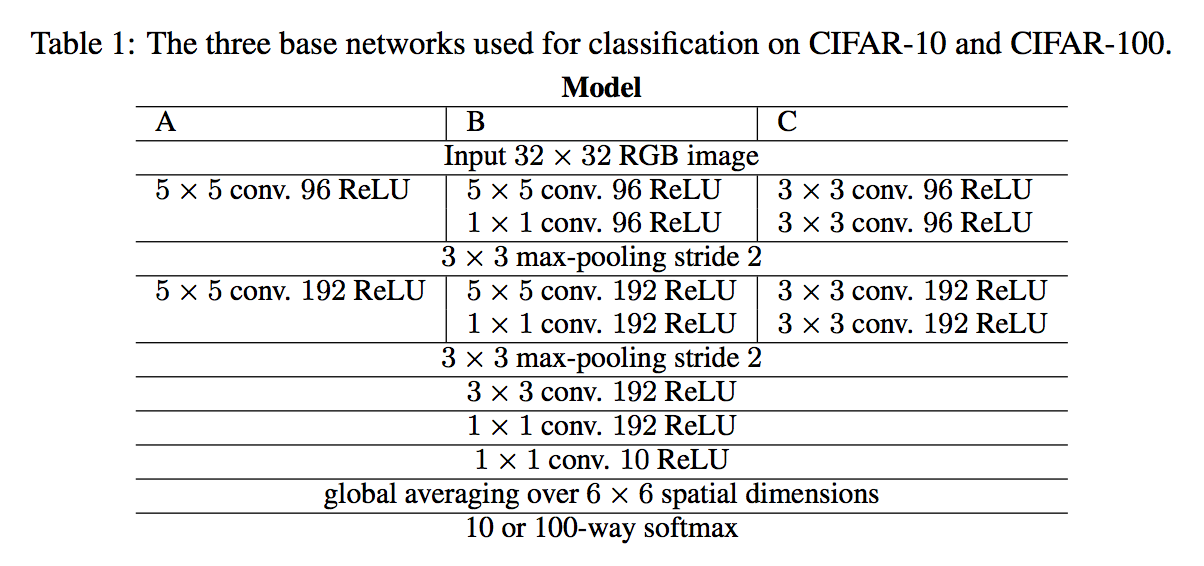

- Strided-CNN-C: pooling is removed and the preceded conv stride is increase
- ConvPool-CNN-C: a dense conv is placed, to show the effect of increasing parameters
- All-CNN-C: max-pooling is replaced by conv
- when pooling is replaced by an additional convolution layer with stride 2, performance stabilizes and even improves
- small 3 × 3 convolutions stacked after each other seem to be enough to achieve the best performance
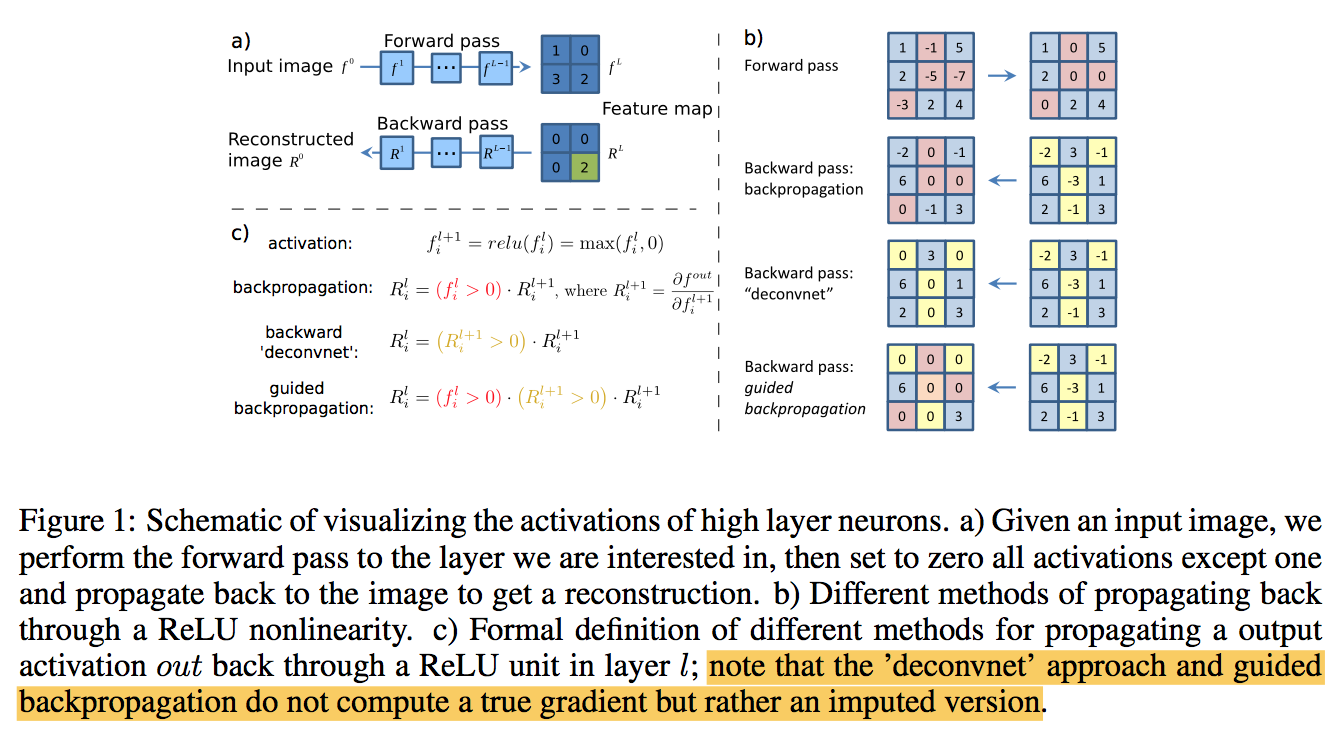
guided backpropagation
- the paper above proposed ‘deconvnet’, which we observe that it does not always work well without max-pooling layers
- For higher layers of our network the method of Zeiler and Fergus fails to produce sharp, recognizable image structure
- Our architecture does not include max-pooling, thus we can ’deconvolve’ without switches, i.e. not conditioning on an input image
In order to obtain a reconstruction conditioned on an input image from our network without pooling layers we to combine the simple backward pass and the deconvnet
Interestingly, the very first layer of the network does not learn the usual Gabor filters, but higher layers do

3. Cam: Learning Deep Features for Discriminative Localization
动机
- we found that CNNs actually behave as object detectors despite no supervision on the location
- this ability is lost when fully-connected layers are used for classification
- we found that the advantages of global average pooling layers are beyond simply acting as a regularizer
- it makes it easily to localize the discriminative image regions despite not being trained for them
论点
2.1 Weakly-supervised object localization
- previous methods are not trained end-to-end and require multiple forward passes
Our approach is trained end-to-end and can localize objects in a single forward pass
2.2 Visualizing CNNs
previous methods only analyze the convolutional layers, ignoring the fully connected thereby painting an incomplete picture of the full story
- we are able to understand our network from the beginning to the end
方法
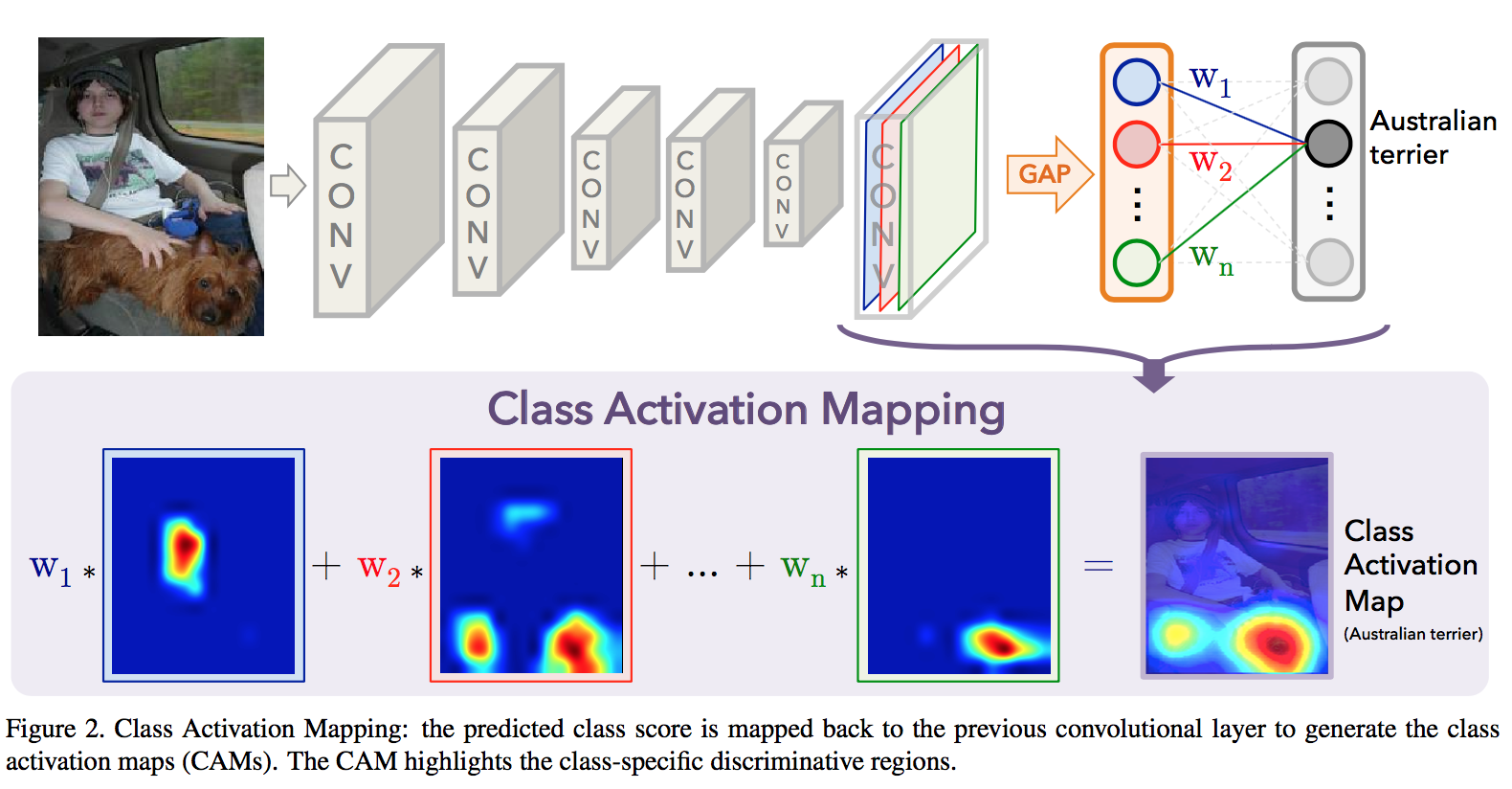
3.1 Class Activation Mapping
- A class activation map for a particular category indicates the discriminative image regions used by the network to identify that category
- the network architecture: convs—-gap—-fc+softmax
- we can identify the importance of the image regions by projecting back the weights of the output layer on to the convolutional feature maps
by simply upsampling the class activation map to the size of the input image we can identify the image regions most relevant to the particular category
3.2 Weakly-supervised Object Localization
our technique does not adversely impact the classification performance when learning to localize
- we found that the localization ability of the networks improved when the last convolutional layer before GAP had a higher spatial resolution, thus we removed several convolutional layers from the origin networks
- overall we find that the classification performance is largely preserved for our GAP networks compared with the origin fc structure
- our CAM approach significantly outperforms the backpropagation approach on generating bounding box
low mapping resolution prevents the network from obtaining accurate localizations
3.3 Visualizing Class-Specific Units
the convolutional units of various layers of CNNs act as visual concept detec- tors, identifying low-level concepts like textures or mate- rials, to high-level concepts like objects or scenes
- Deeper into the network, the units become increasingly discriminative
- given the fully-connected layers in many networks, it can be difficult to identify the importance of different units for identifying different categories
4. Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization
5. Grad-CAM++: Improved Visual Explanations for Deep Convolutional Networks
6. 综述
GAP
首先回顾一下GAP,NiN中提出了GAP,主要为了解决全连接层参数过多,不易训练且容易过拟合等问题。
对大多数分类任务来说不会因为做了gap让特征变少而让模型性能下降。因为GAP层是一个非线性操作层,这C个特征相当于是从kxkxC经过非线性变化选择出来的强特征。
heatmap
step1. 图像经过卷积网络后最后得到的特征图,在全连接层分类的权重($w_{k,n}$)肯定不同,
step2. 利用反向传播求出每张特征图的权重,
step3. 用每张特征图乘以权重得到带权重的特征图,在第三维求均值,relu激活,归一化处理
- relu只保留wx大于0的值——我们正响应是对当前类别有用的特征,负响应会拉低$\sum wx$,即会降低当前类别的置信度
如果没有relu,定位图谱显示的不仅仅是某一类的特征。而是所有类别的特征。
step4. 将特征图resize到原图尺寸,便于叠加显示
CAM
CAM要求必须使用GAP层,
CAM选择softmax层值最大的节点反向传播,求GAP层的梯度作为特征图的权重,每个GAP的节点对应一张特征图。
Grad-CAM
Grad-CAM不需要限制模型结构,
Grad-CAM选择softmax层值最大的节点反向传播,对最后一层卷积层求梯度,用每张特征图的梯度的均值作为该特征图的权重。