类别
- 按照任务类型:度量学习(metric learning)和描述子学习(image descriptor learning)
- 按照网络结构:pairwise的siamese结构、triplet的three branch结构、以及引入尺度信息的central-surround结构
- 按照网络输出:特征向量(feature embedding)和单个概率值(pairwise similarity)
- 按照损失函数:对比损失函数、交叉熵损失函数、triplet loss、hinge loss等,此外损失函数可以带有隐式的困难样本挖掘,例如pn-net中的softpn等,也可以是显示的困难挖掘。
Plain网络
主要是说AlexNet/VGG-Net,后者更常用一些。
Plain网络的设计主要遵循以下几个准则:
(1)输出特征图尺寸相同的层使用相同数量的滤波器。
(2)如果特征图尺寸减半,那么滤波器数量就加倍,从而保证每层的时间复杂度相同(这是为啥??)。
名词
感受野:卷积神经网络每一层输出的特征图上的像素点在原始图像上映射区域的大小。通俗的说,就是输入图像对这一层输出的神经元的影响有多大。
感受野计算:由当前层向前推,需要的参数是kernel size和stride。
其中$cur_RF$是当前层(start from 1),$N_RF$、$kernel_size$、$stride$是上一层参数。
有效感受野:并不是感受野内所有像素对输出向量的贡献相同,在很多情况下感受野区域内像素的影响分布是高斯,有效感受野仅占理论感受野的一部分,且高斯分布从中心到边缘快速衰减。
感受野大小:
- 小感受野:local,位置信息更准确
- 大感受野:global,语义信息更丰富
inception module:下图为其中一种。
意义:增加网络深度和宽度的同时,减少参数。结构中嵌入了多尺度信息,集成了多种不同感受野上的特征。
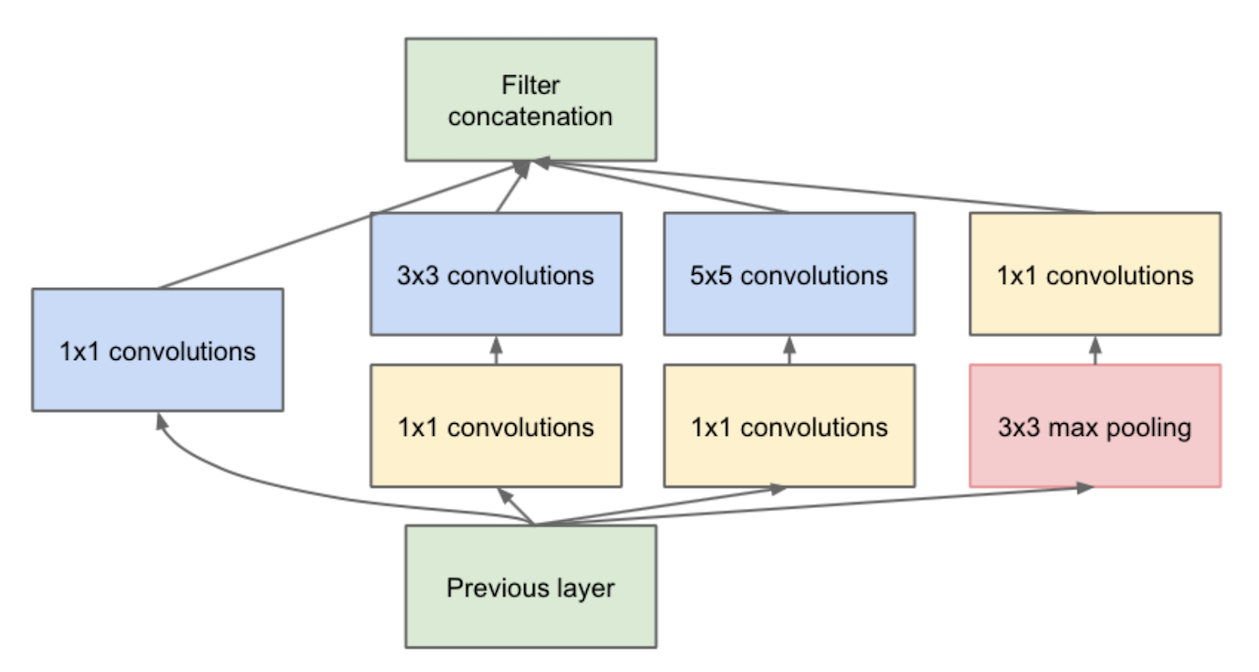
building block:左边这种,红色框框里面是一个block。
几个相同的building block堆叠为一层conv。在第一个building Block块中,输出特征图的尺寸下降一半(第一个卷积stride=2),剩余的building Block块输入输出尺寸是一样的。
bottleneck:右边这种,蓝色框框block。字面意思,瓶颈,形容输入输出维度差距较大。
第一个1*1负责降低维度,第二个1*1负责恢复维度,3*3层就处在一个输入/输出维度较小的瓶颈。
左右两种结构时间复杂度相似。 <img src="图像算法综述/block.png" width="30%;" /> <img src="图像算法综述/ImageNet.png" width="110%;" />top-1和top-5:top-1就是预测概率最大的类别,top-5则取最后预测概率的前五个,只要其中包含正确类别则认为预测正确。
使用top-5主要是因为ImageNet中很多图片中其实是包含多个物体的。
accuracy、error rate、F1-score、sensitivity、specificity、precision、recall
- accuracy:总体准确率
- precision:从结果角度,单一类别准确率
- recall:从输入角度,预测类别真实为1的准确率
- P-R曲线:选用不同阈值,precision-recall围成的曲线
- AP:平均精度,P-R曲线围住的面积
- F1-score:对于某个分类,综合了Precision和Recall的一个判断指标,因为选用不同阈值,precision-recall会随之变化,F1-score用于选出最佳阈值。
- sensitivity:=recall
- specificity:预测类别真实为0的准确率
reference:https://zhuanlan.zhihu.com/p/33273532
trade-off:
FLOPS:每秒浮点运算次数是每秒所执行的浮点运算次数的简称,被用来估算电脑效能。
ROC、AUC、MAP:
- ROC:TPR和FPR围成的曲线
- AUC:ROC围住的面积
- mAP:所有类别AP的平均值
梯度弥散:
“底层先收敛、高层再收敛”:
特征图:卷积层通过线性滤波器进行线性卷积运算,然后再接个非线性激活函数,最终生成特征图。
TTA test time augmentation:测试时增强,为原始图像造出多个不同版本,包括不同区域裁剪和更改缩放程度等,并将它们输入到模型中;然后对多个版本进行计算得到平均输出,作为图像的最终输出分数。
pooling mode:
- full mode:从filter和image刚开始相交开始卷积
- same mode:当filter的中心和image的角重合时开始卷积,如果stride=1,那么输入输出尺寸相同
- valid mode:当filter完全在image里面时开始卷积
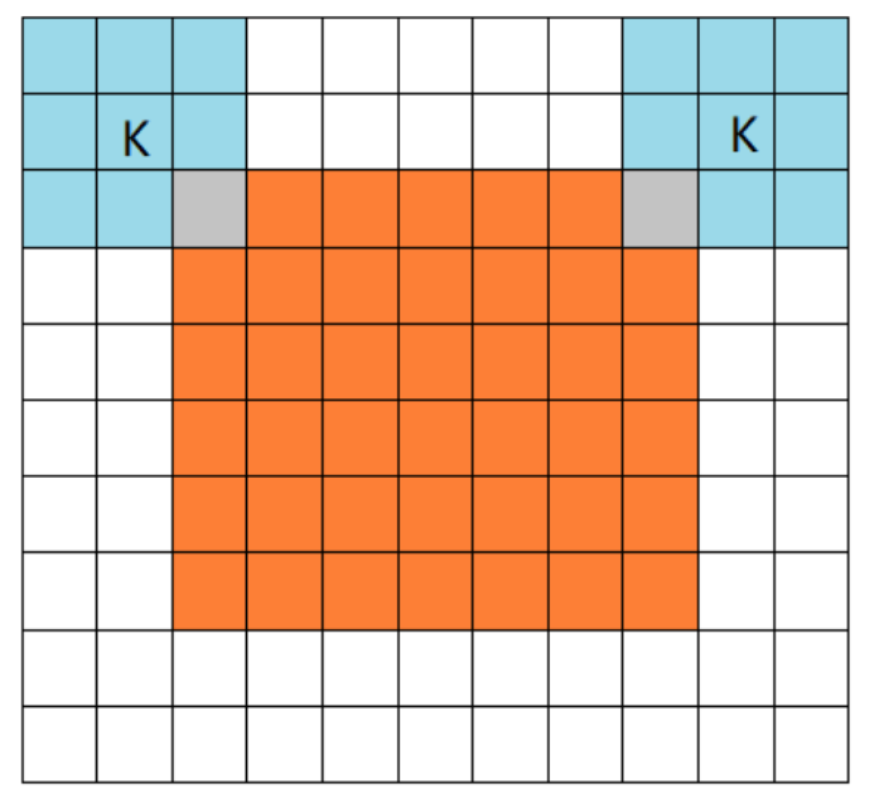
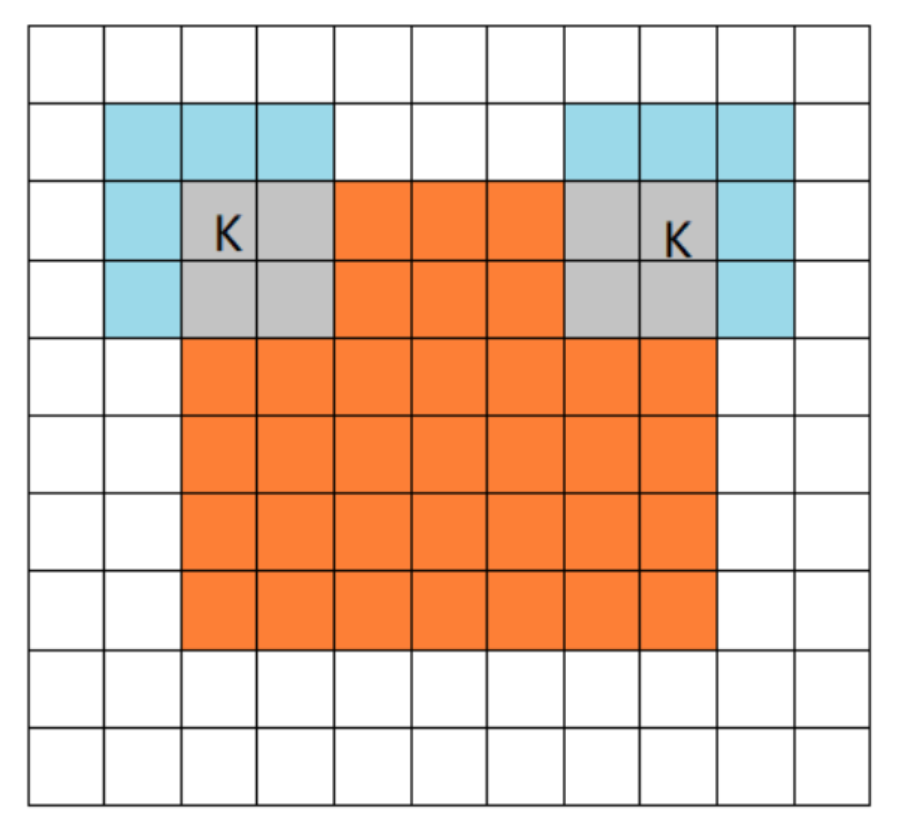
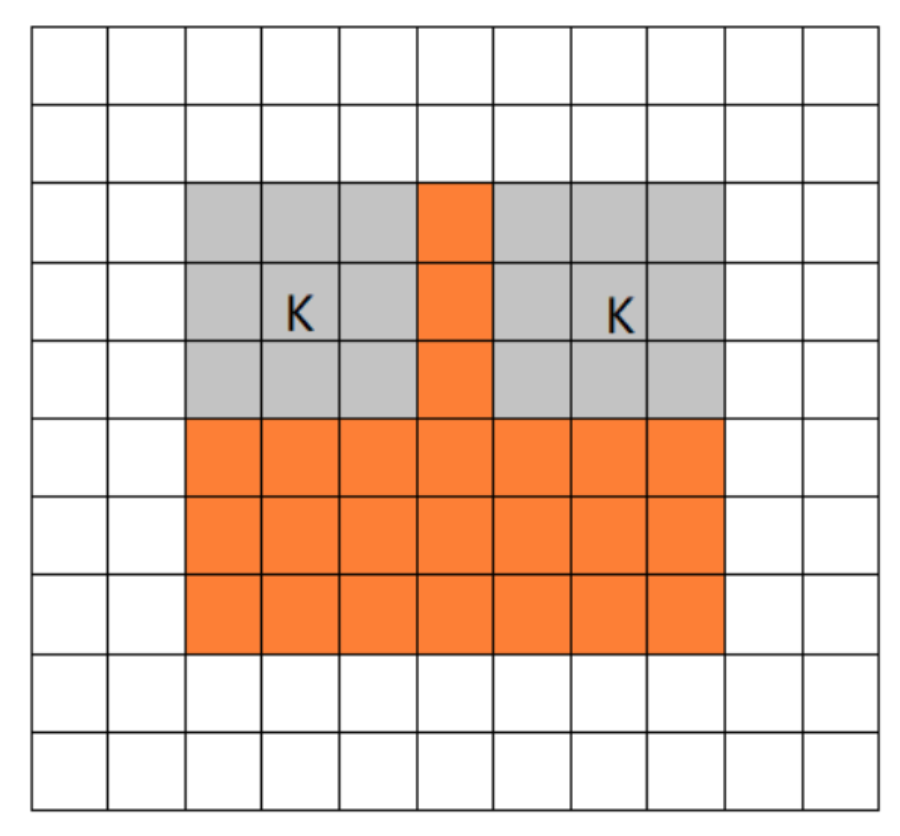
-
- 平移不变性:不管输入如何平移,系统产生完全相同的响应,比如图像分类任务,图像中的目标不管被移动到图片的哪个位置,得到的结果(标签)应该是相同的
- 平移同变性(translation equivariance):系统在不同位置的工作原理相同,但它的响应随着目标位置的变化而变化,比如实例分割任务,目标如果被平移了,那么输出的实例掩码也相应变化
- 局部连接:每个神经元没有必要对全局图像进行感知,只需要对局部进行感知,然后在更高层将局部的信息综合起来就得到了全局的信息
- 权值共享:对于这个图像上的所有位置,我们都能使用同样的学习特征
- 池化:通过消除非极大值,降低了上层的计算复杂度。最大池化返回感受野中的最大值,如果最大值被移动了,但是仍然在这个感受野中,那么池化层也仍然会输出相同的最大值。
- 卷积和池化这两种操作共同提供了一些平移不变性,即使图像被平移,卷积保证仍然能检测到它的特征,池化则尽可能地保持一致的表达。
- 同理,所谓的CNN的尺度、旋转不变性,也是由于pooling操作,引入的微小形变的鲁棒性。
模型大小与参数量:float32是4个字节,因此模型大小字节数=参数量×4
训练技巧
迁移学习:当数据集太小,无法用来训练一个足够好的神经网络,可以选择fine-tune一些预训练网络。使用时修改最后几层,降低学习率。
keras中一些预训练权重下载地址:https://github.com/fchollet/deep-learning-models/releases/
-
我们不能将全部数据集用于训练——这样就没有数据来测试模型性能了
将数据集分割为training set 和 test set,衡量结果取决于数据集划分,training set和全集之间存在bias,不同test下结果variety很大
交叉验证Cross-Validation:
- 极端情况LOOCV:全集N,每次取一个做test,其他做train,重复N次,得到N个模型,并计算N个test做平均
- K-fold:全集切分成k份,每次取一个做test,其他做train,重复k次~
- 实验显示LOOCV和10-foldCV的结果很相近,后者计算成本明显减小
- Bias-Variance Trade-Off:K越大,train set越接近全集,bias越小,但是每个train set之间相关性越大,而这种大相关性会导致最终的test error具有更大的Variance
分割
实例分割&语义分割
- instance segmentation:标记实例和语义, 不仅要分割出
人这个类, 而且要分割出这个人是谁, 也就是具体的实例 semantic segmentation:只标记语义, 也就是说只分割出
人这个类来
- instance segmentation:标记实例和语义, 不仅要分割出