Network In Network
动机
- enhance model discriminability(获得更好的特征描述):propose mlpconv
- less prone to overfitting:propose global average pooling
论点
comparison 1:
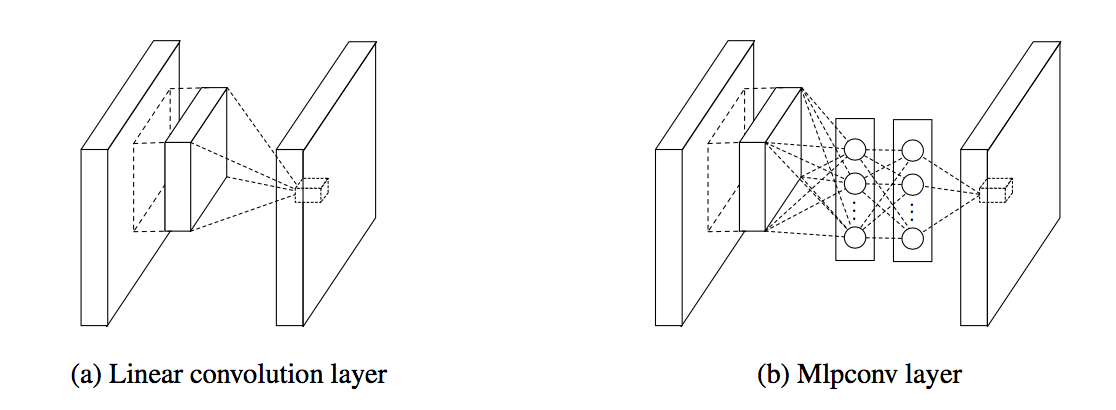
- conventional CNN uses linear filter, which implicitly makes the assumption that the latent concepts are linearly separable.
- traditional CNN is stacking [linear filters+nonlinear activation/linear+maxpooling+nonlinear]:这里引出了一个激活函数和池化层先后顺序的问题,对于avg_poolling,两种操作得到的结果是不一样的,先接激活函数会丢失部分信息,所以应该先池化再激活,对于MAX_pooling,两种操作结果一样,但是先池化下采样,可以减少激活函数的计算量,总结就是先池化再激活。但是好多网络实际实现上都是relu紧跟着conv,后面接pooling,这样比较interpretable——cross feature map pooling
mlpconv layer can be regarded as a highly nonlinear function(filter-fc-activation-fc-activation-fc-activation…)
comparison 2:
maxout network imposes the prior that instances of a latent concept lie within a convex set in the input space【QUESTION HERE】
mlpconv layer is a universal function approximator instead of a convex function approximator
comparison 3:
fully connected layers are prone to overfitting and heavily depend on dropout regularization
- global average pooling is more meaningful and interpretable, moreover it itself is a structural regularizer【QUESTION HERE】
方法
- use mlpconv layer to replace conventional GLM(linear filters)
- use global average pooling to replace traditional fully connected layers
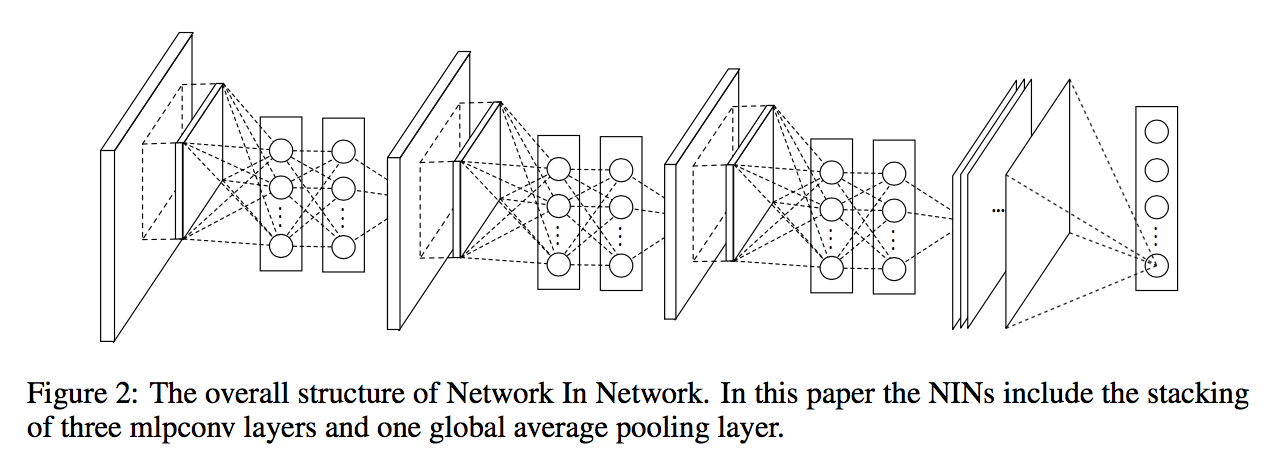
- the overall structure is a stack of mlpconv layers, on top of which lie the global average pooling and the objective cost layer
- Sub-sampling layers can be added in between the mlpconv as in CNN
- dropout is applied on the outputs of all but the last mlpconv layers for regularization
- another regularizer applied is weight decay
细节
preprocessing:global contrast normalization and ZCA whitening
augmentation:translation and horizontal flipping
GAP for conventional CNN:CNN+FC+DROPOUT < CNN+GAP < CNN+FC
- gap is effective as a regularizer
- slightly worse than the dropout regularizer result for some reason
confidence maps
- explicitly enforce feature maps in the last mlpconv layer of NIN to be confidence maps of the categories by means of global average pooling:NiN将GAP的输出直接作为output layer,因此每一个类别对应的feature map可以近似认为是 confidence map。
- the strongest activations appear roughly at the same region of the object in the original image:特征图上高响应区域基本与原图上目标区域对应。
- this motivates the possibility of performing object detection via NIN
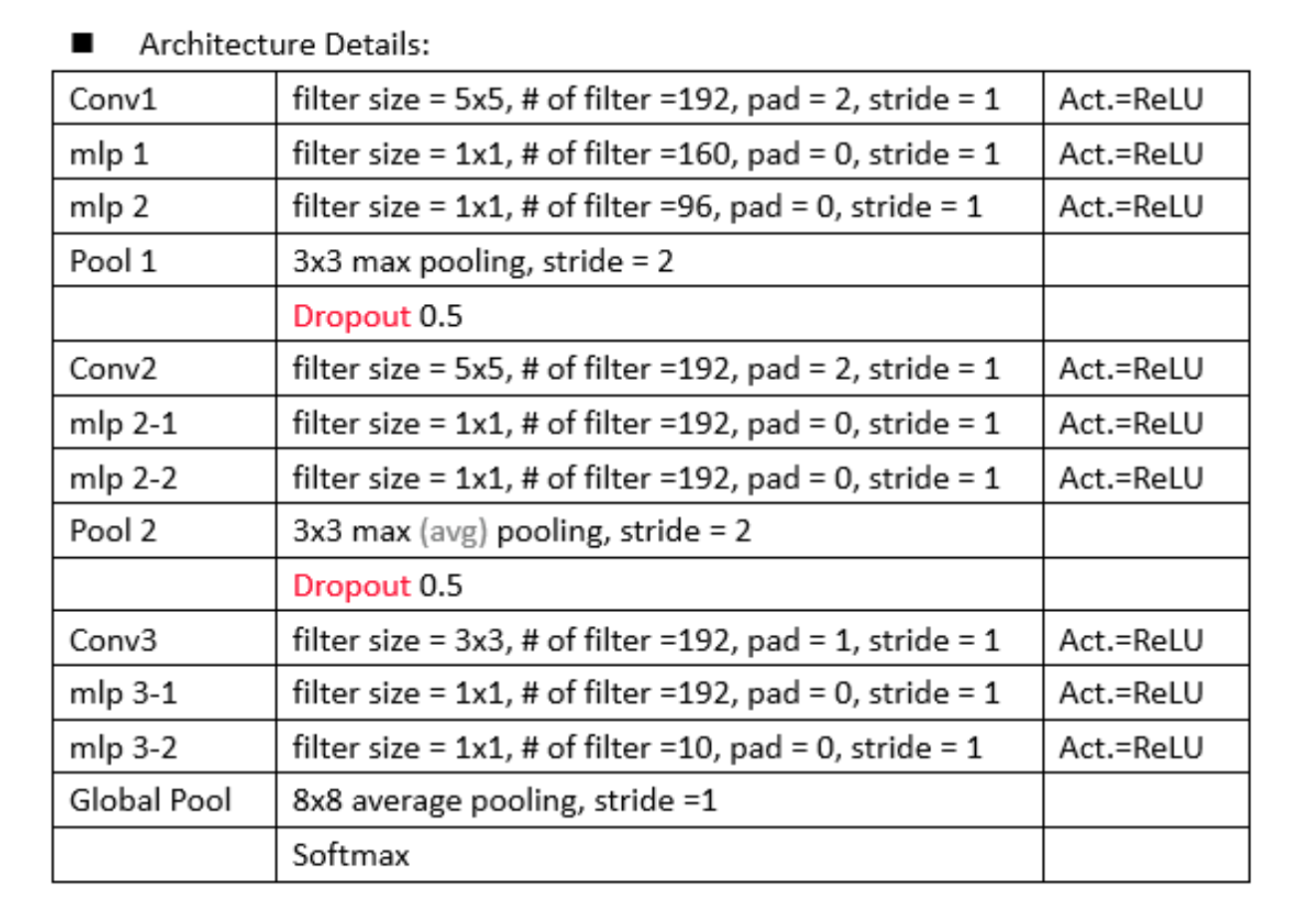
architecture:实际中多层感知器使用1x1conv来实现,增加的多层感知器相当于是一个含参的池化层,通过对多个特征图进行含参池化,再传递到下一层继续含参池化,这种级联的跨通道的含参池化让网络有了更复杂的表征能力。
总结
- mlpconv:stronger local reception unit
- gap:regularizer & bring confidence maps